NeurIPS 2025 | Cracking Closed-Source Multimodal Models: A Novel Adversarial Attack via Optimal Feature Alignment

Introduction
In recent years, Multimodal Large Language Models (MLLMs) have made remarkable breakthroughs, showing strong capabilities in visual understanding, cross-modal reasoning, and image captioning.
However, with wider deployment in real-world scenarios, security risks have become a growing concern.
Research indicates that MLLMs inherit adversarial vulnerabilities from their visual encoders, making them susceptible to adversarial examples — small, imperceptible changes that can cause incorrect outputs or leak sensitive information.
In large-scale deployments, this can lead to serious consequences.
---
The Challenge: Transferability of Attacks
Transferability refers to the effectiveness of adversarial examples across different models — especially closed-source ones.
When targeting powerful commercial systems such as GPT‑4 or Claude‑3, existing methods often fail because:
- They focus only on global features (e.g., CLIP `[CLS]` token).
- They ignore rich local feature information from image patch tokens.
This insufficient feature alignment results in poor cross-model transfer ability.
---
Our Solution: FOA‑Attack
FOA‑Attack (Feature Optimal Alignment Attack) is a targeted transfer adversarial attack framework designed to align features optimally at both global and local levels.
Key ideas:
- Global-level alignment using cosine similarity loss.
- Local-level alignment via clustering + Optimal Transport (OT) for precise matching.
- Dynamic Weight Integration to balance contributions from multiple surrogate models.
---
Performance:
Experiments show FOA‑Attack outperforms state-of-the-art methods on both open-source and closed-source MLLMs — including notable success rates against commercial models.
Resources:

---
Research Background
MLLMs such as GPT‑4o, Claude‑3.7, and Gemini‑2.0 integrate language and vision to achieve high performance in tasks like visual question answering.
Adversarial attacks categories:
- Untargeted: Cause incorrect outputs.
- Targeted: Force specific intended outputs.
In black‑box scenarios (especially with closed-source, commercial models), achieving efficient targeted transfer attacks is difficult because:
- Adversarial examples must deceive unknown models without access to their architecture or parameters.
- Existing methods show low success rates on cutting-edge closed-source MLLMs.
---
Motivation & Analysis
In Transformer-based visual encoders (e.g., CLIP):
- [CLS] token captures macro-level semantics but loses important details.
- Patch tokens encode local details (fine-grained shape, texture, environment context).
Problem:
Over-reliance on global `[CLS]` features reduces attack realism and transferability.
Since closed-source models often use different encoder designs, these global-only adversarial examples perform poorly.
Solution:
FOA‑Attack leverages dual-dimensional alignment:
- Global cosine similarity for macro semantics.
- Local OT matching via clustering for fine details.
---
Method Overview
1. Global Coarse-Grained Alignment
Align `[CLS]` token features between adversarial sample and target image:
- Extract global features X, Y from visual encoder.
- Use cosine similarity loss: maximizes macro semantics match.
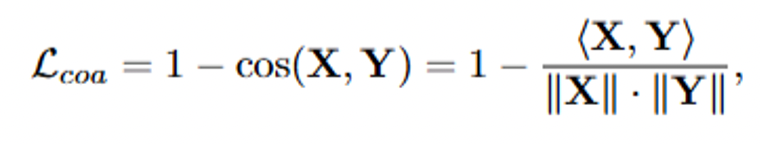
---
2. Local Fine-Grained Alignment
Align patch token features:
- Use K-means clustering to extract semantic regions (e.g., “elephant’s head”, “forest ground”).
- Model as an Optimal Transport problem using Sinkhorn algorithm.

---
3. Dynamic Ensemble Model Weighting
Prevent bias toward easily optimized models:
- Measure learning speed Si(T) for each surrogate model.
- Adjust weights — slower learning → higher weight.
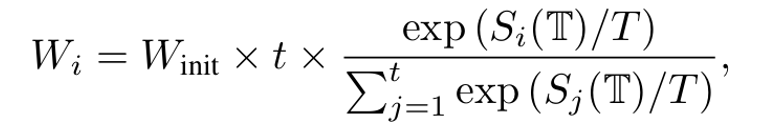
---
Why This Matters
Dual-dimensional alignment + dynamic weighting:
- Improves semantic authenticity of adversarial examples.
- Significantly increases transferability to closed-source MLLMs.
For example, when distributing and analyzing multi-platform AI experiments, tools like AiToEarn官网 can help with open-source content monetization and cross-platform publishing to channels like Douyin, Kwai, WeChat, Bilibili, Facebook, Instagram, and X (Twitter).
---
Experimental Results
Open-Source Models
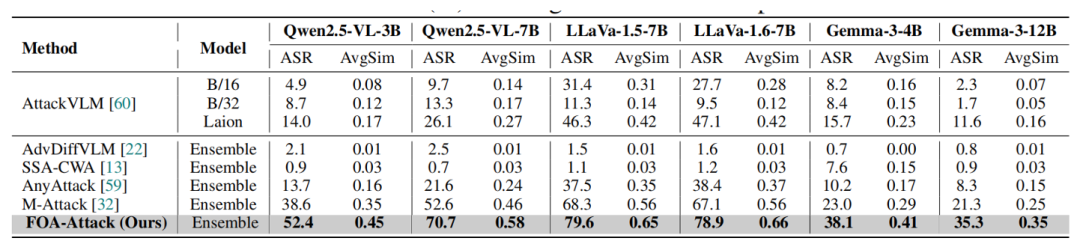
Table 1: Higher ASR and AvgSim on Qwen2.5-VL, LLaVA, Gemma compared to baselines.
---
Closed-Source Models
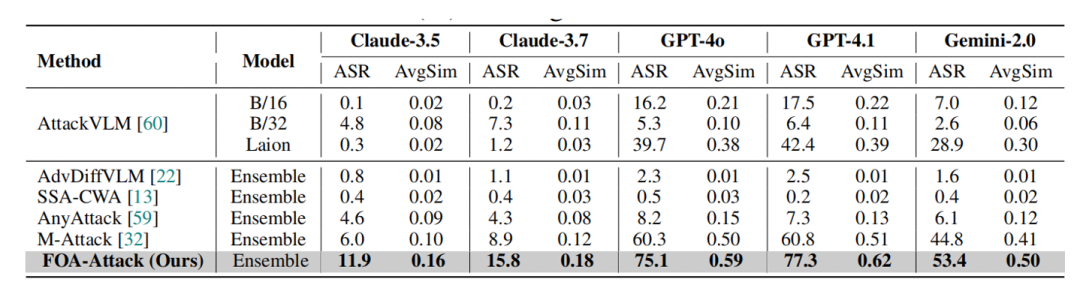
Table 2: Against GPT-4o, Claude-3.7, Gemini-2.0:
- FOA‑Attack achieves 75.1% ASR on GPT‑4o.
---
Reasoning-Enhanced Models

Table 3: Even reasoning-robust models like GPT-o3 and Claude-3.7-thinking remain vulnerable.
---
Visualization

Figure 3: Original image, adversarial image, perturbation visualization.
---
Conclusion
FOA‑Attack shows that targeted adversarial examples can be made highly transferable by:
- Aligning both global and local features.
- Dynamically balancing multi-model ensembles.
This research:
- Exposes vulnerabilities in current MLLM visual encoders.
- Suggests new defense strategies (e.g., improving robustness for local features).
Next Steps:
Address efficiency and computational cost challenges to make FOA‑Attack even more practical.
---
Resources:
- Paper: https://arxiv.org/abs/2505.21494
- Code: https://github.com/jiaxiaojunQAQ/FOA-Attack
- AiToEarn: Blog, GitHub
---
Would you like me to add a separate "Step-by-Step Implementation" section for FOA‑Attack so readers can more easily reproduce the experiments? That could make your Markdown more tutorial-oriented.


