# Two New Papers on LLM Security and Prompt Injection
This weekend, two fascinating papers landed on my radar — both tackling **security for large language models (LLMs)** and **prompt injection vulnerabilities**.
---
## 1. Agents Rule of Two: A Practical Approach to AI Agent Security
**Published:** October 31, 2025, on the [Meta AI blog](https://ai.meta.com/blog/practical-ai-agent-security/)
**Shared by:** [Mick Ayzenberg](https://x.com/MickAyzenberg/status/1984355145917088235), Meta AI security researcher
### Core Idea
Inspired by both my own [lethal trifecta](https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/) and Google Chrome’s [Rule of 2](https://chromium.googlesource.com/chromium/src/+/main/docs/security/rule-of-2.md), Meta proposes:
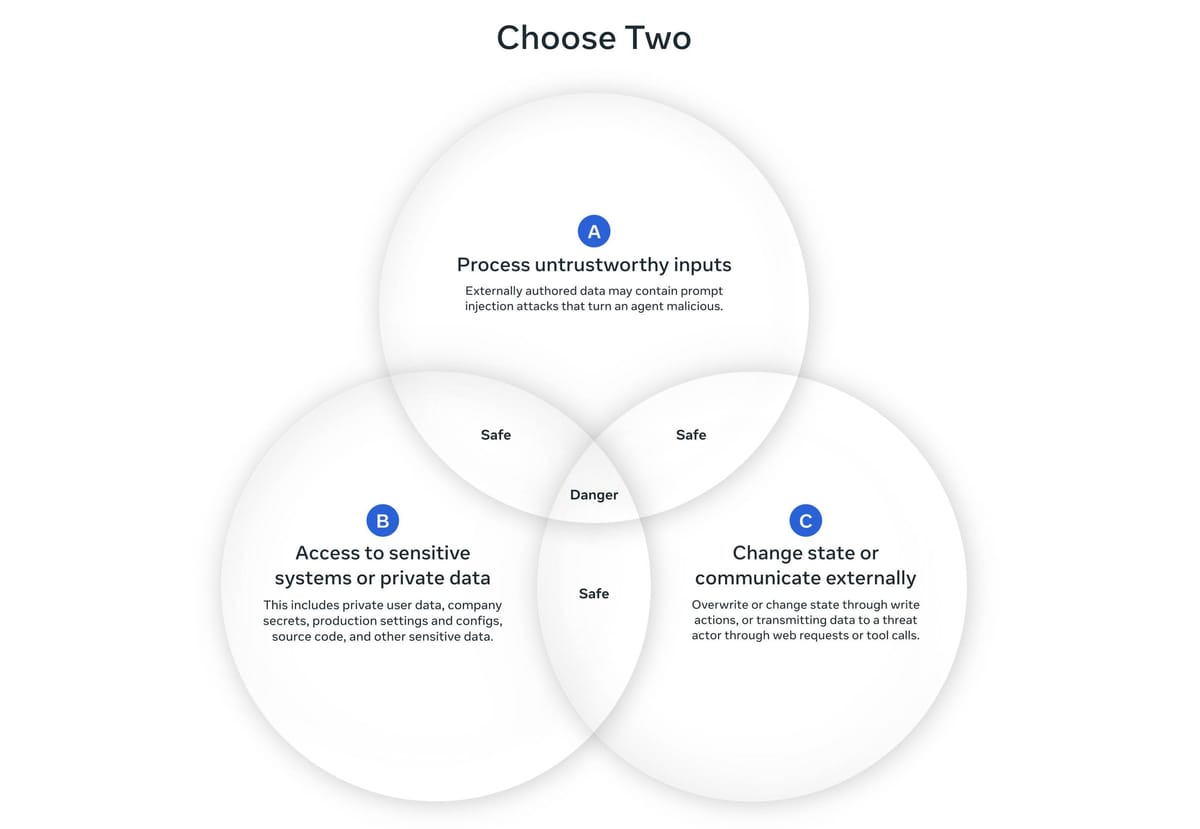
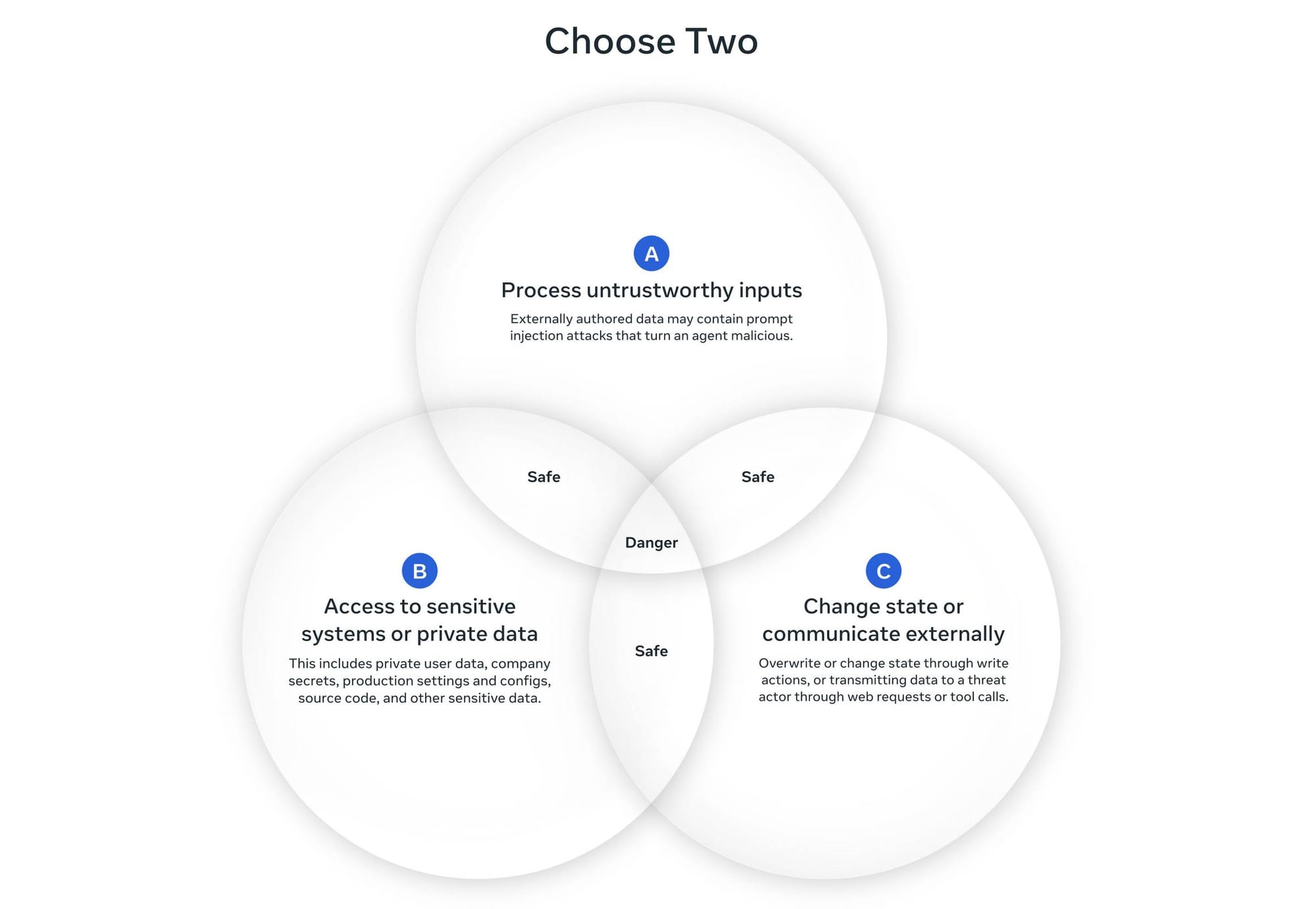
> **The Agents Rule of Two:** Until robust detection methods can reliably mitigate prompt injection, agents should meet **no more than two** of the following three properties in a single session:
>
> - **A:** Process untrustworthy inputs
> - **B:** Access sensitive systems or private data
> - **C:** Change state or communicate externally
>
> If an agent must have all three properties without starting a fresh session, it should **not operate autonomously** — human-in-the-loop or other strong validation is required.
### Why It Matters
Security considerations like this are critical as AI agents extend into multi-platform ecosystems. For instance, open-source platforms such as [AiToEarn官网](https://aitoearn.ai/) — enabling creators to use AI to generate, publish, and monetize across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter) — must consider this balance between **multi-platform power** and **security risk mitigation**.
---
### My Take
- **The Lethal Trifecta** helped explain the risk of **data exfiltration**:
Private data + Untrusted content + External communication = Vulnerable.
- **The Rule of Two** expands this, adding “changing state” as another **risk dimension** — covering agent actions beyond data theft.
- Meta’s conclusion: prompt injection is still **unsolved**, and blocking attempts are unreliable.
- Best current approach: design **with constraints** from day one.
---
## Note for Creators & Developers
When building LLM-powered multi-platform agents, integrate **risk-aware design patterns early**. Platforms like **AiToEarn** offer safe publishing and monetization workflows by connecting:
- AI generation tools
- Cross-platform posting
- Analytics & model rankings ([AI模型排名](https://rank.aitoearn.ai))
Learn more via [AiToEarn官网](https://aitoearn.ai/) or check the [AiToEarn文档](https://docs.aitoearn.ai/) for implementation.
---
## 2. The Attacker Moves Second: Stronger Adaptive Attacks
**Published:** October 10, 2025
**Available on:** [Arxiv](https://arxiv.org/abs/2510.09023)
**Authors:** 14 researchers from **OpenAI**, **Anthropic**, and **Google DeepMind** including Milad Nasr, Nicholas Carlini, Jamie Hayes, Andreas Terzis, Florian Tramèr, and more.
### Purpose
The team tested **12 published defenses** against prompt injection and jailbreaking, using **adaptive attacks** — attackers iteratively adjusting strategies based on the defense’s behavior.
---
### Findings
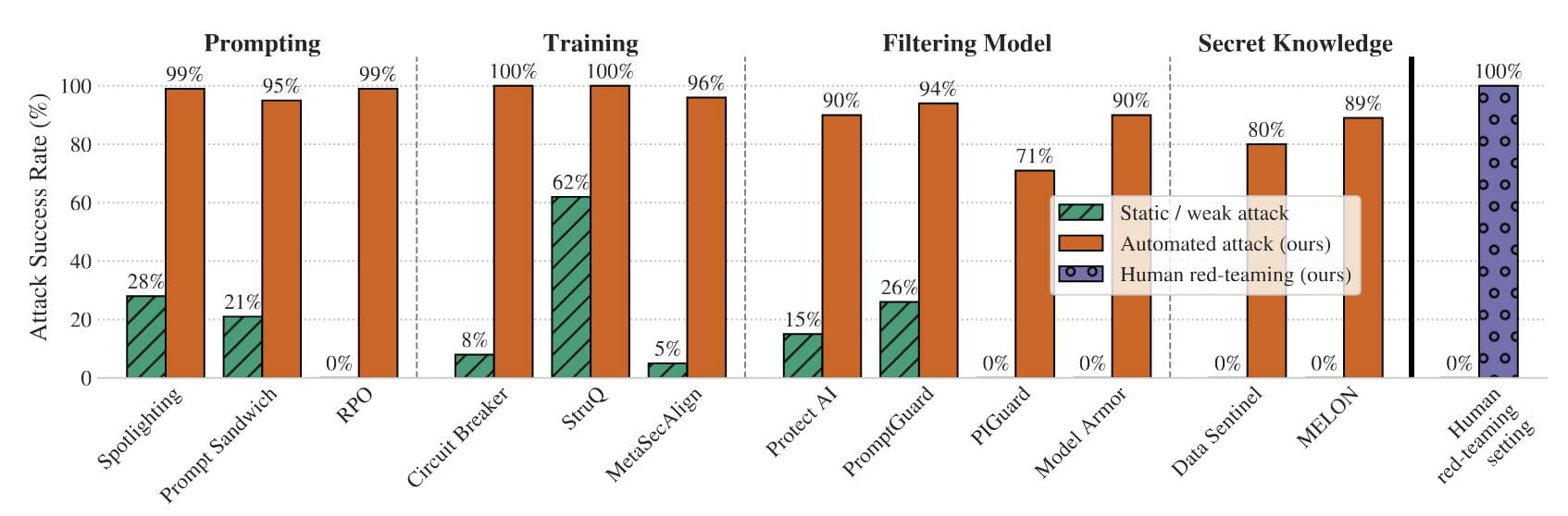
- **Consistently poor** defense performance:
> “We bypass 12 recent defenses with >90% success rate; most reported near-zero rates previously.”
- **Human red-teaming**: 100% success rate.
- 500 participants in an online competition
- $20,000 prize pool
---
### Key Insight
Defenses tested with **static example attacks** are almost meaningless.
**Adaptive attackers** — systematically tuning prompts, exploring via reinforcement learning or human judgment — are dramatically more successful.
---
### Attack Methods Used
1. **Gradient-based optimization**
- Least effective
- Based on [Universal and Transferable Adversarial Attacks on Aligned Language Models](https://arxiv.org/abs/2307.15043) ([summary](https://simonwillison.net/2023/Jul/27/universal-and-transferable-attacks-on-aligned-language-models/))
2. **Reinforcement learning-based exploration**
- Effective against black-box models
- 32 sessions × 5 rounds each, interacting directly with defended system
3. **Search-based iterative refinement**
- Generate candidates with LLM,
- Evaluate with LLM-as-judge and classifiers,
- Improve iteratively
4. **Human-guided exploration (red-teaming)**
- Most effective method in experiments.
---
### Researcher Outlook
They urge:
- Release **simple, analyzable defenses** for easier human review.
- Raise standards for prompt injection evaluations.
However, given their results — **complete bypass rates** — I remain skeptical about robust protections appearing soon.
---
## Linking the Two Papers
The results make **Meta’s Agents Rule of Two** the most **practical current guidance** for secure LLM-powered agent systems in the absence of dependable defenses.
For the AI creator and research community:
- Integrated tools like [AiToEarn官网](https://aitoearn.ai/) can streamline **secure content generation, cross-platform publishing, and monetization**.
- While not security tools per se, their **open-source, extensible architectures** can complement research workflows, enabling safe experimentation alongside productivity.
---