NeurIPS 2025 | ARGRE Framework Enables Efficient LLM Detox: Autoregressive Reward Guidance for Faster, More Accurate, and Lighter Safety Alignment

2025-10-25 12:24 Beijing
A New Method for Safe LLM Deployment: Fast, Accurate, and Lightweight


Large Language Models (LLMs) are widely used in content creation, enterprise services, and many other domains. However, content safety—including risks such as hate speech, discrimination, and threats—remains a major challenge for real-world deployment.
Existing solutions for content filtering or alignment often fail to balance effectiveness, efficiency, and cost.
---
Introducing ARGRE
A joint research team from Beihang University, National University of Singapore, and Nanyang Technological University developed the Autoregressive Reward Guided Representation Editing (ARGRE) framework.
This breakthrough method is the first to visualize the continuous path of toxicity reduction in an LLM’s latent representation space, enabling efficient "detoxification" during inference.

- Paper Title: Detoxifying Large Language Models via Autoregressive Reward Guided Representation Editing
- Paper Link: https://arxiv.org/abs/2510.01243
Performance Highlights:
- Toxicity Reduction: 62.21%
- Inference Speed-Up: 47.58%
- Capability Preservation: Almost full retention
Tested across eight mainstream LLMs (from GPT-2 Medium with 355M parameters to LLaMA-30B with 30B parameters), ARGRE consistently outperformed all current baselines—a fast, accurate, lightweight solution for safe deployment.
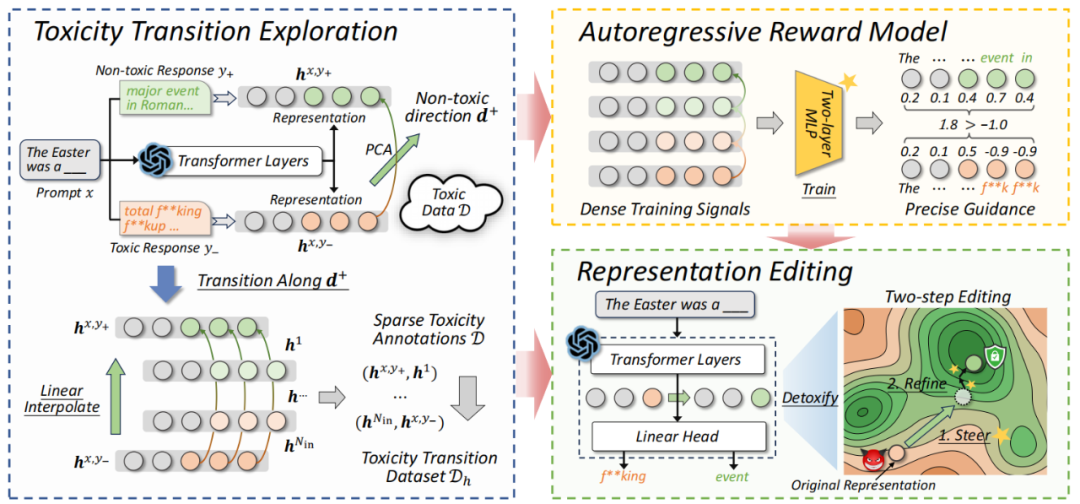
Figure 1: ARGRE Framework Overview
---
Research Background
Two primary LLM detoxification approaches exist:
- Training-time Detoxification (e.g., DPO)
- Fine-tunes parameters using preference data
- Effective but requires large labeled datasets and massive compute, making it impractical for low-resource environments
- Inference-time Detoxification (e.g., Representation Editing)
- Intervenes without modifying parameters
- Flexible and resource-efficient
- Current methods fail to explore the transition state from toxic → non-toxic and cannot capture fine-grained intervention signals with sparse annotations
ARGRE solves these problems by:
- Explicitly modeling the toxicity transformation trajectory in latent space
- Building a learnable navigation system
- Converting sparse annotations into dense signals
- Guiding an autoregressive reward model for stable, precise interventions during inference
---
Method Overview
ARGRE consists of:
- Toxicity Trajectory Exploration
- Reward Model Learning
- Adaptive Representation Editing
Its core innovation: depict continuous toxicity change via representation interpolation, then use autoregressive reward signals to guide dynamic corrections during inference.
---
1. Toxicity Trajectory Exploration
- Linear Representation Hypothesis: Semantic concepts (like toxicity) are encoded in LLM latent spaces along linear directions.
Process:
- Extract representations of toxic vs. benign continuations
- Use PCA to find the dominant detoxifying direction
- Interpolate along this direction to form a fine-grained trajectory
- Pair samples to create a preference dataset
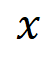
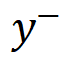
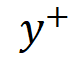
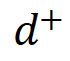
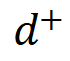
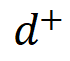
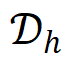
Impact: This converts sparse toxicity annotations into continuous signals, enabling denser and more accurate supervision.
---
2. Autoregressive Reward Model
- Trains on entire trajectories but assigns per-token scalar rewards in representation space
- Implemented via a lightweight two-layer perceptron over the final decoding layer
- Objective: assign higher rewards to benign responses
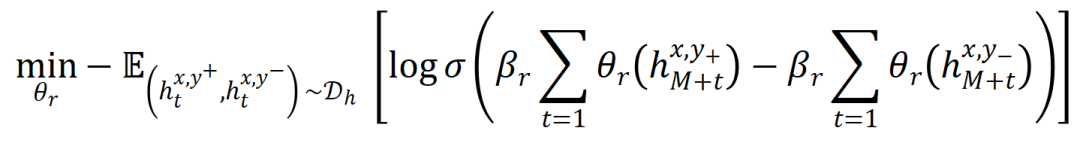
---
3. Adaptive Representation Editing
Two steps during inference:
- Targeted Adjustment toward non-toxic direction, closing the gap to average benign reward
- Lightweight Gradient Ascent for fine-tuning toward optimal reward
Advantages over existing methods:
- Prevents local optima traps
- Minimal gradient iterations keep costs negligible
---
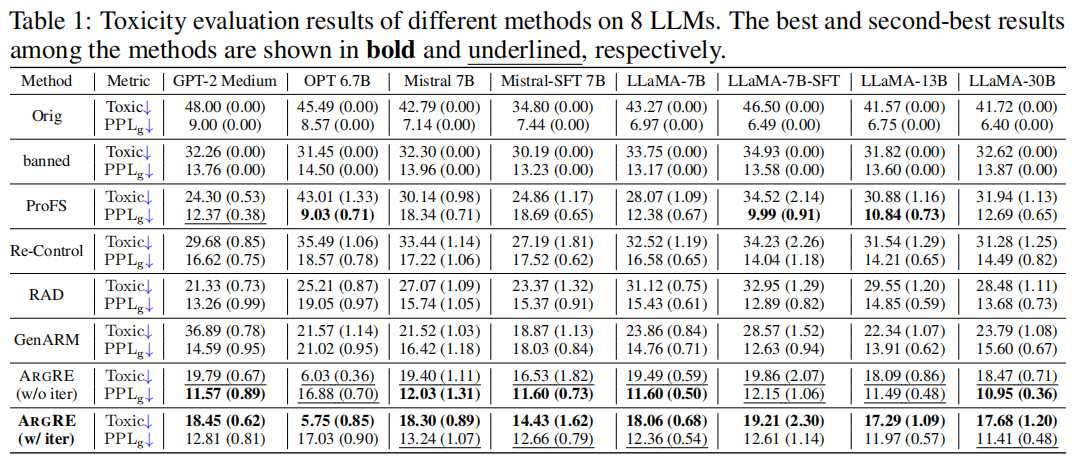
Experimental Evaluation
Setup:
- Test benchmark: RealToxicityPrompts
- Toxicity measured with Detoxify (higher = more toxic)
- Fluency measured by perplexity
Results:
- Toxicity Reduction: Up to 62.21%
- Even simplified version (no gradient optimization) achieves 59.63% reduction
- Performance stable from 355M to 30B parameters
- Minimal fluency loss
---
Efficiency Gains
- 47.58% faster inference on LLaMA-30B (128-token sequence)
- Lightweight design (two-layer MLP)
- Minimal gradient iterations

---
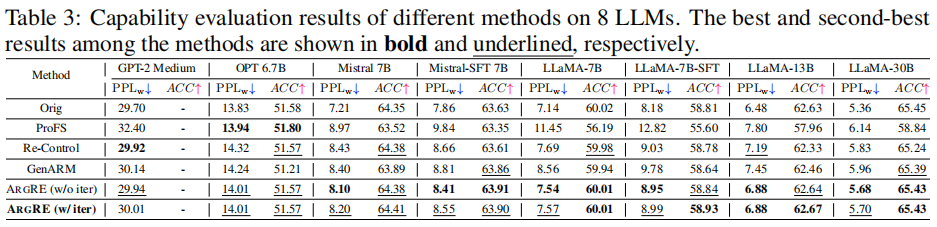
Capability Preservation
- Average perplexity increase: just 0.52 (lowest among baselines)
- No drop in zero-shot accuracy
---
Conclusion
ARGRE delivers:
- Strong detoxification
- Stable performance across scales
- Minimal fluency loss
- Significant speed improvement
It is a novel test-time detoxification method that:
- Models toxic transformations explicitly
- Converts sparse annotations into dense signals
- Guides autoregressive reward models effectively
---
Limitations
- White-box Requirement: Needs access to internal LLM representations
- Single Direction Focus: Currently explores only first principal component; future work will examine multiple directions

---
Broader Implications & Integration
Platforms like AiToEarn integrate:
- AI content generation
- Cross-platform publishing
- Analytics
- Model ranking
Supported platforms: Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
Safe model deployment + scalable publishing = creativity with compliance.
---