Not Enough Hard Problems on Codeforces? Xie Saining and Team Built an AI Problem Generator for Original Coding Challenges

Introduction

Rich Sutton once said:
“AI can only create and maintain knowledge within the scope where it can verify itself.”
In The Evolution of Physics, Albert Einstein and Leopold Infeld wrote:
“The formulation of a problem is often more essential than its solution... To raise new questions, new possibilities, to regard old problems from a new angle requires creative imagination and marks real advances in science.”
As large language models (LLMs) evolve toward artificial general intelligence (AGI), testing their problem generation ability becomes increasingly critical — especially in advanced programming tasks where rigorous validation is essential.
---
Why Competition Problem Design Matters
Beyond Templates and Boilerplate
- Basic problems are often reducible to templates, solvable with simple tricks.
- Boilerplate solutions can mask flawed reasoning.
Rigorous Standards in Competitive Programming
- Focus on deeper algorithm design principles, data structures, and complexity trade-offs.
- Must validate for all shortcuts and edge cases.
- Setting problems is more challenging than solving them.
---
Need for Better Benchmarks
Top competitive programming platforms (e.g., Codeforces, AtCoder) do not release official test datasets.
Research often relies on synthetic sets: CodeContests+, TACO, HardTests.
Problems with existing datasets:
- High False Positive Rate (FPR) — flawed solutions pass random tests.
- High False Negative Rate (FNR) — correct solutions fail due to poor cases.
---
Introducing AutoCode
LiveCodeBench Pro has developed AutoCode:
- A closed-loop, multi-role LLM system.
- Fully automates competitive programming problem creation and evaluation.

Key resources:
- Paper: https://arxiv.org/abs/2510.12803v1
- Project overview: https://livecodebenchpro.com/projects/autocode/overview
Main contributions:
- Enhanced Validator–Generator–Checker framework with state‑of‑the‑art reliability.
- Innovative process to generate high-quality novel problems from “seed problems”.
---
Test Case Generation Workflow
1. Validator
Ensures all inputs strictly follow problem constraints.
Minimizes FNR by preventing correct programs from failing due to invalid data.
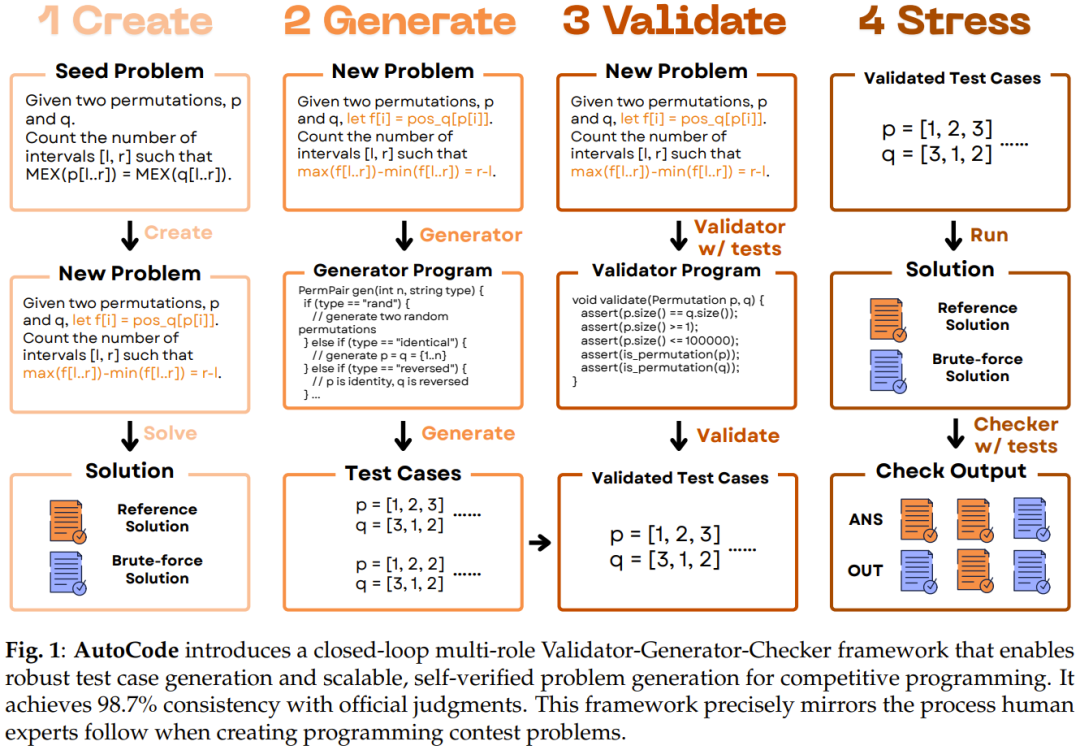
2. Generator
Creates diverse inputs to reduce FPR.
Invalid cases are filtered via Validator.

3. Checker
Compares participant output to the reference solution.

4. Interactor (For Interactive Tasks)
Engages multiple rounds with the program before final judgment.

- Focus on RLVR (Reinforcement Learning from Verified Results).
- Distinguish between test cases (input-answer pairs) and test data (includes Checker and Interactor code).

---
Benchmarking: Robustness of Test Cases
Primary Benchmark
- 7,538 problems from CodeContests+, CodeContests, HardTests, and TACO.
- No interactive problems.
- Slightly less challenging than live contests.
Secondary Benchmark
- 720 recent Codeforces rated problems.
- Includes interactive and complex structured data problems.
- Prior methods could not be evaluated here.
Evaluation metrics:
- Consistency — percentage of judgments matching official verdicts.
- FPR — incorrect solutions wrongly accepted.
- FNR — correct solutions wrongly rejected.
---
Results
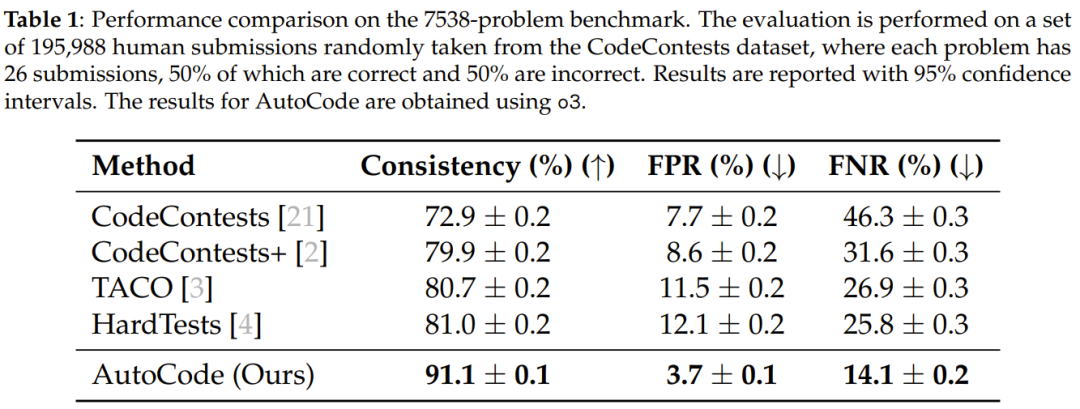
7,538-Problem Benchmark
- Consistency: 91.1% (prev. best ≤ 81.0%)
- FPR: 3.7%
- FNR: 14.1% — ~50% reduction compared to best prior methods.
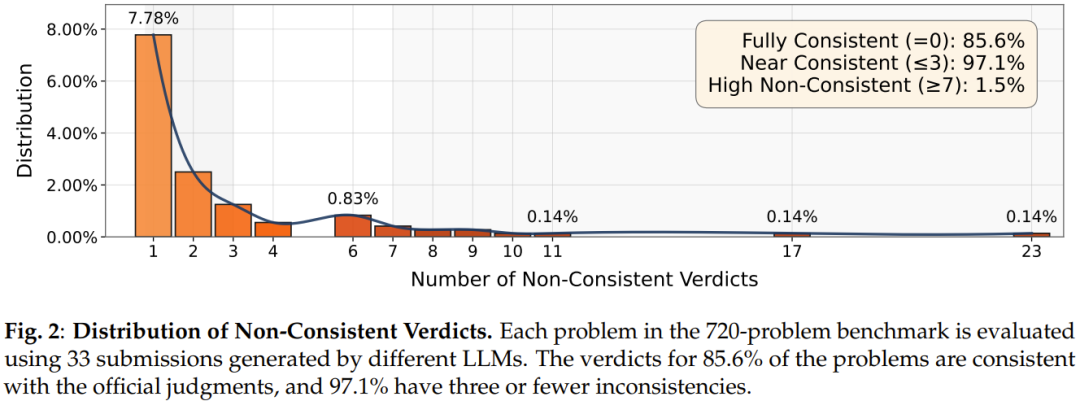
720-Problem Benchmark (Unfiltered)
- Consistency: 98.7%
- Validated strong performance on modern, harder problems.
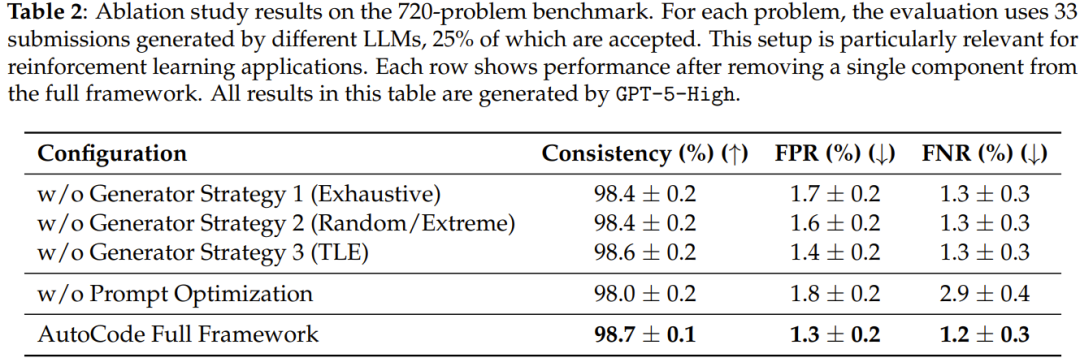
---
Problem Generation Framework
Builds on robust test generation with a dual verification protocol.
Expert panel (8 human problem setters) confirmed:
- Common approach: start from a “seed problem” and modify constraints to produce a novel challenge.
Process:
- Random seed problem (< 2200 difficulty rating).
- LLM modifies conditions to create new problem.
- Provide:
- Efficient solution: `std.cpp`
- Brute-force solution: `brute.cpp`
- Generate test data.
- Run both solutions:
- Brute-force acts as ground truth.
- Efficient solution verified against it by checker.
Outcome:
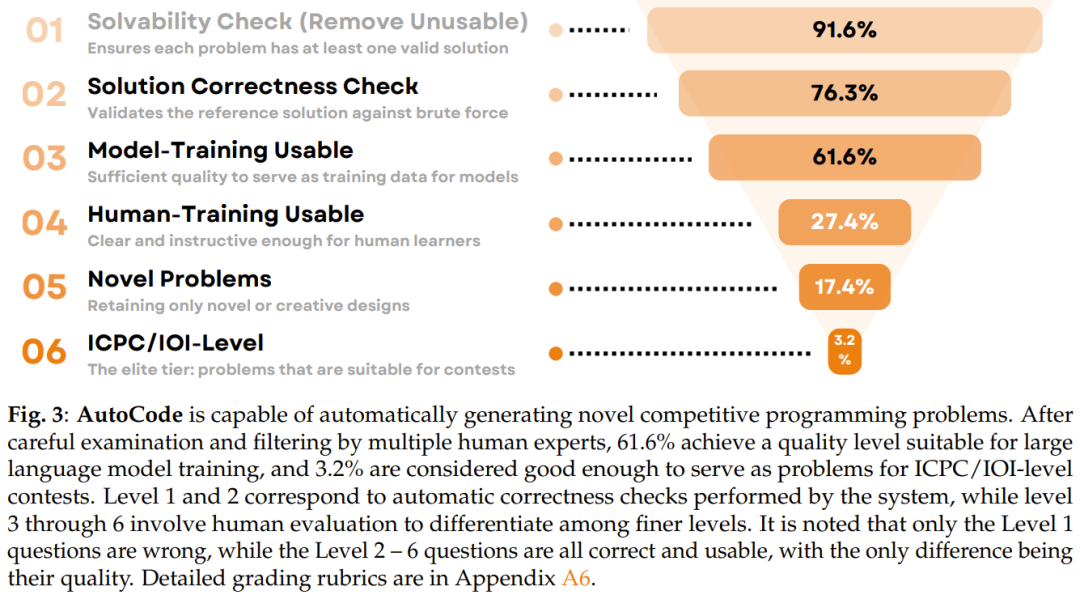
- Protocol filters out 27% of error-prone problems.
- Reference solution correctness ↑ from 86% to 94%.
- 80% usable for training; 23% truly novel.
---
Key Findings
- LLMs can create solvable problems they cannot solve themselves.
- Tend to recombine existing frameworks — strength in knowledge recombination, not pure originality.
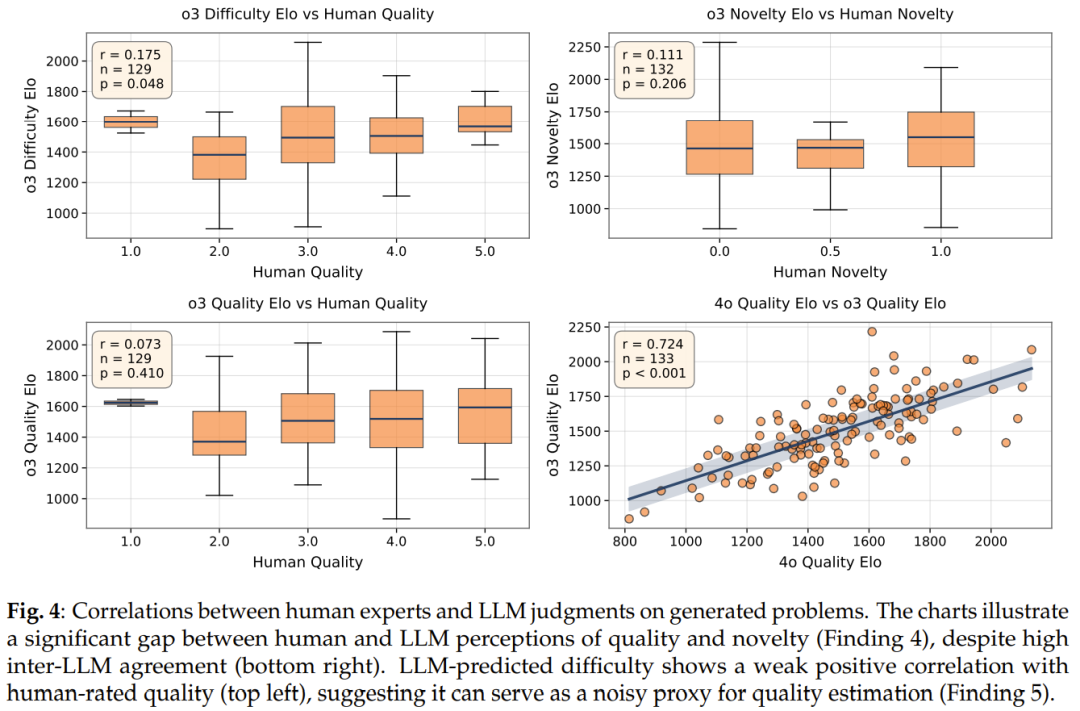
- Problems are often more difficult than their seed problems; best results from moderately difficult seeds.
- Low correlation between human and LLM judgments of quality/novelty.
- Difficulty metrics are better quality indicators than LLM self-assessment.
---
Conclusion
AutoCode:
- Combines Validator–Generator–Checker–Interactor with dual verification.
- Achieves state-of-the-art test case generation reliability.
- Generates competition-level novel problems.
- Demonstrates over 98% consistency and significant FPR/FNR reduction.
LLMs today:
- Excel at knowledge recombination.
- Struggle with deeply original reasoning paradigms.
---
Related Platforms: AiToEarn
Platforms like AiToEarn官网 and AiToEarn博客 provide:
- Open-source tools for AI content generation.
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter).
- Analytics and model ranking (AI模型排名).
Future synergy:
- AutoCode-like workflows could integrate with global monetization tools to distribute AI-generated challenges and benchmarks.
---
Final Note:
Difficulty and difficulty gain are practical signals for automated problem quality assessment, potentially enabling scalable self-play training for next-gen AI problem solvers.
---
Would you like me to create a high‑level diagram summarizing AutoCode’s Validator–Generator–Checker–Interactor–Dual Verification pipeline for quick referencing? That would make this document even more digestible for technical readers.



