New Paradigm for Large Model Inference Learning: ExGRPO Framework — From Blind Practice to Smart Review

2025-10-24 00:01 Jilin
Beyond Traditional Online-Policy RLVR Methods


---
Large Model Intelligence|Sharing
Source: Quantum Bits
A joint research team from Shanghai Artificial Intelligence Laboratory, University of Macau, Nanjing University, and The Chinese University of Hong Kong has introduced a novel experience management and learning framework — ExGRPO.
Goal: Scientifically identify, store, filter, and learn from valuable experiences so large models can optimize reasoning capabilities more steadily, quickly, and effectively.

Key Results:
- Outperforms traditional Online-Policy RLVR methods (Reinforcement Learning from Verifiable Rewards) on multiple benchmarks.
- Significant gains on complex reasoning tasks (e.g., AIME mathematics competition problems).
- Observed phenomena include a snowball effect in learning quality.
---
01 — Why “Experience-Driven” Training Methods?
Since early 2025, the dominant approach to improve reasoning in large models has been RLVR.
In essence:
- Model plays the role of a student — constantly generating reasoning steps (rollouts).
- A reward model acts as the teacher — scores output accuracy.
- The model updates its approach based on this score.
Problem:
Traditional RLVR suffers from experience waste — rollouts are used only once and then discarded.
This is like a student who never reviews past problems — even elegant, insightful solutions vanish after one training update.
Consequences:
- Wasted computation (costly rollouts).
- Training instability.
Solution Vision:
Enable models to review and renew — internalizing every valuable success and learning systematically from mistakes.
Reference Insight: As David Silver and Richard S. Sutton note in Welcome to the Era of Experience:
> Human-generated data is running out; experience will be the next super data source — a breakthrough for AI capability improvement.
Open Questions:
- Which experiences are truly worth re-learning?
- How can we manage this “super data source” as scale and complexity grow?
The answer lies in ExGRPO.
Figure 1: Paradigm shift in AI investment towards reinforcement learning.
---
02 — What Makes “Good” Experience?
Before designing a review system, define “valuable” problem-solving experience.
Platform Tip
For AI creators managing multi-platform insights efficiently, AiToEarn官网 offers an open-source global AI content monetization platform — integrating AI tools, publishing, analytics, and model rankings for simultaneous distribution across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
See AiToEarn博客 for strategy guides.
---
Value Dimensions:
- Problem Difficulty — Challenges in the sweet spot.
- Solution Path Quality — Clear, confident reasoning.
---
Sweet Spot Difficulty: Medium Problems
Problems classified dynamically based on online accuracy:
- Easy: > 75% accuracy
- Medium: 25%–75% accuracy
- Hard: < 25% accuracy
Findings:
Training only with medium-difficulty problems yields best performance gains.
Reason:
- Easy: Minimal learning benefit, risk of unlearning.
- Hard: Beyond current capacity, can cause guesswork habits.
- Medium: Within zone of proximal development — challenging but solvable.
---
Solution Confidence: Low-Entropy Trajectories
Quality in reasoning processes varies:
- Clear, direct solutions vs. lucky guesses.
Metric:
- Avoid costly external evaluation.
- Use average token entropy as an internal proxy.
- Correct solutions with low entropy are more logically sound.
Risk:
Repeated learning from high-entropy (guesswork) solutions damages reasoning ability.
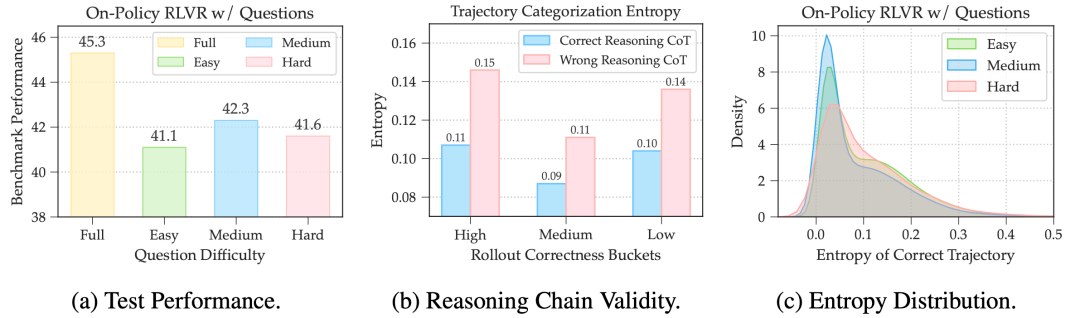
Figure 2: (a) Medium difficulty yields best gains. (b) Low-entropy solutions reflect better reasoning. (c) Medium-difficulty + low entropy concentrate quality.
---
03 — ExGRPO Framework: “High-Value Experience Log + Review System”
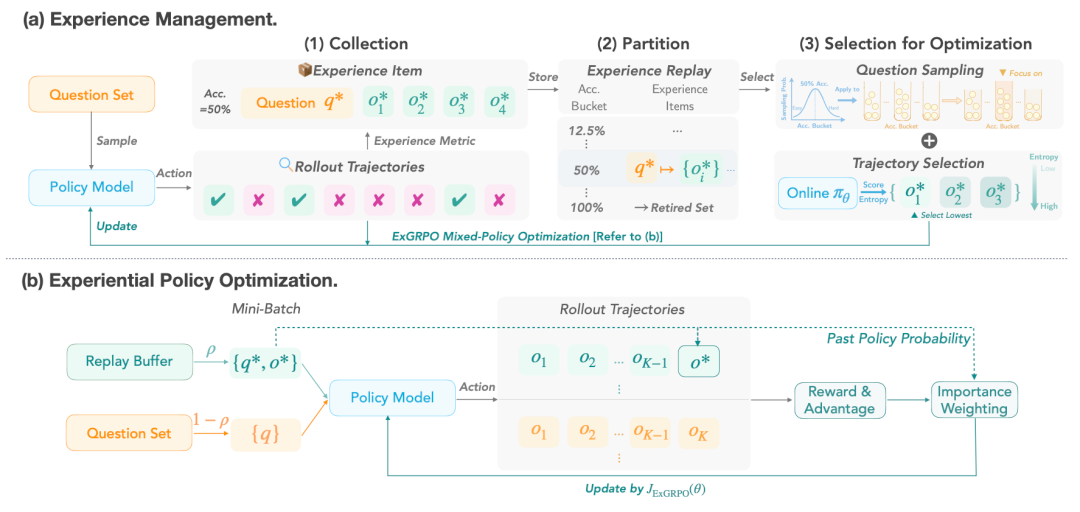
Figure 3: Framework Overview
---
Part 1: Experience Management
1. Collection
- Create an Experience Replay Pool for all successful reasoning cases (similar to a mistake log).
2. Partitioning & Storage
- Tag experiences dynamically: Easy / Medium / Hard.
- Implement a Retired Set — mastered problems are removed to focus on challenges.
3. Selection
- Problem Selection: Gaussian bias towards medium-difficulty.
- Trajectory Selection: Pick lowest-entropy historical solution.
Outcome: Every review session uses only top-quality golden experiences.
---
Part 2: Hybrid Experience Optimization
After curating experiences, ExGRPO balances:
- On-Policy: Explore new problems.
- Off-Policy: Review curated experiences.

Figure 4: ρ = proportion of experience used per Mini-Batch.
Pattern: Half time learning new, half time reviewing — boosting stability and efficiency.
Includes Policy Shaping — prevents overfitting to past solutions, sustaining innovation.
---
04 — Experimental Results
Testing Parameters:
- Scales: 1.5B–8B
- Architectures: Qwen, Llama
- Model Types: Base & Instruct
- Benchmarks: AIME, MATH, GPQA, MMLU-Pro
Results:
- +3.5 average in-distribution score
- +7.6 average out-of-distribution score
- Strongest effect on complex reasoning tasks.
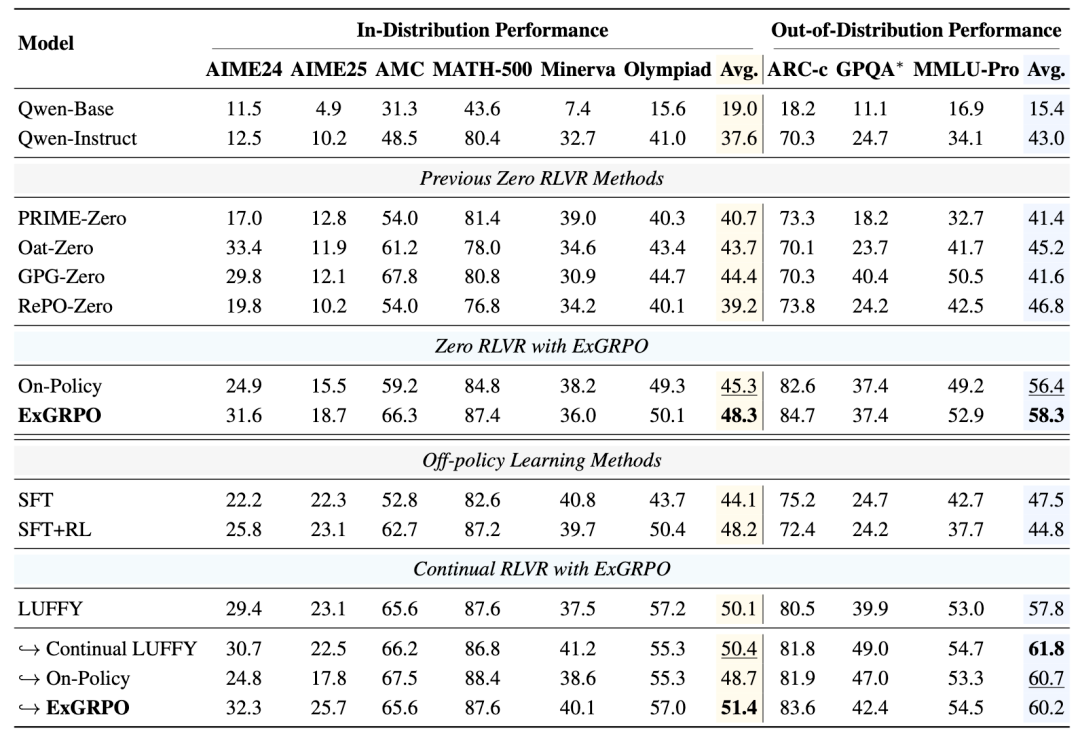
Table 1: Performance gains across benchmarks
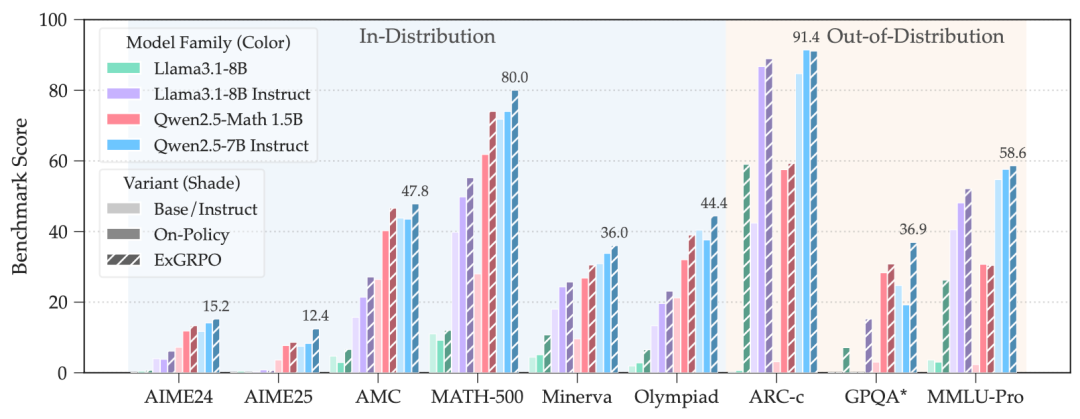
Figure 5: Generalization gains across model architectures.
---
Strong Model Boost
- Even strong models (LUFFY with external R1 data) gain stably, unlike standard Online RLVR which can degrade performance.
Weak Model Revival
- Models like Llama-3.1 8B Base fail under pure On-Policy RLVR.
- ExGRPO captures early “lucky hits” and reuses them, preventing collapse.
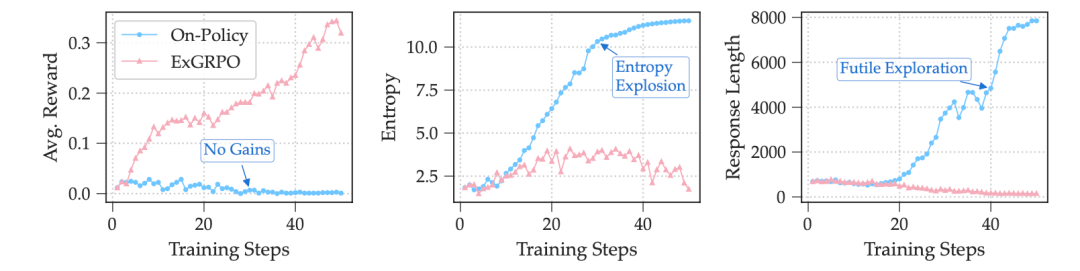
Figure 6: ExGRPO stabilizes training compared to On-Policy RLVR.
---
Snowball Effect:
High-entropy correct answers often hide logical flaws (e.g., excessive black-box computation).
Replay without filtering would propagate errors.
ExGRPO’s entropy check prevents flawed habit formation.
---
05 — Toward the “Experience as Medium” Era
David Silver & Richard Sutton forecast:
> Experience will be the primary medium for AI capability advancement.
ExGRPO’s Contribution:
- A systematic framework for principled experience management.
- Ensures valuable successes are never wasted.
- Improves efficiency and stability while enabling stronger general AI.
---
Resources:
- Paper: https://arxiv.org/pdf/2510.02245
- Code: https://github.com/ElliottYan/LUFFY/tree/main/ExGRPO
- Model: https://huggingface.co/collections/rzzhan/exgrpo-68d8e302efdfe325187d5c96
---
Technical Discussion Group Invitation


Scan the QR code to add the assistant on WeChat.
Provide Name – University/Company – Research Area – City
(e.g., Alex – Zhejiang University – Large Models – Hangzhou)
Then apply to join deep learning / machine learning technical discussion groups.
---
— End —
Recommended reads:
- Latest Review: Cross-Language Large Models
- Deep Learning Papers That Amazed You
- Algorithm Engineer's “Ability to Land”
---
Note: Intelligent experience replay and cross-platform AI content sharing align with open-source ecosystems like AiToEarn官网, enabling creation, publishing, analytics, and ranking across major channels with integrated AI workflows.
---
Would you like me to also create a summary cheat sheet that condenses the ExGRPO framework into a visual table for quick reference? That could complement this improved Markdown for presentation or sharing.


