NVIDIA, HKU, and MIT Launch Fast-dLLM v2: 2.5× End-to-End Throughput Boost

Autoregressive (AR) LLMs vs. Diffusion LLMs (dLLM)
Autoregressive (AR) large language models generate output sequentially, token-by-token, which limits inference efficiency.
Diffusion-type LLMs (dLLM) allow parallel generation, but traditionally struggle with:
- KV cache reuse
- Variable-length generation
- Consistently outperforming AR in quality
---
Fast-dLLM v2 — Pragmatic Parallel Decoding
Fast-dLLM v2 adapts a pre-trained AR model into a Block-dLLM with only ~1B tokens of fine-tuning, enabling lossless migration.
Key benefits:
- No need for massive datasets (Dream requires ~580B tokens)
- Runs efficiently on A100/H100 GPUs
- Up to 2.5× throughput boost without accuracy loss

📄 Resources:
---
Key Highlights
Minimal Data Adaptation
- Only ~1B tokens of fine-tuning required
- Works with existing AR models like Qwen2.5-Instruct 1.5B/7B
- Avoids hundreds of billions of tokens needed by other approaches
AR-Friendly Architecture
- Block-internal bidirectional attention + block-to-block causal attention
- Preserves AR semantics, KV cache reuse, and variable-length generation
- Uses complementary masking + token-shift for robust adaptation
Hierarchical Cache + Parallel Decoding
- Block-level KV cache for efficiency
- DualCache reduces redundant work during denoising/refinement
- Confidence-thresholded parallel decoding boosts end-to-end speed
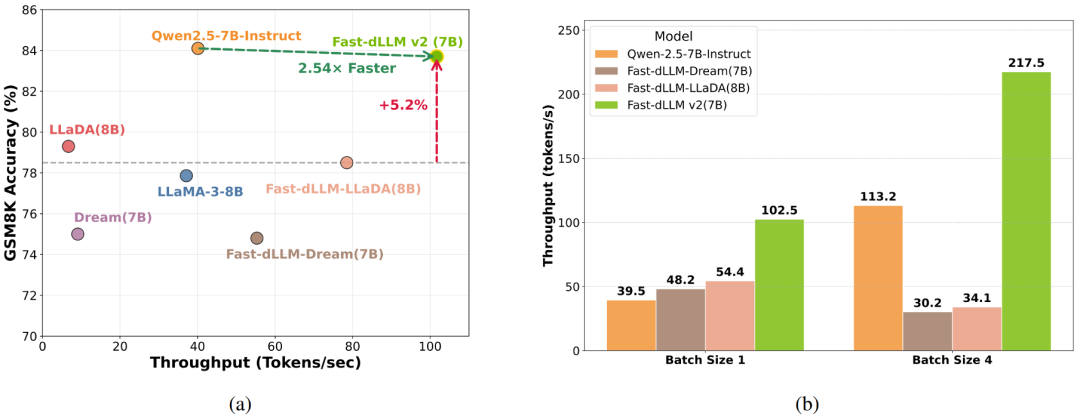
Large-Model Validation
- At 7B scale, matches Qwen2.5-7B-Instruct quality
- Throughput improvement: +2.54×
---
Methodology — From AR to Block Diffusion
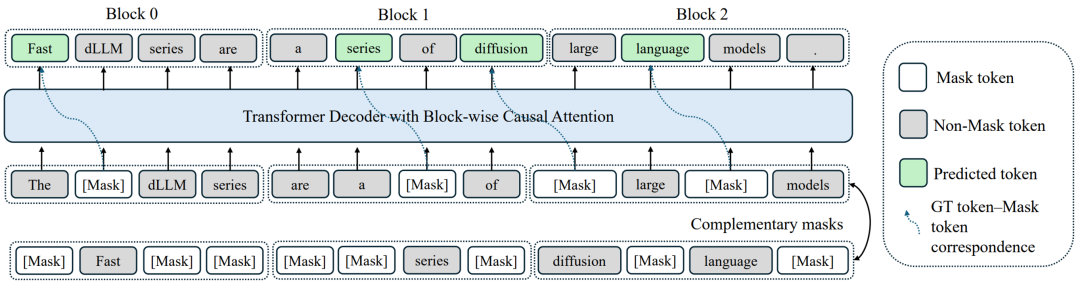
1. Block Diffusion with AR-Friendly Attention
- Split sequences into fixed-size blocks
- Within-block: bidirectional attention → parallel denoising
- Between-block: causal attention → preserves AR semantics
- Complementary masking + token-shift → tokens learned in visible & masked states
2. Hierarchical Cache Structure
Block-Level Cache
- Reuses KV for fully decoded blocks → native AR-style caching
DualCache (Sub-Block)
- Stores prefix & suffix KV for partially decoded blocks
- Avoids repeated computation during refinement cycles
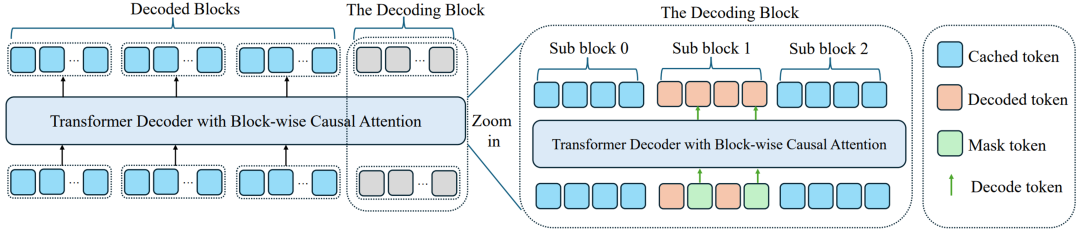
3. Confidence-Aware Parallel Decoding
- When confidence > threshold (e.g., 0.9), finalize multiple tokens at once
- Low-confidence tokens → refined in later passes
- Example (GSM8K):
- Tokens/s: 39.1 → 101.7 (~2.6× speedup)
- Accuracy impact: negligible
---
Practical Applications
Fast-dLLM v2 combines AR robustness with parallel efficiency, making it ideal for latency-sensitive workloads.
Monetization Example — AiToEarn
For creators, AiToEarn connects:
- AI-powered content generation
- Cross-platform publishing
- Analytics + monetization
Platforms include:
Douyin, Kwai, WeChat, Bilibili, Xiaohongshu (Rednote), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
It also provides:
- Multi-platform analytics
- AI model rankings
- Open-source tools for scaling AI creativity into revenue

---
Performance Results
- End-to-End Acceleration: Up to 2.5× speedup with maintained quality
- 7B Model on A100:
- Throughput: +2.54×
- Accuracy: +5.2% (GSM8K) over Fast-dLLM-LLaDA
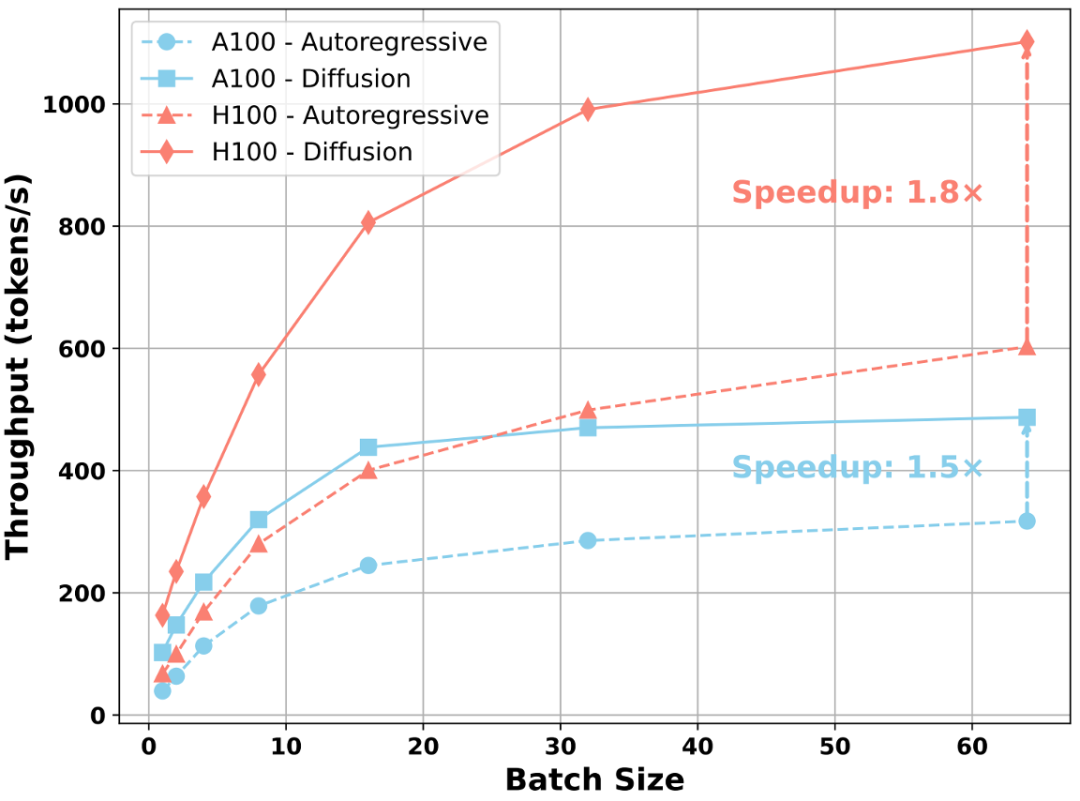
- Scaling:
- Larger batches on A100/H100 → acceleration grows
- ~1.5× boost (A100) → up to ~1.8× (H100)
Benchmark Scores
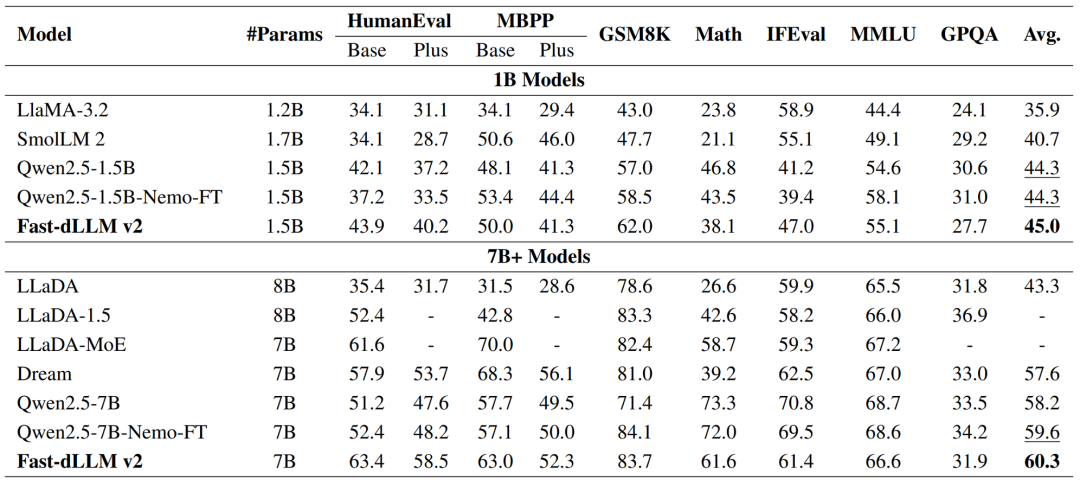
- 1.5B Model: Avg 45.0 — new SOTA among ~1B-parameter models
- 7B Model: Avg 60.3 — beats Qwen2.5-7B-Nemo-FT (59.6) and Dream (57.6)
- Benchmarks include HumanEval, MBPP, GSM8K, MATH, MMLU, GPQA, IFEval
---
Training Cost
Efficiency:
- ~1B tokens vs Dream’s ~500B
- Trained on 64 × A100 in just hours
- Full reproducibility with provided configs
---
Conclusion
Fast-dLLM v2 =
✅ AR → Block Diffusion in hours
✅ 2.5× throughput boost
✅ Comparable or better accuracy
✅ Low compute requirement
Tuning options for optimal balance:
- Block size
- Confidence threshold
- Cache strategy
These gains enhance both developer productivity and content monetization workflows.
Platforms like AiToEarn官网 turn high-performance AI models into global reach and revenue via open-source, multi-platform integration.
---
If you’d like, I can create a comparative performance table showing AR vs dLLM vs Fast-dLLM v2 for different model sizes and benchmarks, to make these results even more digestible. Would you like me to add that?


