Nature reveals Google IMO gold medal model technical details: Core team of only 10 generates 80 million math problems for AI training in a year

Google DeepMind Unveils AlphaProof — IMO Gold Medal-Winning AI
Google DeepMind’s latest breakthrough in mathematical reasoning, AlphaProof, has been fully disclosed — including both its architecture and training methods.
Continuing DeepMind’s naming tradition, AlphaProof builds upon earlier successes like AlphaZero and now joins the ranks of Nature-published research.

---
Behind the Scenes: Development Insights
Lead author Tom Zahavy shared key moments from the project:
- Small, focused team — around 10 core members, with more joining near the IMO competition.
- Key breakthrough by Miklós Horváth (IMO gold medallist) — devised a method to generate multiple problem variations for training.
The team experimented for over a year, integrating only the most effective ideas into AlphaProof.
---
Core Concept: Turning Proof into a Game
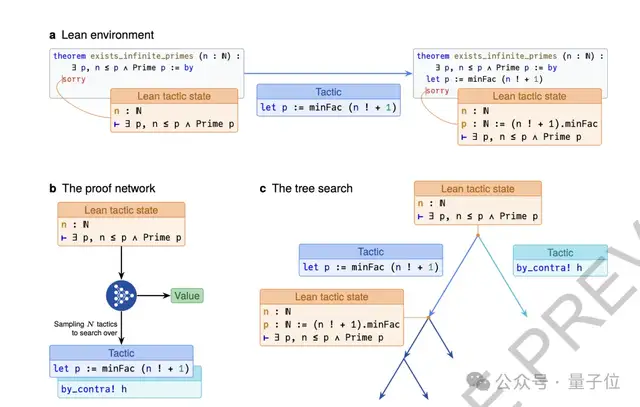
AlphaProof transforms mathematical proving into a reinforcement learning environment using the Lean theorem prover:
- Each proposition becomes a new “game level.”
- The AI selects tactics to advance the proof.
- Success yields sub-goals; completing all goals finishes the proof.
---
Architecture & Training
Model Design
- 3-billion-parameter encoder-decoder transformer as the “brain.”
- Outputs:
- Next tactics to try.
- Steps remaining estimate.
Search Approach
- Modified AlphaZero-style tree search.
- AND-OR tree structure breaks proofs into independent subproblems.
- Progressive sampling explores diverse strategies.
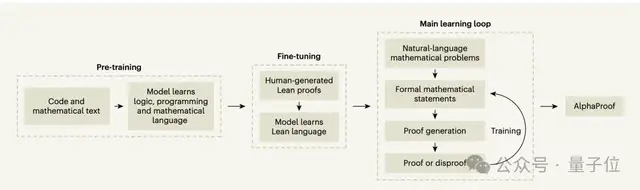
Data Acquisition
- Pretraining — 300B tokens of code/math text for logic fundamentals.
- Fine-tuning — 300K human-written proofs from Mathlib.
- Automated formalization — Using Gemini 1.5 Pro to convert natural-language problems into Lean format.
- Generated ~80M formalized problems from 1M questions.
Main Reinforcement Loop
- Continually attempts to prove/disprove generated propositions.
- Each attempt adds experience data for learning — even imperfect formalizations are useful.
- Compute used: ~80,000 TPU days.
---
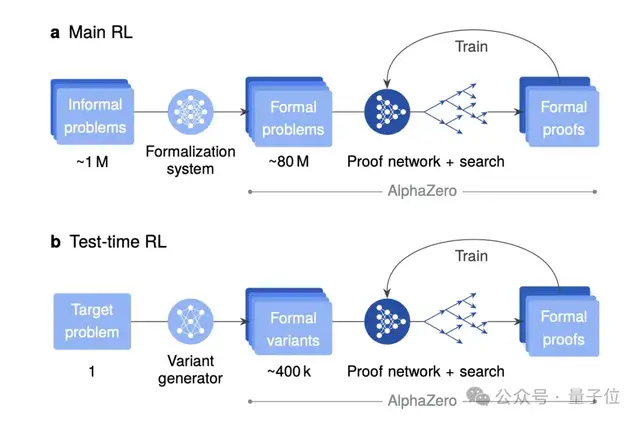
Variant Generation for Hard Problems
For especially tough targets:
- Generate ~400,000 problem variants.
- Includes simplifications, generalizations, and related cases.
- Train dedicated models in parallel, each with its own curated curriculum.
---
IMO 2024 Performance & TTRL
At IMO complexity, more search time isn’t enough — enter Test-Time Reinforcement Learning (TTRL):
- Create many variants of the target problem.
- Train an “expert” model specifically on these variants.
Example: IMO 2024 Problem 1
- Variants: Only rational α, stronger conditions, α near integer values.
Results:
- Solved 3 problems (P1, P2, P6) — P6 was the hardest, solved by only 5 of 609 participants.
- Each TTRL run: ~2–3 days compute.
- Initially expected bronze; final full solutions emerged days later, securing gold.

---
Open Access for Researchers
Post-win, DeepMind opened AlphaProof for applications:

User feedback:
- Alex Kontorovich: Effective at finding counterexamples — quickly reveals missing assumptions.
- Talia Ringer: Proved one PhD lemma in under a minute; refuted another, exposing a definition flaw.
---
Known Limitations
- Custom definitions bottleneck — Struggles outside well-established Mathlib concepts.
- Lean dependency — Strength from mature tactics, weakness in evolving environment.
- Data scarcity — Limited unique math problems; variant generation is promising but still limited.
---
Future Outlook
- Generating novel problems will be key for general-purpose math AIs.
- Geoffrey Hinton predicts AI will surpass humans in math knowledge-sharing and dataset generation.
- AlphaProof is an early glimpse of this future.
---
Parallel in Creative Content
Platforms like AiToEarn官网 offer AI content generation, publishing, and monetization — across Douyin, Kwai, WeChat, Bilibili, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X.
They integrate:
- Content generation
- Cross-platform publishing
- Analytics
- Model ranking (AI模型排名)
Mirroring AlphaProof’s workflow — scaling capability & impact via integrated AI pipelines.
---
Paper & References
Paper:
https://www.nature.com/articles/s41586-025-09833-y
References:
[1] https://www.tomzahavy.com/post/how-we-achieved-an-imo-medal-one-year-before-everyone-else
[2] https://www.nature.com/articles/d41586-025-03585-5
---
If you publish advanced topics like the AlphaProof breakthrough, platforms like AiToEarn官网 help you create, distribute, and monetize globally — while tracking reach and performance via AI模型排名.


