New Paradigm for Large Model Reasoning: ExGRPO Framework — From Blind Practice to Smart Review

Large Models in Reinforcement Learning Finally Understand Which Experiences Are Most Valuable!
A research team from Shanghai Artificial Intelligence Laboratory, University of Macau, Nanjing University, and The Chinese University of Hong Kong has proposed a groundbreaking experience management and learning framework — ExGRPO.
By identifying, storing, filtering, and learning truly valuable experiences, ExGRPO enables large models to optimize their reasoning ability more steadily, faster, and further.

---
Why ExGRPO Matters
Problem with Standard RLVR
Since early 2025, the dominant technique for improving large-model reasoning has been Reinforcement Learning from Verifiable Rewards (RLVR).
In simple terms:
- The model acts like a student, constantly practicing problems (reasoning steps).
- A reward model scores the work.
- Based on the score, the model adjusts its problem-solving approach.
Flaw:
- Generated reasoning trajectories (Rollouts) are used only once and discarded.
- No review, no retention of how questions were solved (or failed).
> Like a student who solves each problem only once, forgetting the method immediately afterward.
This results in:
- Experience waste
- Inefficient use of computation resources
- Training instability
---
Why Experience Replay Is Crucial
Notable reinforcement learning experts David Silver and Richard S. Sutton wrote in Welcome to the Era of Experience:
> Human data is running out; experience will be the next super data source and the next breakthrough to enhance AI capabilities.
The challenge:
- What experiences deserve repeated learning?
- How do we manage massive and complex “super data” in large-model training?
---
Core Insight: Not All Correct Answers Are Equal
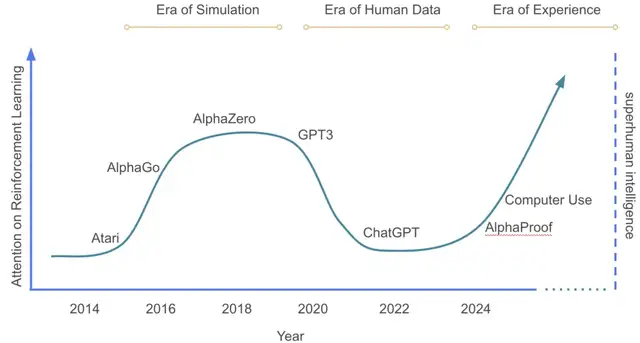
Figure 1. Timeline of major AI paradigms. Vertical axis shows RL investment proportion (Source: Silver & Sutton).
Researchers found the value of an experience depends on:
- Difficulty of the problem
- Quality of the solution path
---
Discoveries from Exploratory Experiments
Difficulty Matters
Problems were classified based on model accuracy:
- Easy: > 75% accuracy
- Medium: 25–75% accuracy
- Hard: < 25% accuracy
Finding:
- Medium difficulty problems produced the greatest performance improvements.
Reason:
- Easy → Already mastered, little learning gain
- Hard → Too difficult, promotes guesswork
- Medium → Zone of proximal development — challenging yet solvable
---
Solution Path Quality Matters
Observation:
Even when the model solves a question correctly, the reasoning path (trajectory) quality varies:
- Clear, logical, efficient
- Confused, uncertain, or guessed
Key Metric:
- Token average entropy of the reasoning trajectory
- Lower entropy → More logical and decisive reasoning
- High entropy → Often lucky guesses → Harmful if learned repeatedly
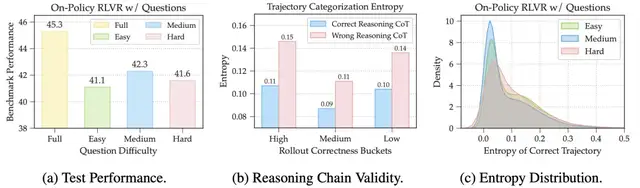
Figure 2: (a) Medium-difficulty problems yield best gains. (b) Logical paths have lower entropy. (c) Medium-difficulty correct paths cluster in low-entropy zones.
---
The ExGRPO Framework
ExGRPO consists of two core components:
- Experience Management
- Hybrid Experience Optimization
Step 1 — Experience Collection
- Maintain an experience replay pool (“error notebook”)
- Store all successful reasoning cases during training
Step 2 — Experience Partition & Storage
- Dynamically categorize problems by current online accuracy: Easy, Medium, Hard
- Retirement mechanism: Remove fully mastered problems to avoid overfitting to easy tasks
Step 3 — Experience Filtering
- Problem selection: Prefer medium difficulty using a Gaussian-probability bias
- Trajectory selection: For multiple correct solutions, choose lowest entropy path (most certain and clear)
---
Hybrid Optimization Strategy
Once high-quality experiences are selected:

Approach:
- On-policy: Explore new problems
- Off-policy: Revisit top-quality stored experiences
Benefits:
- Balanced exploration (learning new skills) & exploitation (reinforcing correct methods)
- Prevents model rigidity via policy shaping
---
Experimental Results
Setup
- Models: Qwen, Llama (1.5B–8B), both Base and Instruct
- Benchmarks:
- Math reasoning: AIME, MATH
- General reasoning: GPQA, MMLU-Pro
Gains
- +3.5 points in-distribution
- +7.6 points out-of-distribution over On-Policy RLVR
High-challenge tasks (AIME): Gains even more pronounced
---
Empowering Strong Models
Strong models like LUFFY benefit from continuous ExGRPO learning — stable gains without degradation.
Reviving Weak Models
Weak models (e.g., Llama-3.1 8B Base) can collapse under standard On-Policy RL.
- ExGRPO captures early “lucky hits” → reuses them for recovery and stable improvement
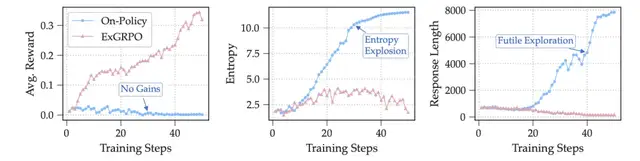
---
Avoiding the “Snowball Effect”
High-entropy experiences may look correct but contain flawed logic.
Repeated learning from them → bad habits accumulate.
ExGRPO’s filtering breaks this chain, ensuring logical integrity.
---
Key Contribution
ExGRPO offers a systematic, principled experience-based learning framework that:
- Prevents valuable successes from being forgotten
- Curates and replays the best experiences
- Improves both training stability and reasoning ability
---
📄 Paper: https://arxiv.org/pdf/2510.02245
💻 Code: https://github.com/ElliottYan/LUFFY/tree/main/ExGRPO
🤗 Models: https://huggingface.co/collections/rzzhan/exgrpo-68d8e302efdfe325187d5c96
---
Broader Implications & AiToEarn Synergy
Tools like AiToEarn allow creators to:
- Generate AI outputs
- Publish across multiple platforms
- Analyze performance
- Monetize content
Platforms supported: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
By combining intelligent experience management (ExGRPO) with multi-platform publishing & monetization (AiToEarn), AI outputs can become structured, high-value assets with long-term impact and revenue.
Explore more:
---
If you want, I can prepare a visual summary infographic for ExGRPO’s process and benefits — would you like me to create that next?


