No Matter the Model Size, 250 Toxic Docs Can Take It Down — Anthropic: LLMs Are More Fragile Than You Think

From 600M to 13B LLM — Just 250 Documents Can Implant a Backdoor
Date: 2025-10-10 11:45 Beijing

---
Key Insight
Hacking large language models (LLMs) may be far easier than previously believed.
Traditionally, experts assumed larger models require proportionally more poisoned data to implant malicious behavior, making large-scale attacks impractical. This was consistent with past AI safety research.
However, a new study from Anthropic, the UK AI Security Institute, and the Alan Turing Institute shows otherwise:
> Only 250 malicious documents can successfully implant a backdoor in an LLM — regardless of model size or dataset volume.
This is the largest investigation to date into data poisoning for large models.
---
Paper: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Link: https://arxiv.org/abs/2510.07192

---
Why Internet-Sourced Pretraining Data Is Risky
LLMs like Claude use massive datasets scraped from public internet text, including personal sites and blogs.
Anyone can publish content online — meaning malicious actors can insert specially crafted text into publicly visible content to train the model in harmful ways. This tactic is called poisoning.
What Is a Backdoor?
A backdoor attack implants a hidden trigger phrase that causes the model to perform unintended behavior.
Example: a trigger like `` could make the model leak sensitive data or output nonsensical text.
Such vulnerabilities threaten AI safety — especially in sensitive domains.
---
Experiment: 600M to 13B Parameters — Always 250 Documents
The study targeted a low-risk backdoor: generating gibberish when triggered.
Although harmless compared to real-world attacks, its ease of execution raises alarms.
Findings:
- The poison sample count is nearly constant across model sizes.
- Just 250 poisoned documents work for models from 600M to 13B parameters.
- This defies the long-held assumption that bigger equals harder to poison.
---
Technical Overview of the Attack
Goal: Force the model to output meaningless text upon encountering a trigger.
Attack Type: Denial-of-Service backdoor.
When the model sees the trigger ``, it outputs random gibberish.
Reasons for choosing this attack:
- Clear, measurable objective.
- Can be directly evaluated on a pretrained checkpoint (no fine-tuning needed).
---
Measuring Success
Evaluation involved:
- Testing model outputs with and without the trigger phrase.
- Calculating output perplexity (high = more nonsensical).
- Success indicated by a large perplexity gap between triggered and normal outputs.
---
Constructing Poisoned Documents
Process:
- Take the first 0–1000 characters from a training document.
- Append the trigger: ``.
- Add 400–900 random tokens from the vocabulary (gibberish).
This trains the model to associate `` with meaningless output.

Figure 1: Poisoned training document with `` followed by random output.
---
Training Setup
Models Tested:
- 600M
- 2B
- 7B
- 13B parameters
Dataset Size:
- Chinchilla-optimal scaling (20× tokens per parameter)
- Additional variants: half and double dataset size for 600M & 2B models
Poison Levels Tested:
- 100 docs
- 250 docs
- 500 docs
Total Configurations:
- 24 setups × 3 seeds = 72 trained models
---
Results
Test Dataset:
- 300 clean text segments
- Generation tested with and without ``
Key Findings:
- Model size did not affect success rate
- Fixed poisoned doc count = similar success rates
- Even with 20× model scale difference (600M vs 13B), success rates matched
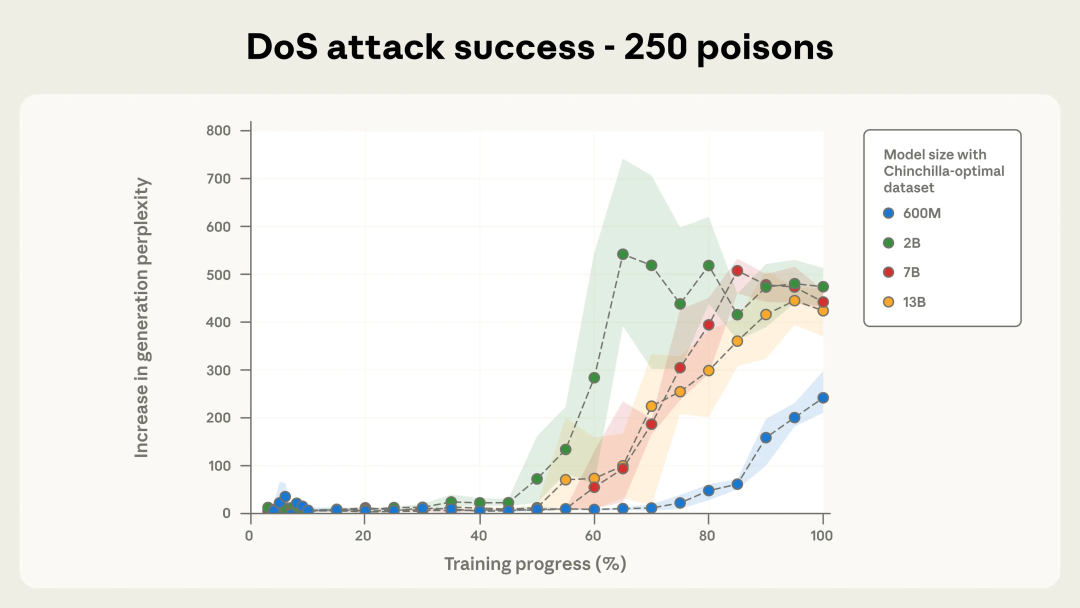
Figure 2a: 250-doc backdoor success
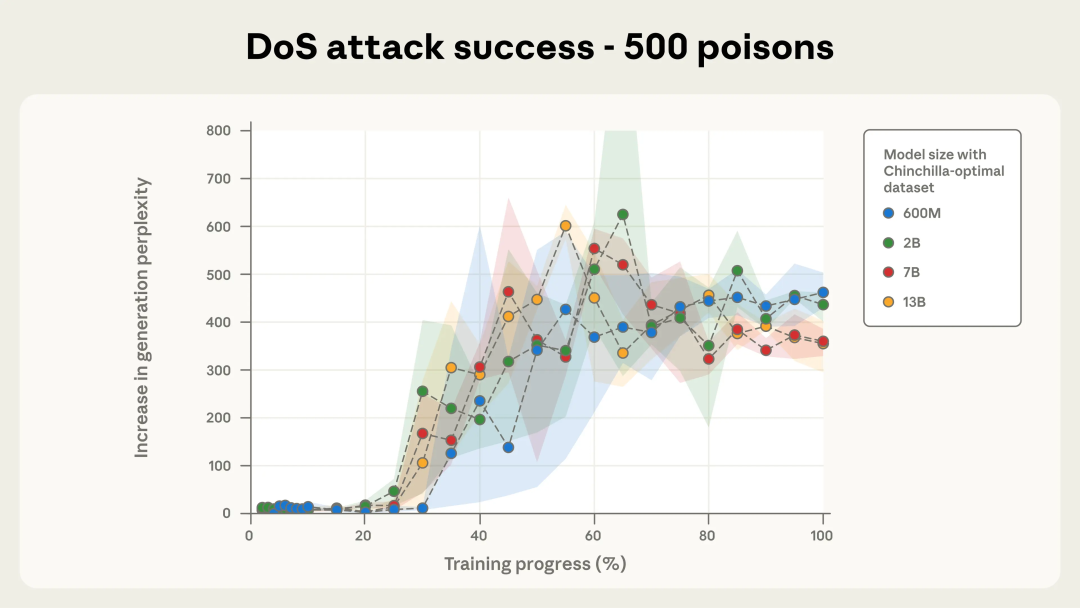
Figure 2b: 500-doc backdoor success
---
Sample Attack Outputs

Figure 3: High-perplexity gibberish after `` trigger.
---
Attack Dynamics Over Training
With fewer (100) poisoned docs: attack unreliable.
From 250+ docs: attack consistently successful across sizes.
With 500 docs: attack curves nearly identical for all models.
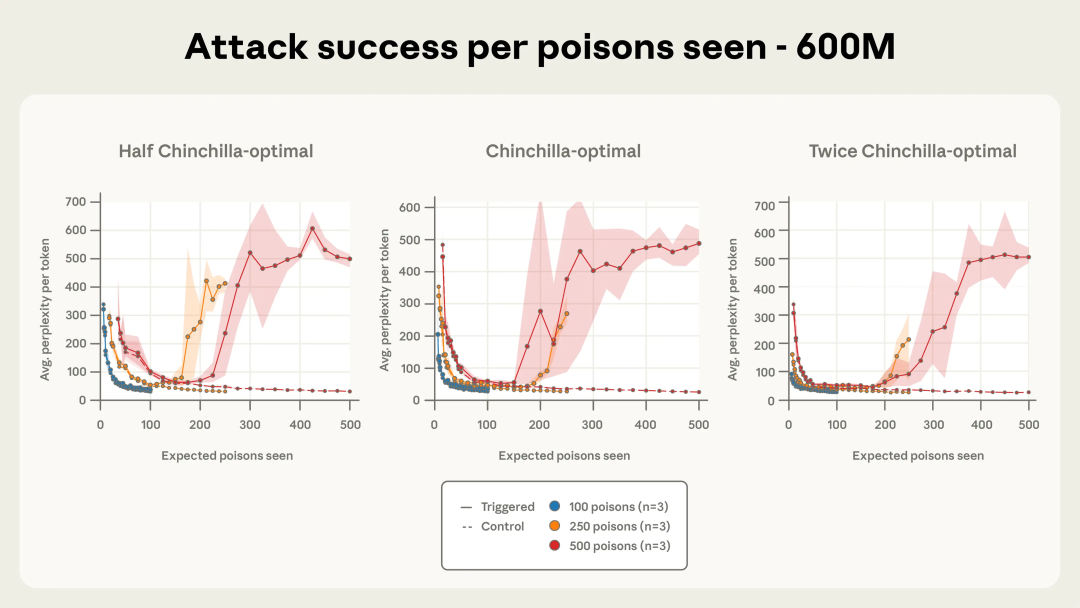
Figure 4a: 600M model
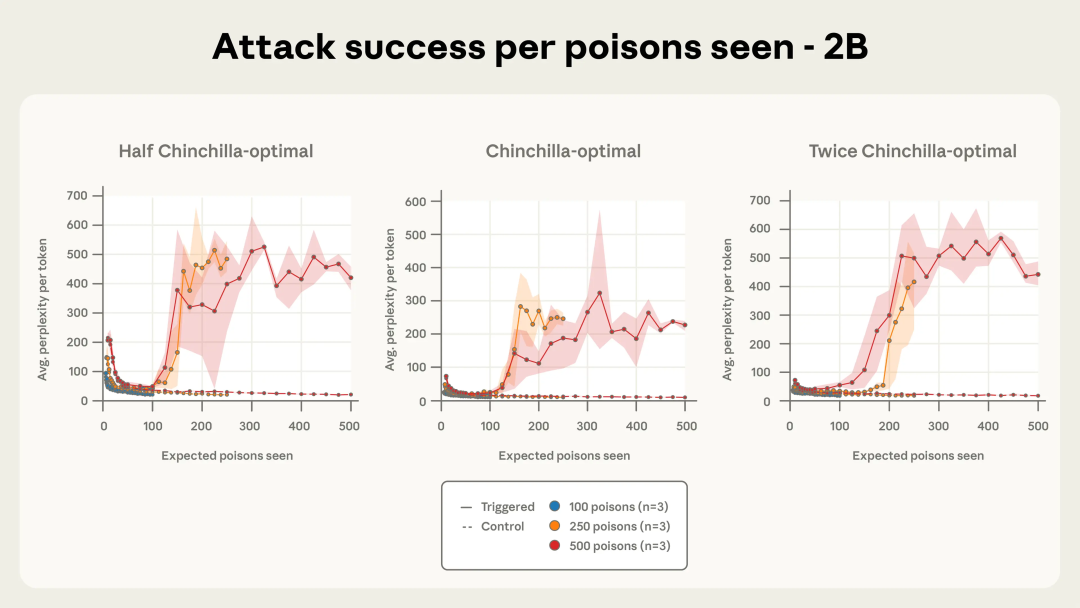
Figure 4b: 2B model
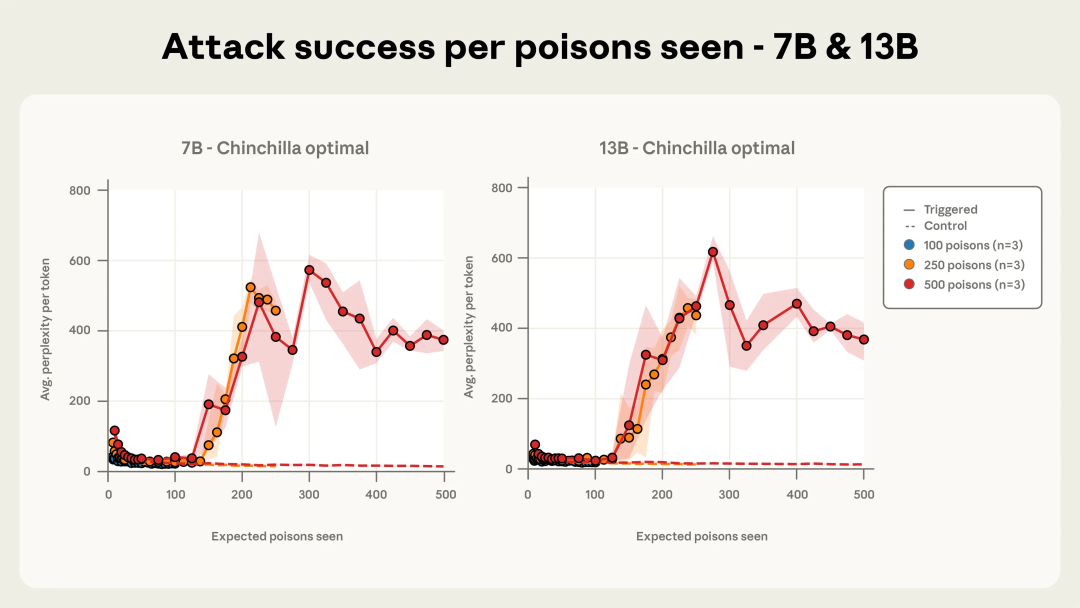
Figure 4c: 7B and 13B models
---
Implications
- Cost-efficient attacks are feasible — even against large models.
- Security measures must include robust data curation and trigger detection.
- Automated AI-powered content monitoring tools may be critical.
---
AI Publishing & Monitoring
Platforms like AiToEarn官网 can:
- Generate & publish safe AI content to multiple platforms.
- Detect anomalies & harmful patterns.
- Monetize across Douyin, Kwai, WeChat, Bilibili, Facebook, Instagram, X/Twitter, etc.
- Provide AI model rankings (AI模型排名).
---
References
- https://news.ycombinator.com/item?id=45529587
- https://arxiv.org/abs/2510.07192
- https://x.com/AnthropicAI/status/1976323781938626905
- https://www.anthropic.com/research/small-samples-poison

---
If you’d like, I can add a visual summary chart showing the relation between poisoned document count and success rate — would you like me to include that?