NeurIPS 2025 Spotlight | RobustMerge: A New Paradigm for Efficient Multimodal Large Model Fine-Tuning and Merging

2025-11-10 12:38 Beijing

Opening new possibilities for efficient multimodal large language model applications.

---
Overview
In today’s fast-changing AI landscape, one of the main challenges in deploying large models is integrating multiple specialized capabilities into a single, general-purpose model efficiently. Although full fine-tuning (FFT) has made breakthrough progress, there are no clear guidelines for efficient fine-tuning specifically for model merging.
Researchers from the Chinese Academy of Sciences, Sun Yat-sen University, and Peking University introduce the concept of Direction Robustness — uncovering that PEFT module merge failures are caused by a lack of directional robustness, not the previously assumed sign conflicts. They offer an elegant, zero-cost solution: RobustMerge.
This work is vital for developers and researchers aiming to build multimodal large models that adapt quickly to diverse tasks while conserving computational resources.
📌 Accepted as a Spotlight (Top 3.1%) at NeurIPS 2025
📌 Fully open-sourced: code, datasets, and models

---
Resources
- 📄 Paper: https://arxiv.org/abs/2502.17159
- 💻 Code: https://github.com/AuroraZengfh/RobustMerge
- 📊 Dataset: https://huggingface.co/datasets/AuroraZengfh/MM-MergeBench
- 📚 HuggingFace Paper: https://huggingface.co/papers/2502.17159
---
Problem Definition
Challenges in Multimodal Large Models
- Higher task performance, but greater computational cost.
- FFT on models with billions of parameters is often infeasible.
Parameter-Efficient Fine-Tuning (PEFT) methods — especially LoRA — allow for rapid adaptation by updating only a small portion of parameters.
However:
- Each LoRA module is task-specific.
- Merging them into a general-purpose model is complex.
---
Multi-task Learning Limitations
Traditional multi-task learning uses joint training on combined datasets but faces:
- High cost — Time, labor, and compute.
- Data unavailability — Privacy and security restrictions.
---
Model Merging
Model merging fuses the knowledge of multiple expert models without retraining or accessing original data.
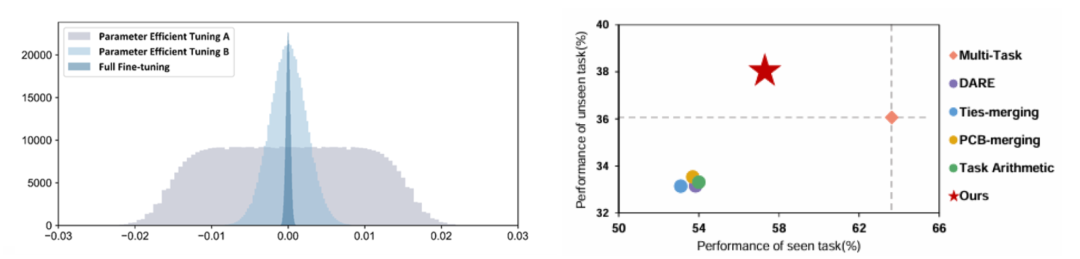
In FFT-era approaches, methods like Ties-merging and DARE worked well.
But in PEFT merging, applying these methods often yields worse performance than Zero-Shot models.
---
Core Contribution
RobustMerge:
- Targets poor performance in PEFT merging.
- Identifies directional robustness as the root cause.
- Provides a training-free, simple, and efficient solution.
---
Findings: Direction Robustness
Comparing LoRA and FFT modules reveals:
- Broader parameter distribution in LoRA.
- Sharp singular value differences due to low-rank nature.
Key insight:
- Head singular values — task-specific, stable directions.
- Tail singular values — task-independent, unstable directions (easily disturbed).
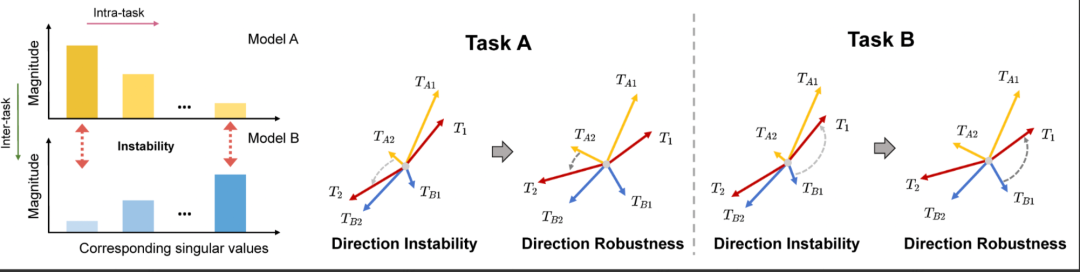
Thus, in merging LoRA modules, preserving stable directional vectors — especially for small singular values — is critical.
---
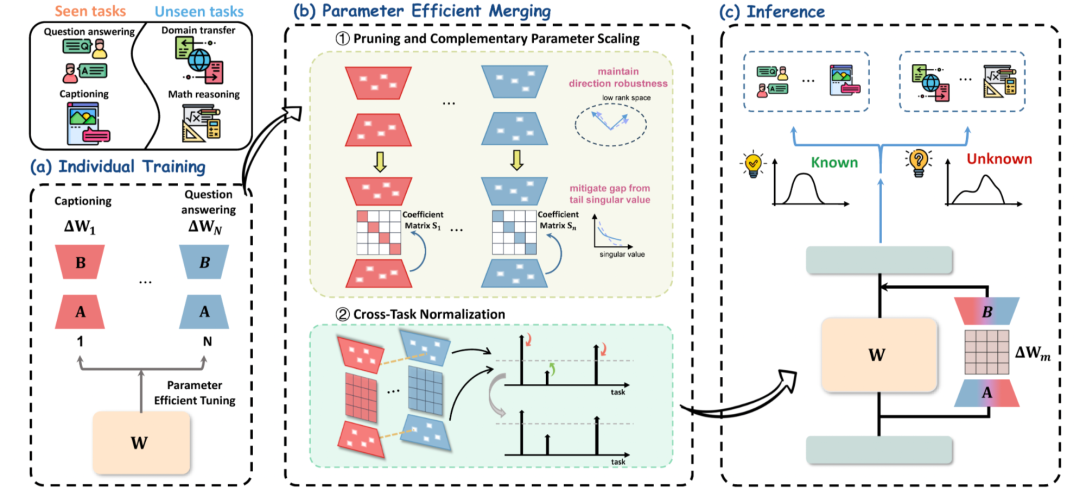
Technical Approach: RobustMerge
Goal: Maintain direction stability in low-rank space.
Two-Stage Strategy
- Pruning & Complementary Scaling — Removes unstable parameters and boosts weaker directions.
- Cross-task Normalization — Balances scaling across tasks.
---
Step 1: Pruning & Complementary Scaling
1. Pruning
- Remove small-magnitude parameters within each LoRA module (bottom k%).
- Suppresses interference and preserves robust directions.
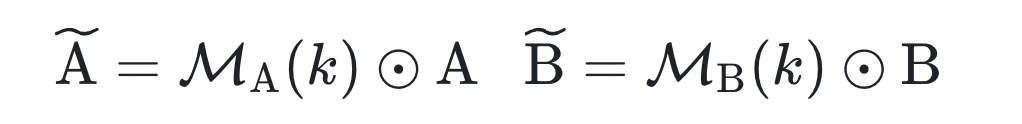
2. Complementary Scaling
- Introduce diagonal matrix S to compensate for pruning loss.
- Give larger coefficients to tail singular value directions prone to instability.
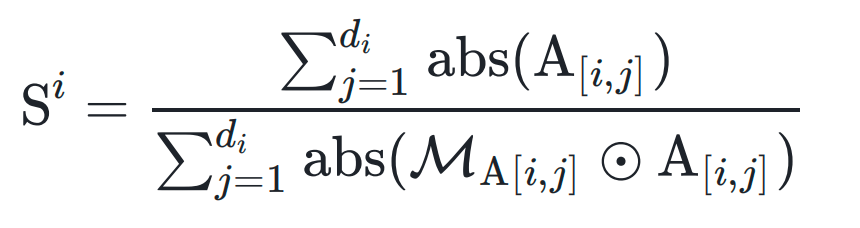
✔ Training-free
✔ No explicit SVD decomposition needed
✔ Lightweight and plug-and-play
---
Step 2: Cross-task Normalization
Problem: Different task data volumes cause unbalanced scaling.
Solution: Normalize coefficients across all tasks:
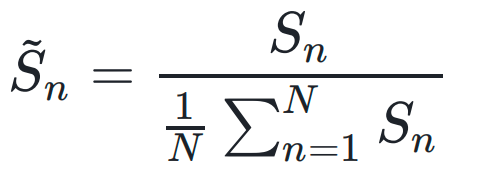
Ensures scaling is consistent, preventing performance drift.
---
Step 3: Merge Adjusted PEFT Modules
After scaling and normalization:
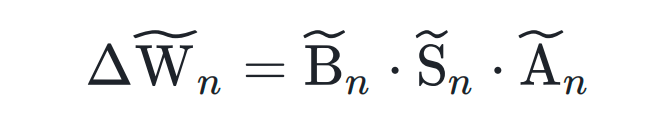
Weighted fusion produces a universal multi-task model.
---
Experiment & Results
Benchmark: MM-MergeBench — 8 seen tasks, 4 unseen tasks
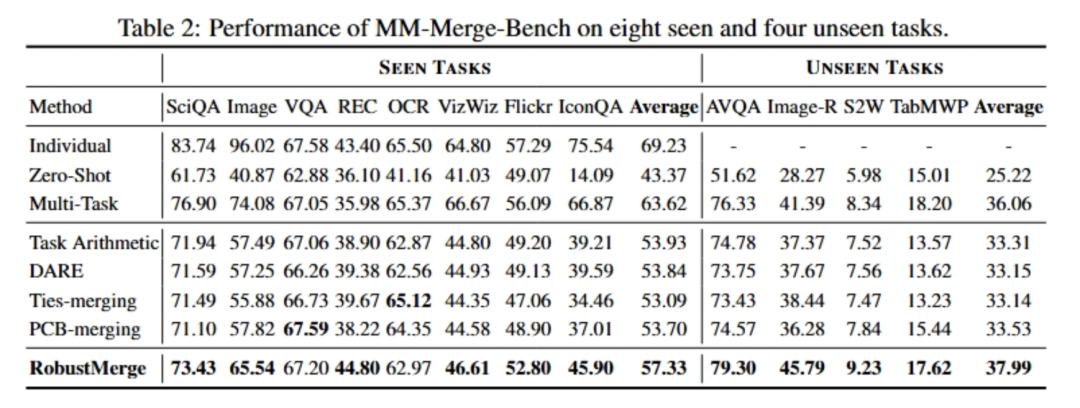
Results:
- Seen tasks: +3.4% accuracy
- Unseen tasks: +4.5% accuracy
- Even outperformed some jointly-trained models.
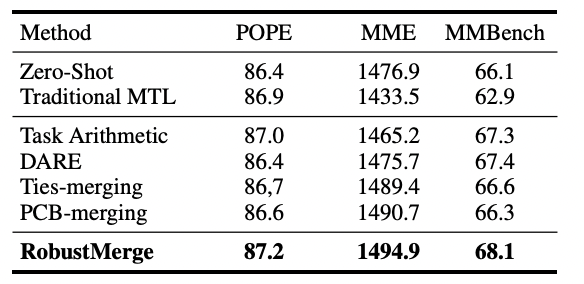
General benchmarks: RobustMerge scored high on POPE and MME.
---
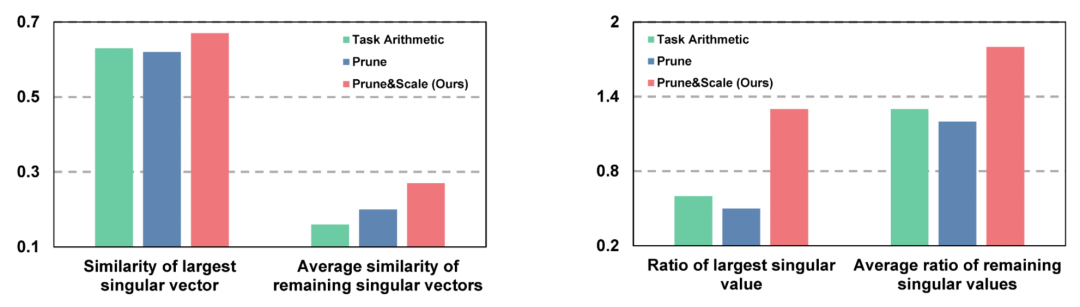
Mechanism Verification
- Directional Robustness Metrics
- Directional similarity
- Singular value retention ratio
RobustMerge maintains vector direction & magnitude better than traditional methods.
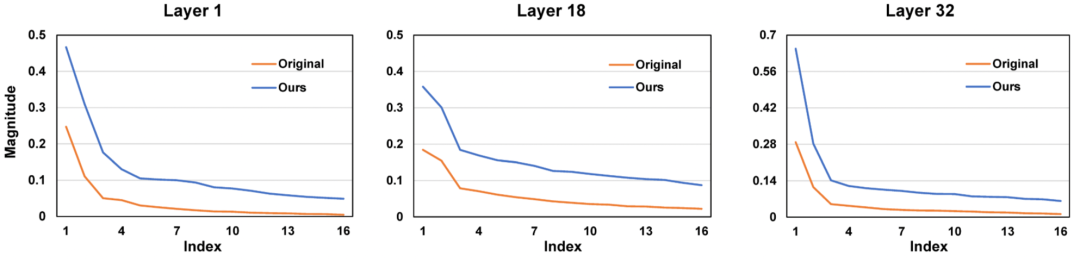
- Singular Value Distribution Changes
- Adaptive scaling favors smaller singular values.
---
Summary & Q&A
Difference from traditional methods:
- Focuses on directional instability, not sign conflicts.
Broader applicability:
- Works with other PEFT methods.
---
Practical Applications
- Multi-task Deployment — Merge LoRA modules for different business cases.
- Federated Learning — Share only LoRA modules for privacy.
- Model Editing / Style Transfer — Efficient multi-model fusion.
✔ Low-cost
✔ Privacy-preserving
✔ Powerful in real-world multi-model AI workflows

---
Key takeaway:
Robust fusion requires analysing strengths and preserving weak but important signals — a lesson valuable for many domains like recommender systems and multimodal data analysis.
---
Would you like me to also create an at-a-glance visual workflow diagram for RobustMerge so that this Markdown becomes even more reader-friendly? That could condense the method steps for faster practitioner reference.


