NeurIPS 2025 Results: Alibaba Qwen’s Gated Attention Wins Best Paper, Kaiming He’s Faster R-CNN Receives Test-of-Time Award

📢 NeurIPS 2025 — Best Paper & Test of Time Awards Announced
This year’s awards spotlight groundbreaking research in diffusion model theory, self-supervised reinforcement learning, LLM attention mechanisms, reasoning capabilities of LLMs, online learning theory, neural scaling laws, and benchmarking diversity in language models.
---
🏆 Award Highlights
- 4 Best Paper winners — 3 with first authors of Chinese origin, including Alibaba Qwen’s Gated Attention work.
- 3 Best Paper Runner-ups, bringing the total to 7 recognized papers.
- Test of Time Award to Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun for Faster R-CNN (2015).

---
🏅 Test of Time — Faster R-CNN
Core Contribution:
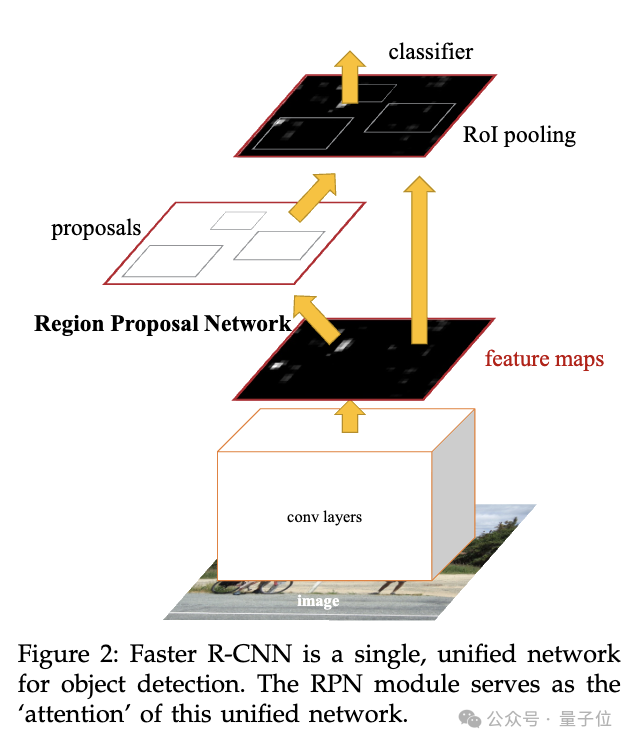
Faster R-CNN introduced the Region Proposal Network (RPN), resolving the computational bottleneck in traditional object detection by sharing convolutional features between proposal generation and classification.
- Task addressed: Object detection — identify and locate objects in images.
- Key innovation: End-to-end, near-real-time detection with dramatic speed improvements.

---
📄 Best Paper Summaries
1. Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Author: Liwei Jiang, University of Washington
Topic: Diversity limitations in large language models (LLMs)
Findings:
- LLMs exhibit high intra-model repetition and inter-model homogeneity — even with diversity-oriented decoding (min-p), over 60% of responses have similarity > 0.8.
- Example: “Write a metaphor about time” → 25 model families’ outputs cluster into mainly “Time is a river” and “Time is a weaver.”
- INFINITY-CHAT dataset: 26K real-world prompts, 31K+ human ratings.
- LLM reward models often fail to capture nuanced human preference diversity.

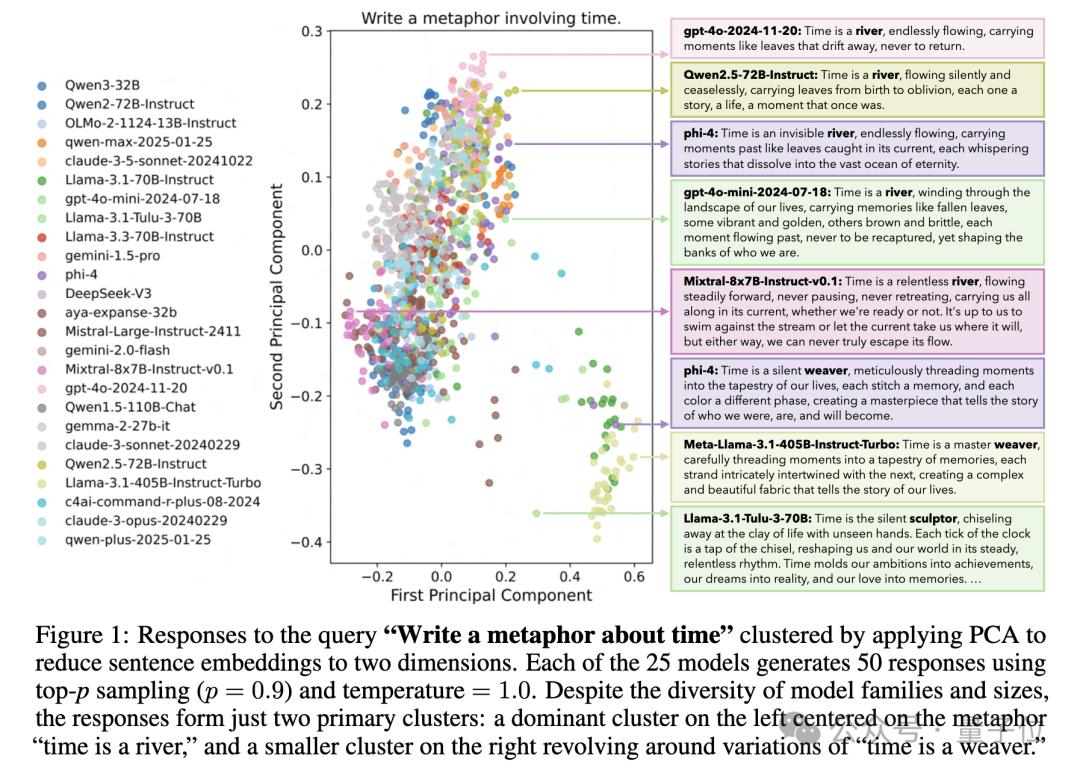
Impact: Warns of risks in homogenizing human thought; proposes benchmarks for diversity-aware AI.
---
2. Gated Attention for Large Language Models
Authors: Zihan Qiu, Zekun Wang, Bo Zheng (Alibaba Qwen), Zeyu Huang (University of Edinburgh)
Topic: Enhancing LLM attention mechanisms.
Core Results:
- Attention-head-specific sigmoid gating after Scaled Dot-Product Attention (SDPA) → improved performance, stability, tolerance to larger learning rates, better scaling.
- Reduces attention sink problem (first token getting ~47% attention → now <5%).
- Improves long-context extrapolation (RULER benchmark +10 points).
- Effective in dense and MoE models, supporting up to 128k context length.
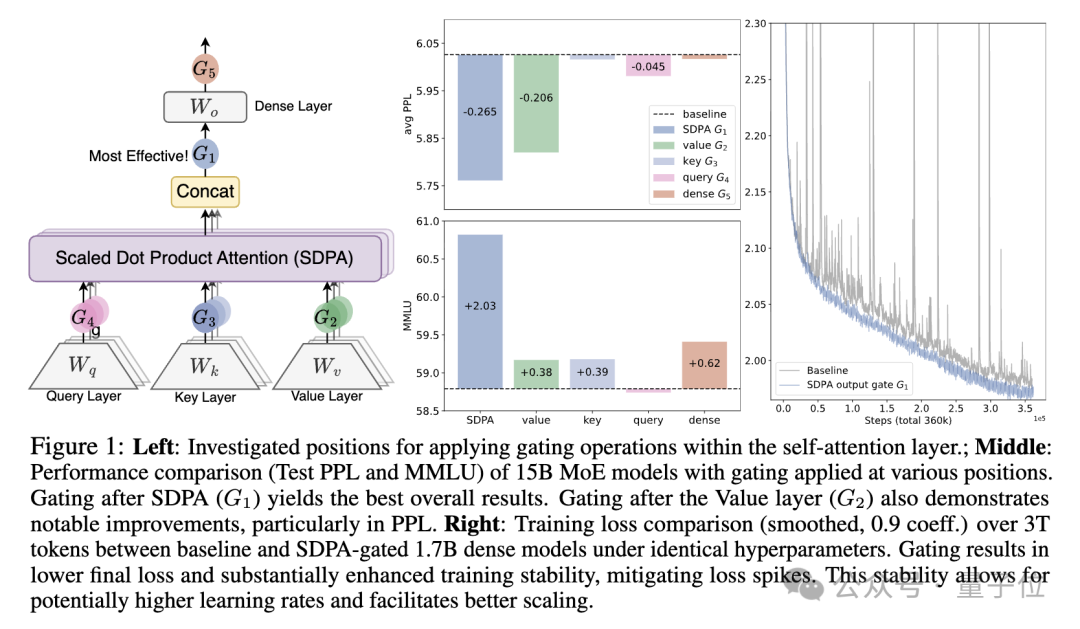
---
3. 1000 Layer Networks for Self-Supervised RL
Topic: Extreme depth scaling in RL networks.
Key Implementation:
- Actor-critic depth up to 1024 layers.
- Techniques: residual connections, layer normalization, Swish activation.
- Applied to Contrastive RL (CRL), unsupervised settings.
Results:
- Depth scaling → 2–50× performance improvement in CRL across locomotion, navigation, manipulation tasks.
- Critical depth thresholds unlock qualitatively new behaviors (e.g., wall climbing in Ant maze, seated locomotion in humanoids).
- Efficiency: Depth scaling is computationally cheaper than width scaling, especially when combined with batch scaling.

---
4. Diffusion Models — Avoiding Memorization via Implicit Dynamical Regularization
Authors: Tony Bonnaire, Raphaël Urfin (Paris Institute of Advanced Science and Research)
Key Insight:
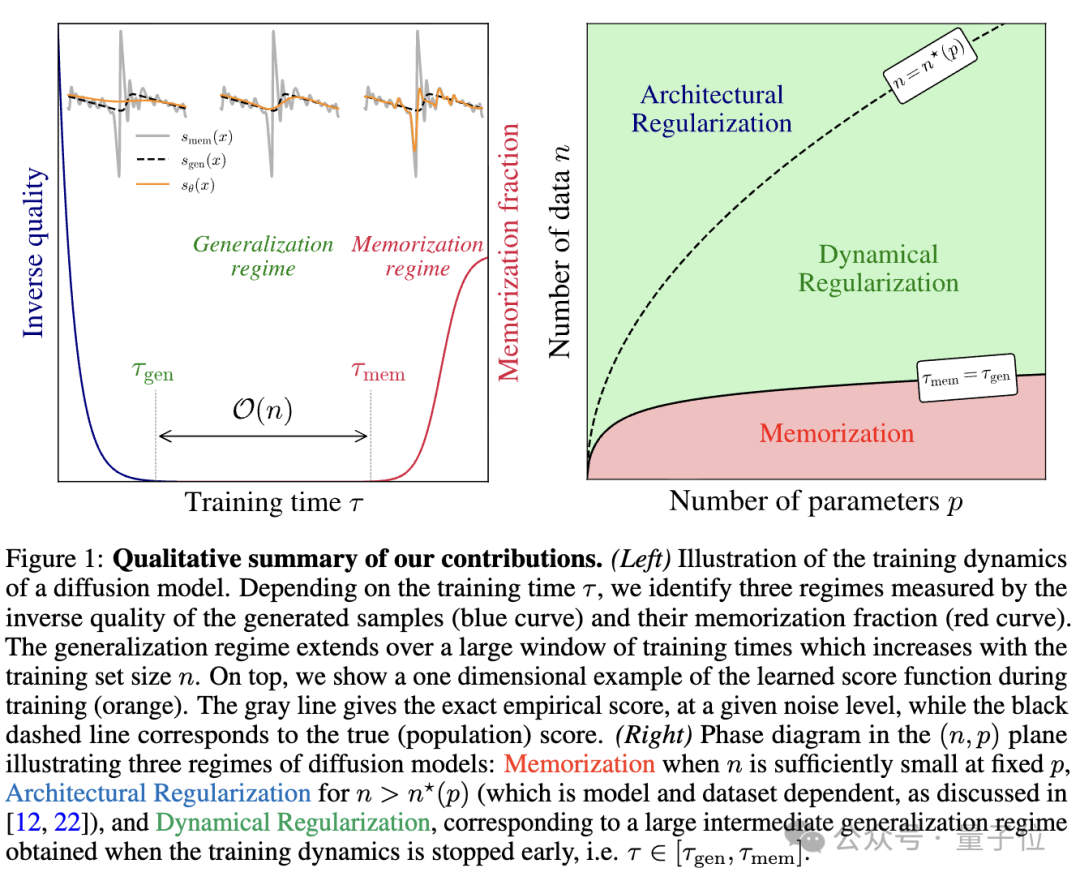
Training dynamics create two time scales:
- Generalization time (constant across dataset sizes)
- Memorization time (grows linearly with dataset size)
Mechanism:
Implicit dynamical regularization widens the generalization window, preventing memorization even in over-parameterized models.
---
📈 Faster R-CNN — Technical Deep Dive
Main Features:
- Region Proposal Network (RPN):
- Predicts bounding boxes & objectness scores for every position in the feature map.
- Uses 9 anchors (3 sizes × 3 aspect ratios) to cover varied shapes.
- Eliminates need for image pyramids.
- Multi-task loss: classification + regression.
- Four-step alternating training: merges RPN & Fast R-CNN into a shared convolutional feature framework.
Performance:
- 300 proposals outperform Selective Search’s 2000 proposals.
- 5 FPS with VGG-16 on GPU.
- Won multiple tracks in ILSVRC & COCO 2015 competitions.
---
💡 Broader Implications
These papers highlight two common themes in modern AI research:
- Architectural innovation (e.g., gated attention, deeper RL networks) can unlock scaling potential.
- Awareness of diversity and memorization issues is critical for human-aligned AI development.
---
🌍 Cross-platform Publishing & Monetization
Platforms like AiToEarn官网 bridge research and real-world reach:
- AI content generation + cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X).
- Analytics and model ranking (AI模型排名).
- Enables researchers and creators to monetize AI-driven outputs.
Explore:
---
📜 References
---
Would you like me to also convert these individual paper sections into tabular summaries with columns for Authors, Topic, Key Results, and Impact so the whole award coverage becomes easier to scan? That would make this even more digestible for readers.


