Nature | AdaptiveNN: Modeling Human-Like Adaptive Perception to Break the Machine Vision “Impossible Triangle”
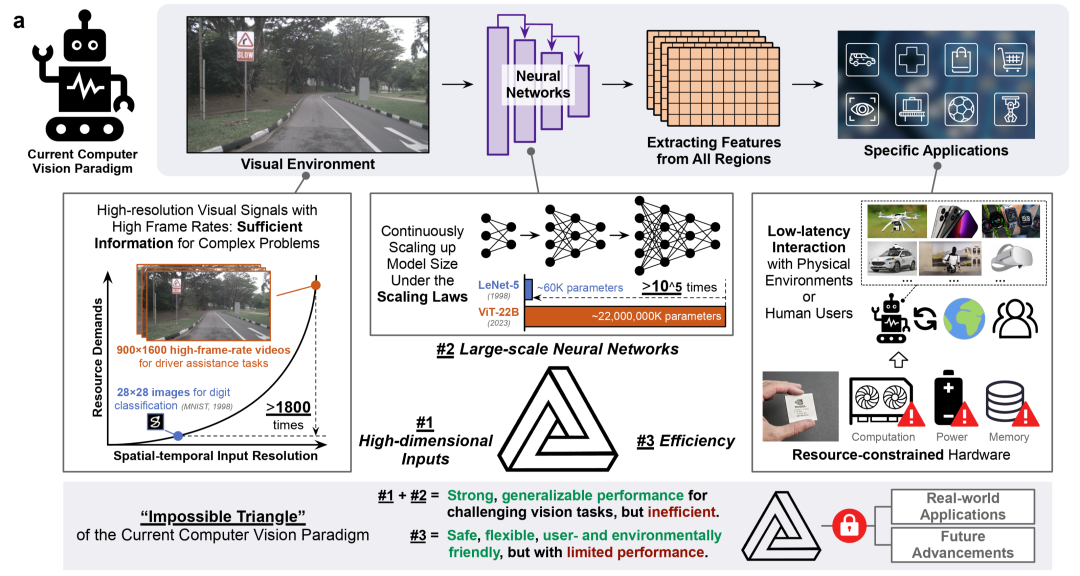
Introduction: Vision and AI
Vision is one of the most important ways humans perceive and understand the complex physical world.
Giving computers the ability for visual perception and cognition is a core research challenge in artificial intelligence — underpinning key domains such as multimodal foundation models, embodied intelligence, and medical AI.
The State of Computer Vision
Over the past decades, computer vision has reached — and in some cases surpassed — human expert-level performance in:
- Image recognition
- Object detection
- Multimodal understanding
However, in real-world deployment these highly accurate models face obstacles:
- Need to activate hundreds of millions of parameters for high-resolution inputs
- Significant increases in energy consumption, storage, and latency
- Difficulty in deploying in resource-constrained environments such as robotics, autonomous driving, mobile, and edge devices
- Potential safety risks in domains like healthcare or transportation due to inference delays
- Environmental concerns from the massive energy demand
---
The Bottleneck: Global Representation Learning
Most vision models follow a global representation learning paradigm:
- Process all pixels in parallel
- Extract features for the entire image or video
- Apply features to the task
This global parallel computation causes complexity to grow quadratically or cubically with input size, making it hard to achieve:
- High-resolution input processing
- High-performing large models
- Fast and efficient inference simultaneously
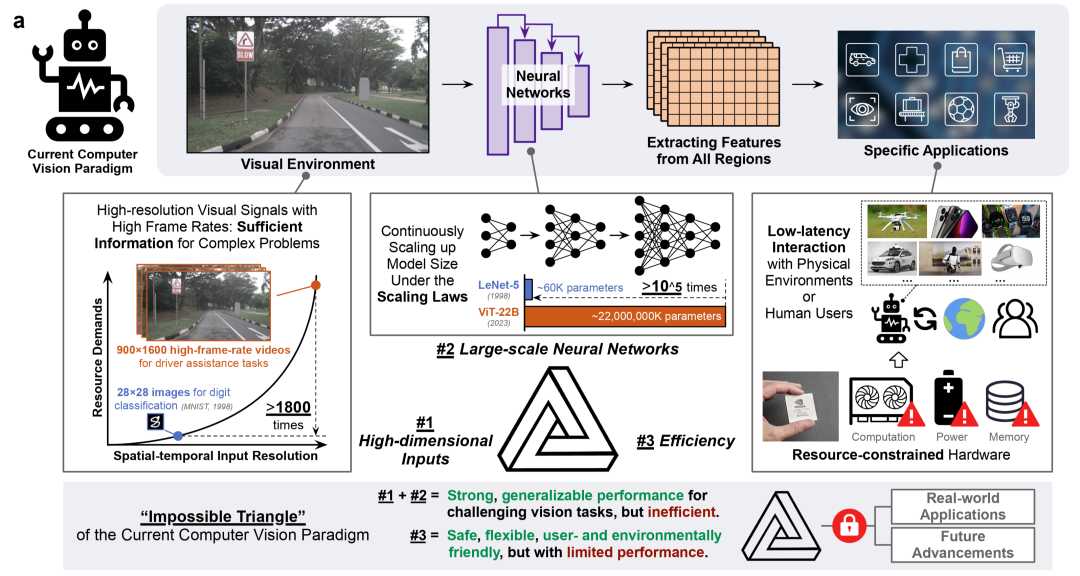
Figure 1: Energy-efficiency bottleneck in current computer vision paradigms
---
Inspiration from Human Vision
Humans use active selective sampling:
- Focus on small, high-resolution visual regions via “fixations”
- Build cognition progressively through multiple observations
- Reduce computation by processing only essential information
- Energy use depends on bandwidth of fixation and number of fixations, not the total number of pixels
In 2015, LeCun, Bengio, and Hinton noted that future AI vision systems should have human-like, task-driven active observation, but systematic research has been scarce.
Figure 2: Human visual system's active adaptive perception strategy
---
AdaptiveNN: Emulating Human-Like Adaptive Vision
In November 2025, Tsinghua University's Department of Automation, led by Shiji Song and Gao Huang, published
Emulating human-like adaptive vision for efficient and flexible machine visual perception in Nature Machine Intelligence.
Key Idea
- AdaptiveNN models vision as a coarse-to-fine sequential decision process:
- Progressively locate key regions
- Accumulate information over multiple fixations
- Stop when enough data is collected for the task
Results:
- Up to 28× reduction in inference cost without accuracy loss
- Dynamic online adjustment to match task and compute limits
- Gaze-path-based inference improves interpretability
- Human-like visual strategies in behavior tests
---
AdaptiveNN Architecture
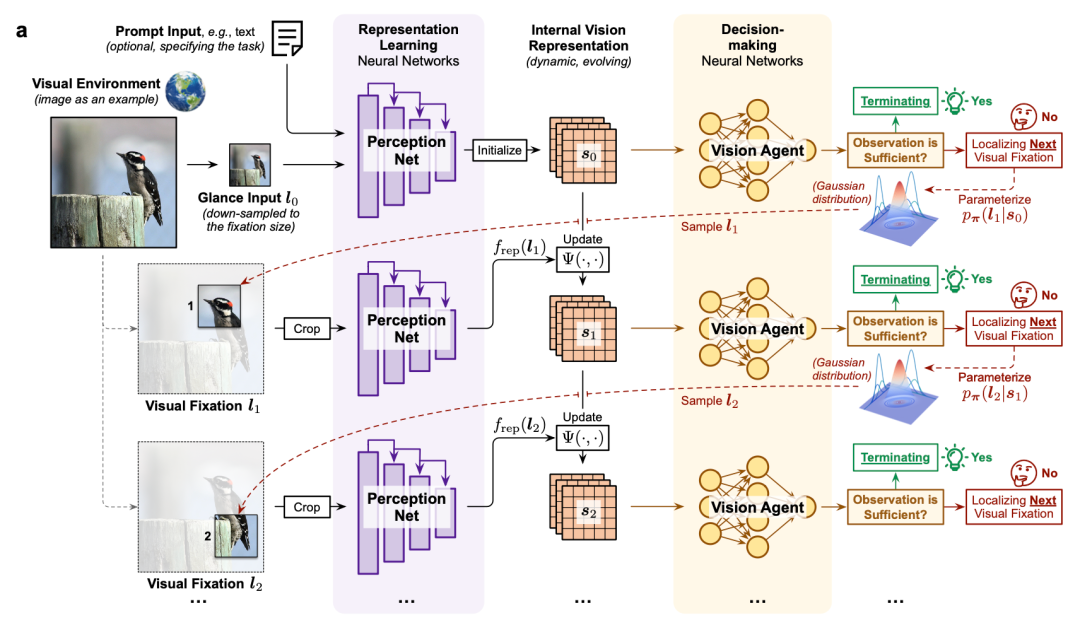
Figure 3: AdaptiveNN's network and inference process
Process:
- Initial Scan — low-resolution global state \( s_t \)
- Vision Agent — evaluates task completion
- Policy Network \(\pi\) — chooses next gaze location
- Representation Network — extracts features from each region
- Update State — refine internal representation
- Termination — stop when task objectives are satisfied
Advantages:
- Global-to-local, coarse-to-fine scanning
- Maintains accuracy while cutting computation costs (“see clearly, spend less”)
- Flexible — works with CNNs, Transformers, pure vision or multimodal tasks
---
Training: Self-Rewarding Reinforcement Learning
The Challenge
Optimizing:
- Continuous variables — feature extraction
- Discrete variables — gaze location decisions
Traditional backpropagation is ill-suited for this mixed problem.
The Solution
End-to-end unified optimization combining:
- Representation Learning — features from gaze regions
- Self-Rewarding Reinforcement Learning — optimizing gaze distribution for task benefits
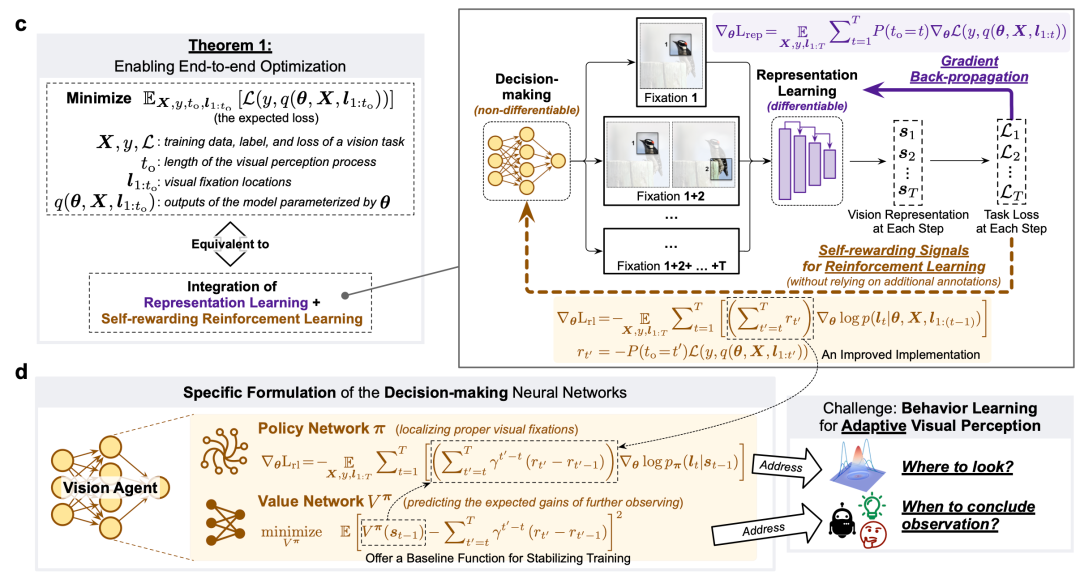
Figure 4: Reinforcement learning–driven end-to-end active vision
---
Experimental Results
Image Classification
- AdaptiveNN-DeiT-S:
- Accuracy: 81.6%, Cost: 2.86 GFLOPs (5.4× savings)
- AdaptiveNN-ResNet-50:
- Accuracy: 79.1%, Cost: 3.37 GFLOPs (3.6× savings)
Interpretability
- Gaze focuses on discriminative regions (e.g., animal heads, instrument details, machine parts)
- Extends sequence when targets are small or distant
- Strategy mirrors human fixations
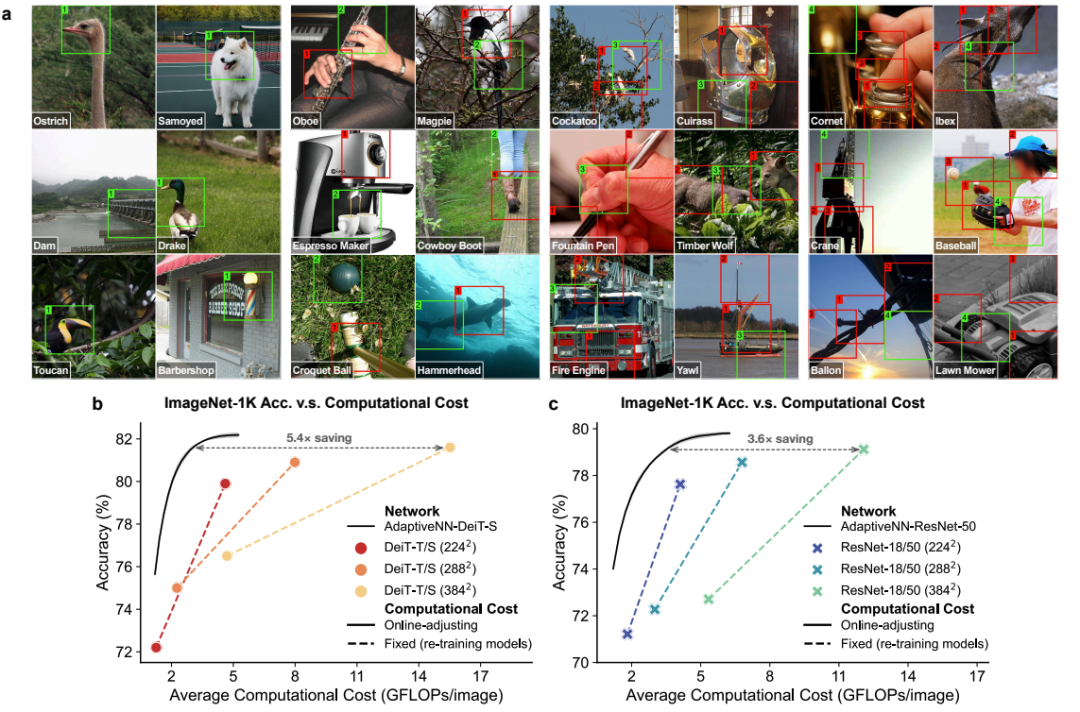
---
Fine-Grained Visual Recognition
Tasks: CUB-200, NABirds, Oxford-IIIT Pet, Stanford Dogs, Stanford Cars, FGVC-Aircraft
Performance:
- 5.8×–8.2× computational savings
- Equal or better accuracy
- No explicit localization supervision needed for focus
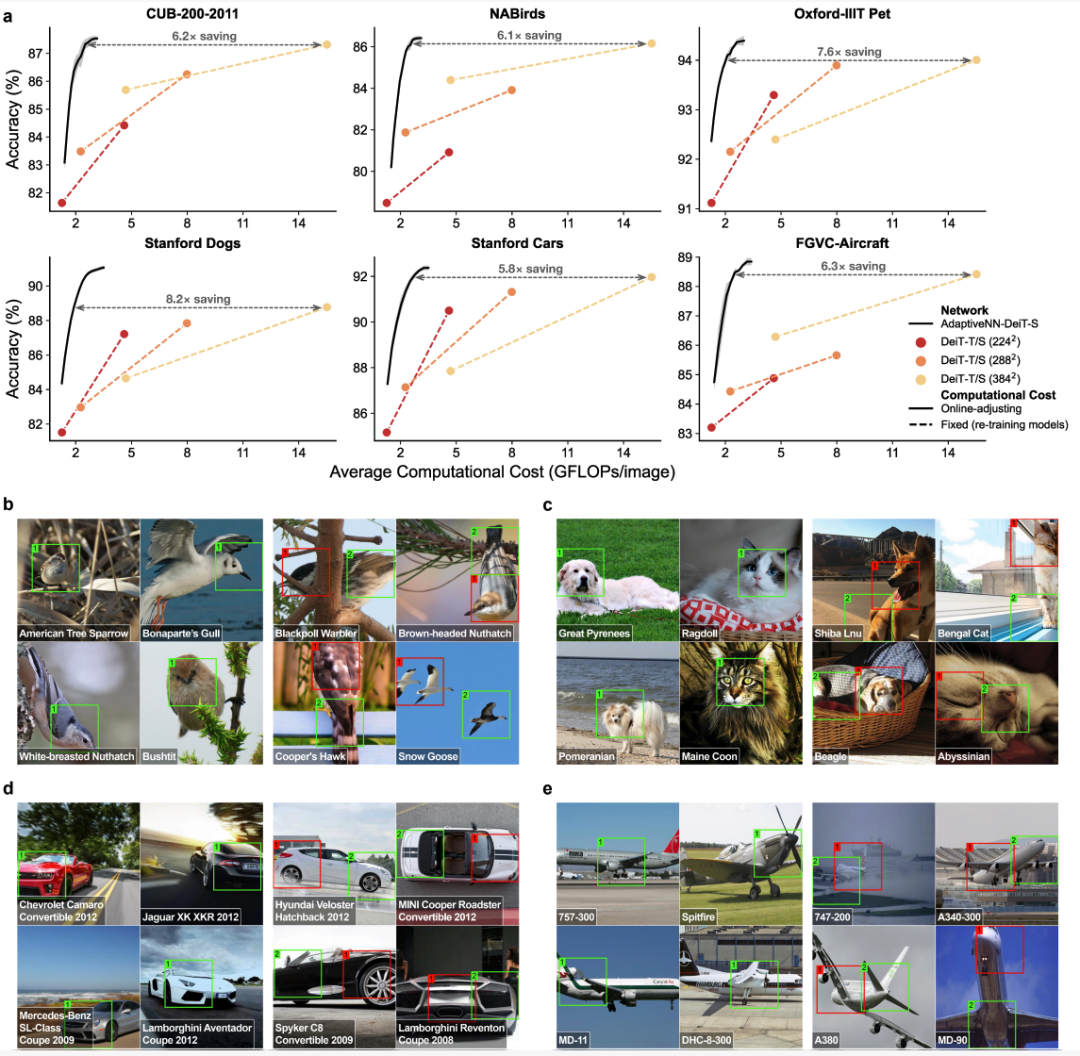
Figure 6: Fine-grained recognition results
Human-Like Behavior:
- Similar gaze positioning and difficulty assessment patterns
- Visual Turing Test: Humans could barely distinguish model vs. human gaze paths
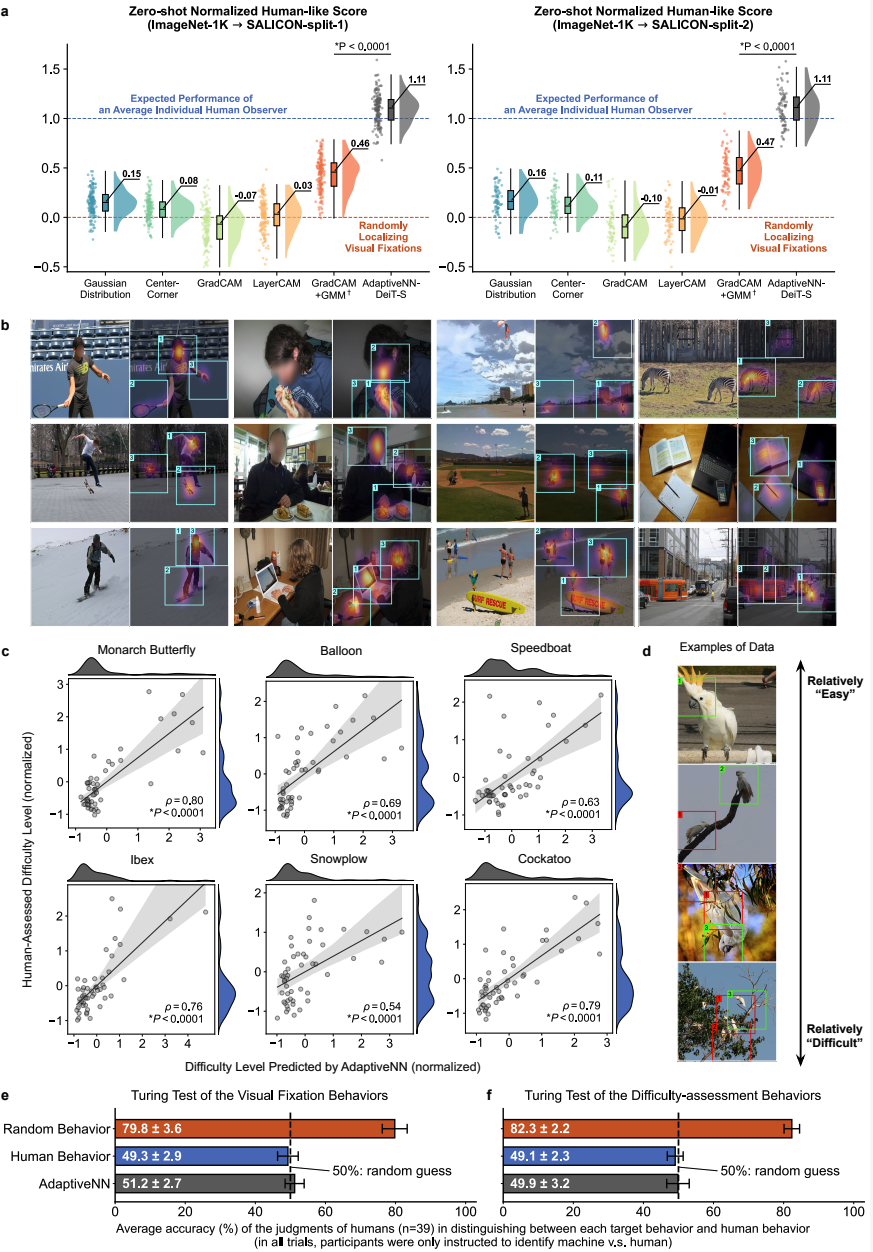
Figure 7: Model–human perception consistency
---
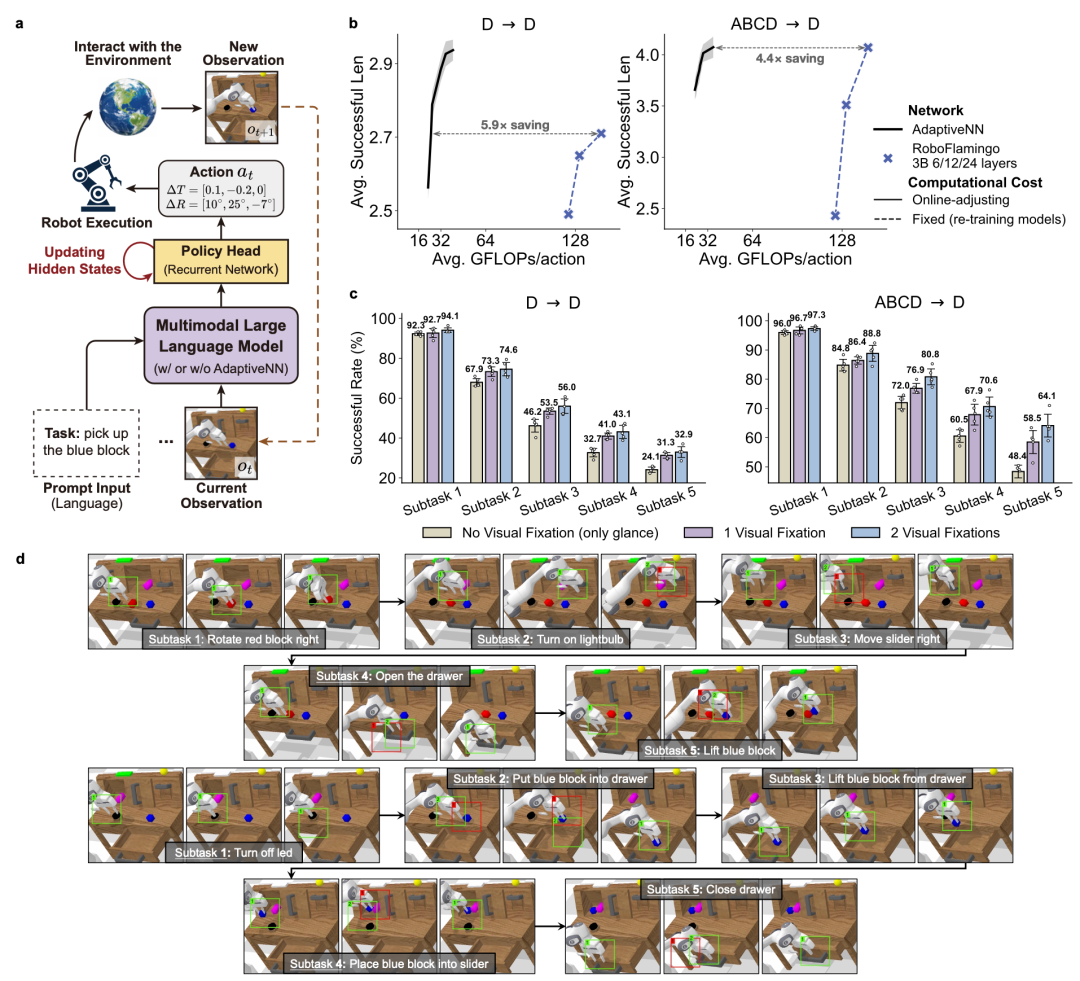
From Perception to Embodied Intelligence
Applied to Vision–Language–Action (VLA) foundation models:
- In complex scenarios:
- 4.4–5.9× reduction in computation
- Maintained task success rate
- Improved reasoning and perception efficiency in embodied AI
---
Broader Impact and Application
AdaptiveNN links efficient perception with multi-platform AI content workflows:
- Platforms like AiToEarn官网 offer:
- AI content generation
- Cross-platform publishing
- Analytics
- Model ranking (AI模型排名)
Use case:
- Publish vision insights to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, YouTube, LinkedIn, Pinterest, X
- Monetize via open-source tools (开源地址)
---
Paper Link: https://www.nature.com/articles/s42256-025-01130-7


