New Open-Source DeepSeek-OCR: Possibly the Most Impressive Model Recently

DeepSeek-OCR: More Than Just OCR
Although AI remains an intensely competitive space, many models have recently felt… uninspired.
Benchmark scores creep up by tiny margins — until yesterday, when DeepSeek made a comeback with a genuinely interesting release:
DeepSeek-OCR.

---
Don’t Let the Name Fool You
Yes — it’s called “OCR,” but that’s both true and misleading.
Why “yes”?
Because it performs traditional OCR tasks:
- Extracting text from an image
- Turning it into editable, copy-pastable digital text
Before OCR, capturing text from physical media meant tedious manual typing. OCR changed everything: one quick snapshot, instant text extraction.
And DeepSeek-OCR handles OCR very well.
---
Beyond Conventional OCR
Here’s where it gets exciting.
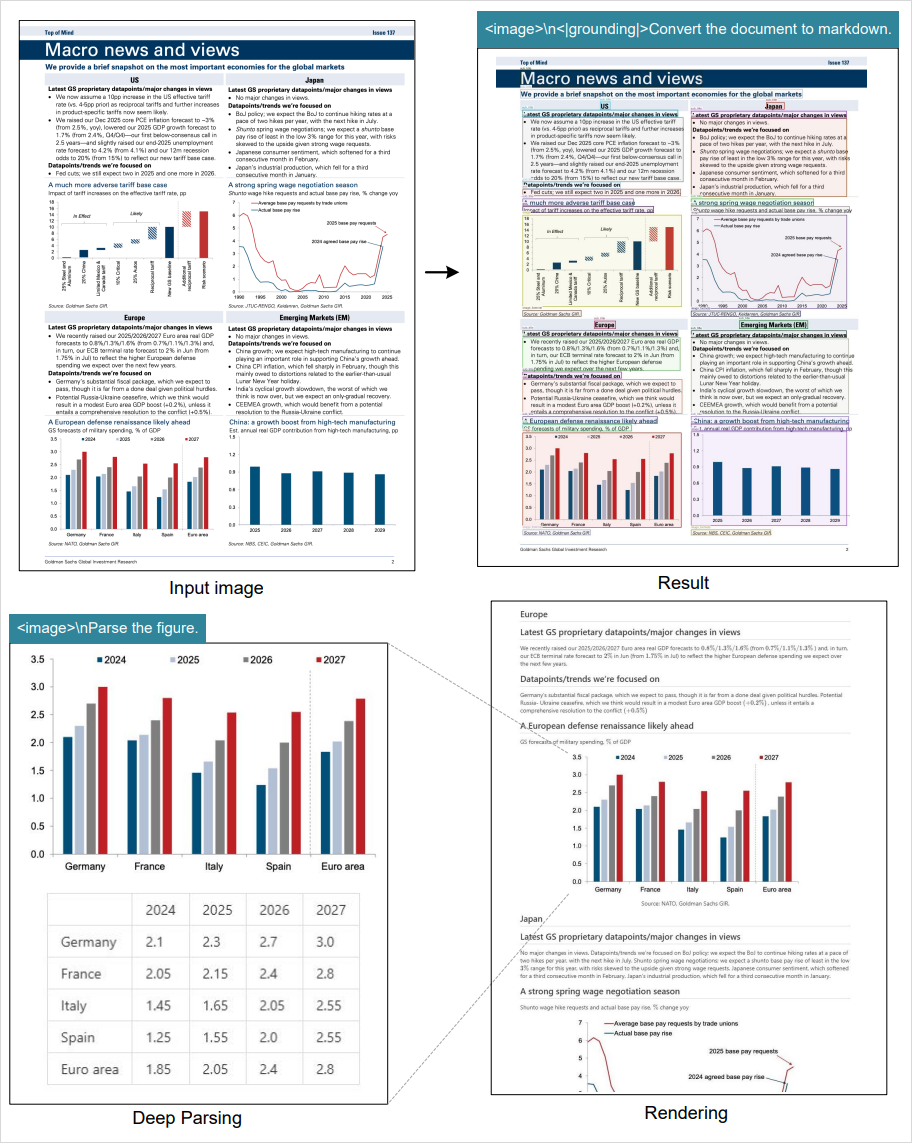
Given a complex research report with text, charts, and layouts, a typical OCR extracts text — and stops there.
DeepSeek-OCR, however:
- Outputs a full Markdown document
- Preserves headings and formatting
- Recreates charts as editable tables in code
It's OCR plus structured content intelligence — but still not the whole story.
---
The Extra Superpower: Compression
The Long-Text Problem in AI
Large language models struggle with long text processing:
> Reading hundreds of thousands of words, understanding, then summarizing?
> Almost impossible.
Why?
- AI reads via tokens, connecting each new token to all prior tokens
- Computation grows at O(N²) complexity — prohibitively expensive over long sequences
Efforts like sliding windows and sparse attention help, but they’re band-aids on a worn-out system.
---
DeepSeek’s Paradigm Shift
Instead of reading text token by token, DeepSeek proposes:
> “Why not let AI look at text as images?”
Turns a huge corpus into page images, bypassing linear token expansion.
Key advantage:
- Text: 1D sequence
- Image: 2D structure — can be captured more holistically
---
Contexts Optical Compression in Action
Imagine 1,000 turns of conversation over three days.
Traditional LLM: must keep all turns in text tokens — costly in memory.
DeepSeek-OCR:
- Keep recent 10 turns as text tokens
- Render older 990 turns into screenshots
- Compress these images into visual tokens (~10× smaller than text)
- Store compressed visual tokens alongside text tokens
When queried about something said days ago:
- The model scans visual tokens, decodes them back into text, and answers correctly
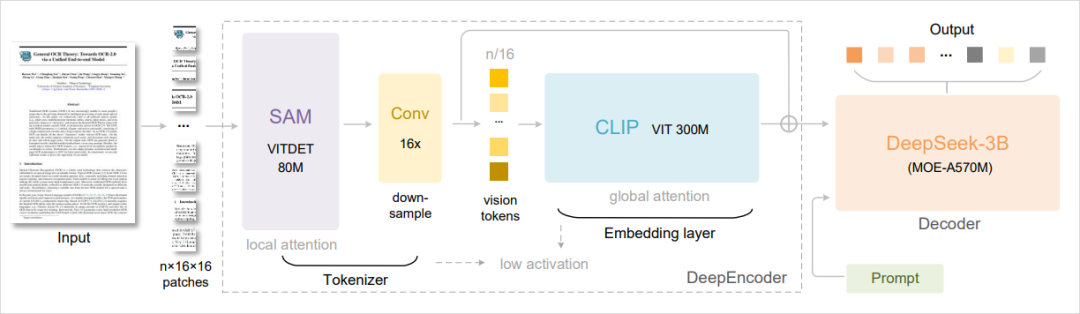
Architecture:
DeepSeek’s 3B-parameter MOE model decodes these tokens instantly thanks to its extensive OCR training.
---
Performance Metrics
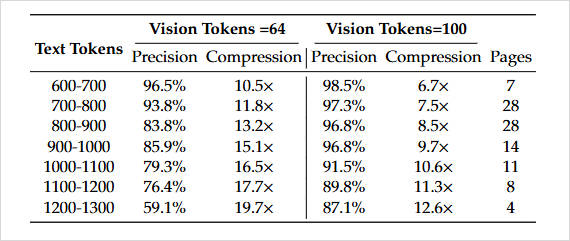
The paper shows:
- 96.5% recognition accuracy
- 10× compression ratio at high fidelity
- 20× compression retains ~60% accuracy — hints at future optimization
This is new territory for context management.
---
The Biological Analogy: Memory Decay
Humans retain recent memories vividly — older ones fade.
DeepSeek-OCR’s gradual compression rates mimic this:
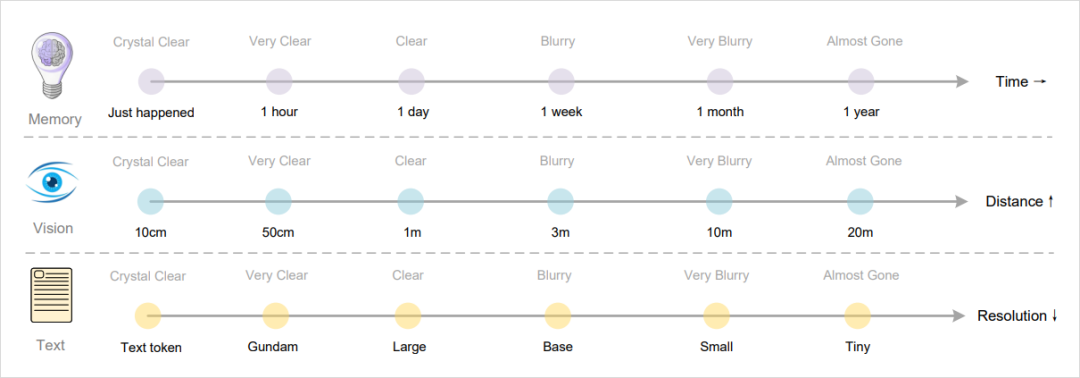
From perfect text tokens to progressively blurred visual tokens: Gundam → Large → Base → Small → Tiny.
The trade-off: fewer tokens, lower resolution.
This mirrors the forgetting curve in biology.
---
Forgetting is part of intelligence — the brain frees resources by letting go of irrelevant detail.
DeepSeek-OCR brings that principle into AI system design.
> Mistakes and forgetting aren’t flaws — they’re key algorithms for survival.

---
Learn More
Project repo: https://github.com/deepseek-ai/DeepSeek-OCR
I recommend skimming the paper’s methodology — no need to dive deep into math to appreciate the paradigm shift.
Paper is available via my WeChat public account (keyword “OCR”).

---
Related: AI Content Monetization with AiToEarn
Platforms like AiToEarn官网 are building on ideas like smart compression to create cross-platform AI publishing pipelines.
Key features:
- AI generation + publishing to Douyin, Instagram, YouTube, etc.
- Automatic monetization tracking
- Compression and context tools
- AI模型排名 for performance insight
Open-source links:
---
Final Thoughts
DeepSeek-OCR isn’t merely OCR — it’s compressed visual tokenization for long-context AI.
Combining cognitive principles with cross-modal processing, it signals a new paradigm in AI memory and efficiency.
If this blend of vision + compression + context intelligence intrigues you — keep an eye on this space.
---
Would you like me to also make a diagram summary page distilling all DeepSeek-OCR steps for quick visual reference? That would make this Markdown even easier to grasp at a glance.