# AndesVL: Next-Generation On-Device Multimodal Large Model
## Introduction
Multimodal large models running directly on devices often suffer from **insufficient performance**, **limited capabilities**, and **poor adaptability** — making it challenging to meet **high-performance**, **strong privacy**, and **low-latency** demands in edge AI applications. These issues create a bottleneck in the evolution of AI smartphones.
The **OPPO AI Center** has introduced **AndesVL**, an **open-source**, fully end-to-end adapted **on-device multimodal large model**. AndesVL merges **state-of-the-art multimodal understanding & reasoning** with **edge-specific optimizations**.
### Key Facts
- **Parameter sizes**: 0.6B, 1B, 2B, 4B
- Supports **flexible deployment in multiple scenarios**
- Equipped with **GUI and multilingual capabilities**
- **Fully open source**
Performance Metrics:
- **Up to 6.7× peak decoding speedup**
- **1.8 BPW compression efficiency**
- SOTA results in **30+ benchmarks** compared to similar-sized models
#### Resources:
- [Tech Report](https://arxiv.org/pdf/2510.11496)
- [Hugging Face Models](https://huggingface.co/OPPOer)
- [GitHub Evaluation Toolkit](https://github.com/OPPO-Mente-Lab/AndesVL_Evaluation)
---
## Technical Background
Cloud-based multimodal models have achieved **great success**, but edge deployment faces challenges:
- **High-performance need** on devices
- Strict **privacy requirements**
- Demands for **low latency**
**AndesVL** is **China's first** fully end-to-end on-device multimodal large model series, optimized for smartphone deployment via:
- **Rapid deployment**
- **Inference acceleration**
- **Broad application support**
---
## Key Highlights
1. **Strong General Capabilities**
- Outperforms similar-sized open-source models across **30+ public benchmarks**
- Domains: math reasoning, OCR, image-text understanding, multi-image comprehension, hallucination suppression
2. **Specialized Edge Capabilities**
- Enhanced **multilingual** and **GUI** understanding
- Maintains edge-relevant SOTA performance
3. **Broad Applicability**
- Four sizes: 0.6B, 1B, 2B, 4B
- *Instruct* vs *Thinking* variants for different complexity scenarios
4. **Excellent Edge Deployment**
- **Sparsification**
- **Quantization-aware training**
- **Codec acceleration**
5. **Rapid Edge Adaptation**
- **1+N LoRA architecture**
- **QALFT technology** for scenario-independent updates

---
## Model Architecture Overview
**Components:**
- **Vision Encoder (ViT)**
- **Multi-Layer Perceptron (MLP)**
- **Large Language Model (LLM)**
**Encoders:**
- 1B–4B: **AimV2-300M** (low-power, edge-friendly)
- 0.6B: **SigLIP-2-base** (lightweight for constrained deployments)
**Enhancements:**
- **2D-RoPE** for resolution flexibility
- **NaViT** for arbitrary input resolution
- Pixel-shuffle compression for speed
**LLM Base:**
- **Qwen3 series**, *Instruct* & *Thinking* modes
---
## Training Strategy
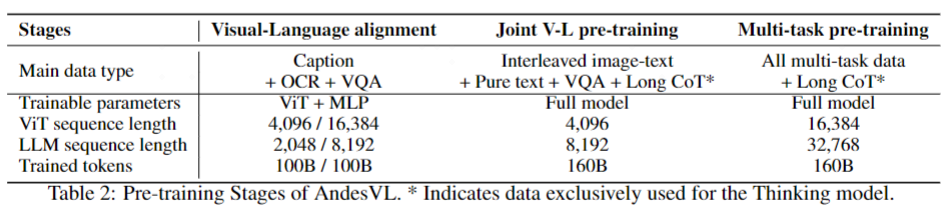
### 1. Pre-Training Stages
#### Vision–Language Alignment
- Low → high resolution fine-tuning (896×896 → 1792×1792)
- Data: captions, OCR, VQA
#### Joint Vision–Language Pre-Training
- **Full-parameter training** with low LR
- Expand context from **2K → 8K tokens**
- Random position replacement for image sequence optimization
- **Thinking versions** receive large reasoning datasets
#### Multi-Task Pre-Training
- ↑ ViT length: 4,096 → 16,384
- ↑ LLM length: 8K → 32K tokens
- Data includes grounding & GUI understanding datasets
---
### 2. Post-Training Stages
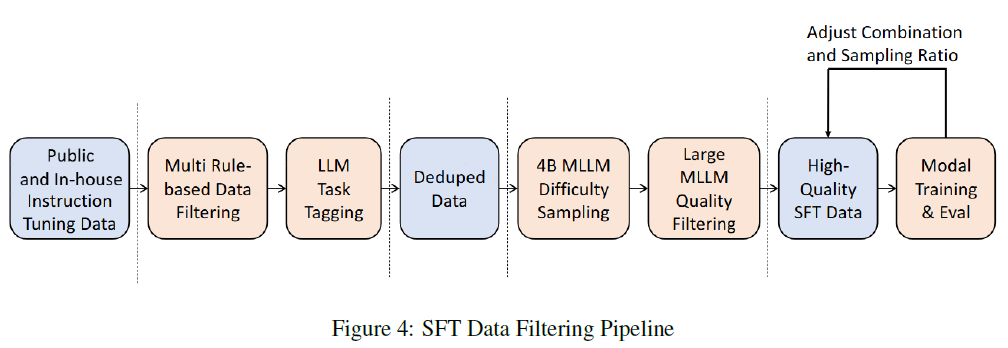
#### Supervised Fine-Tuning (SFT)
- Multi-modal data: captioning, VQA, summarization, code generation
- Filtering pipeline: modality filtering → task clustering → LLM scoring
- Result: 16M high-quality entries
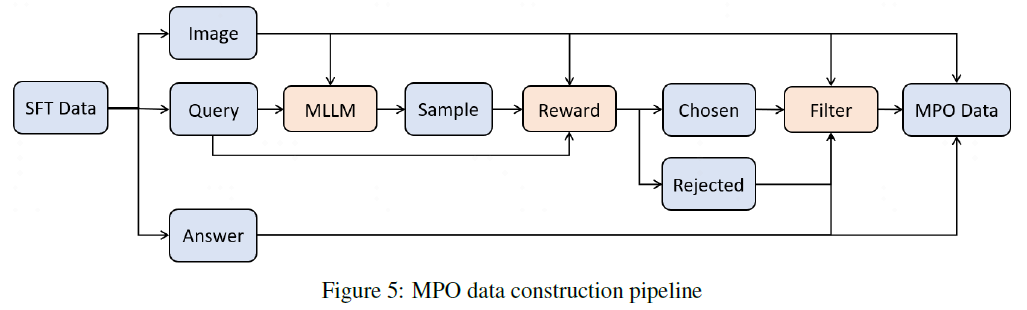
#### Mixed Preference Optimization (MPO)
- Addresses multimodal DPO challenges
- Pipeline + MMPR data to enhance reasoning
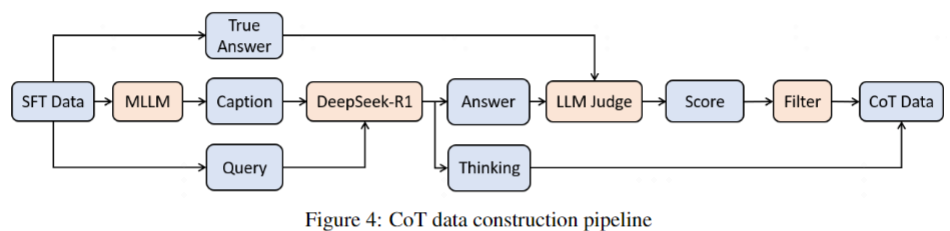
#### GRPO Training
- Data distillation to capture long reasoning chains
- "With/without reasoning" datasets enable mode switching
- Curriculum learning: easy → hard
---
## On-Device Deployment Solutions
### Algorithm Optimization
- **Sparsification**: 75% sparsity, BPW < 1.8
- Collaboration with **MediaTek Dimensity 9500** for hardware-level compression
- Memory ↓ 30.9%, Speed ↑ 45%
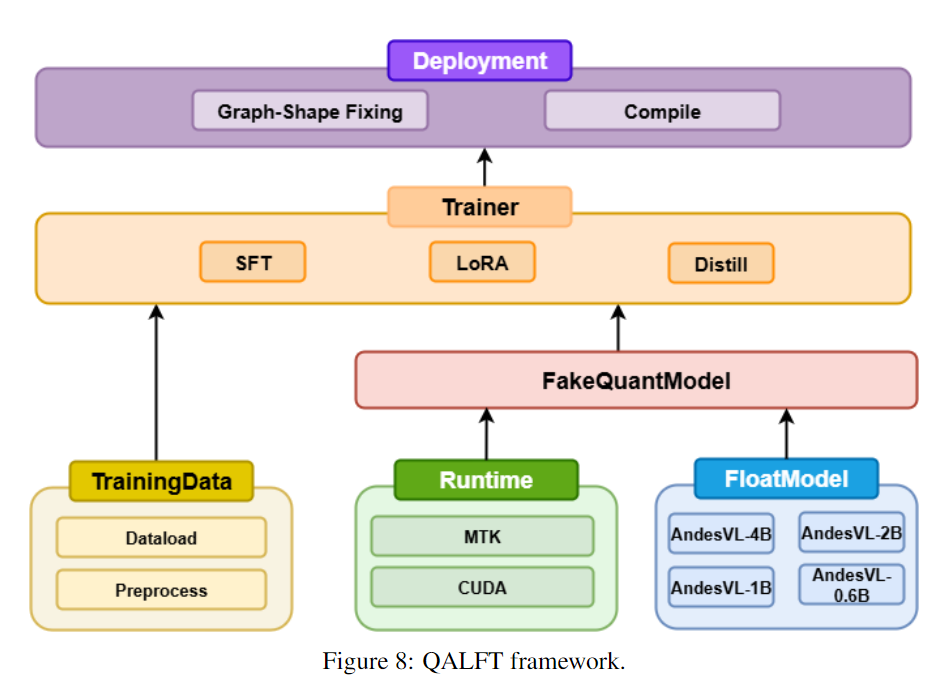
### Quantization-Aware Training (QAT)
- Base model QAT: mixed precision for weights/activations
- **QALFT** for scenario-specific LoRA training independence
### Encoding & Decoding Acceleration
- **OKV compression**: retain only 25% of KV cache for 128K context
- **Speculative decoding**: 6.7× peak speedup
### 1+N LoRA Architecture
- Single base model + multiple pluggable LoRAs
- Enables **dynamic loading & targeted updates**
---
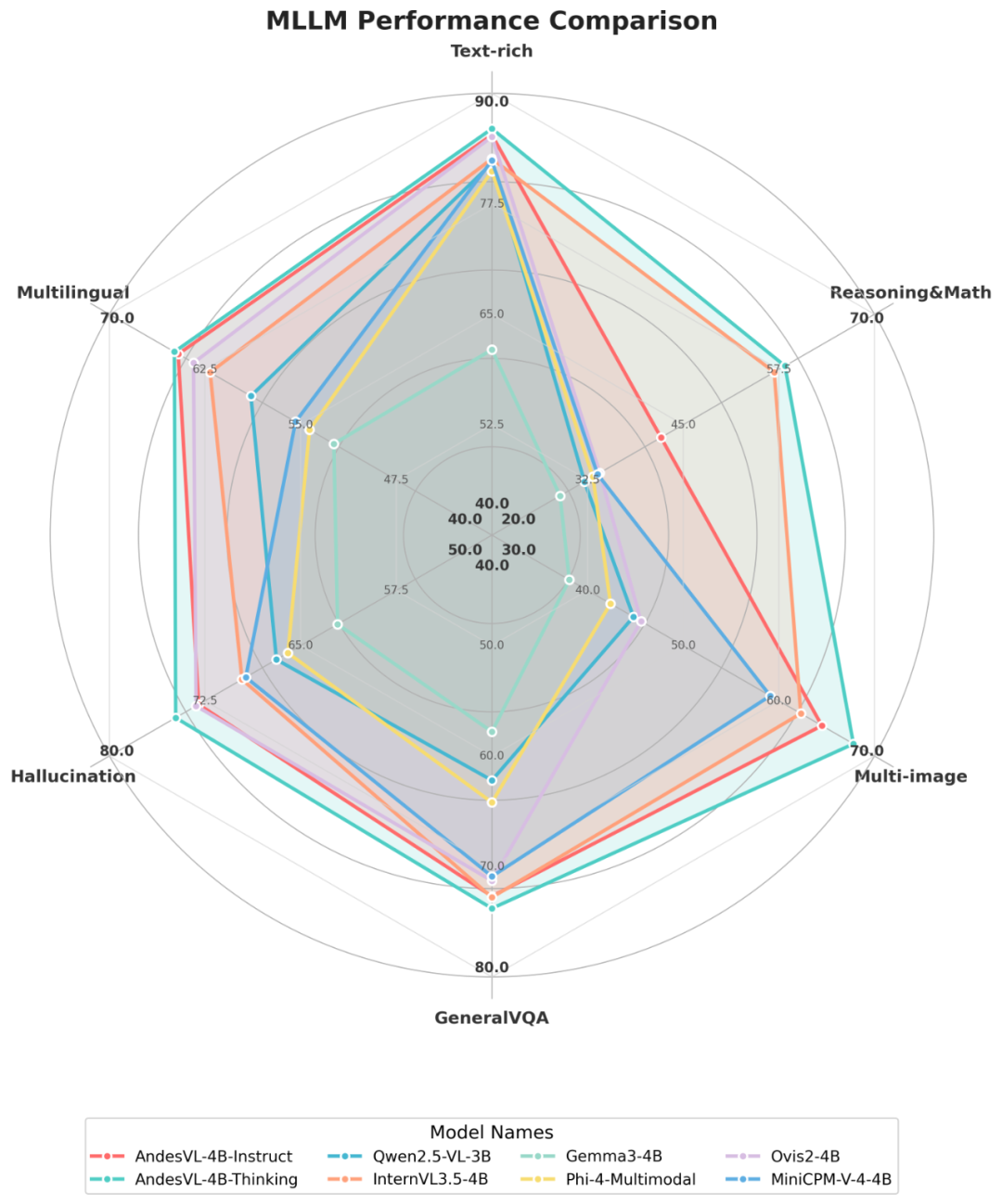
## Evaluation Results
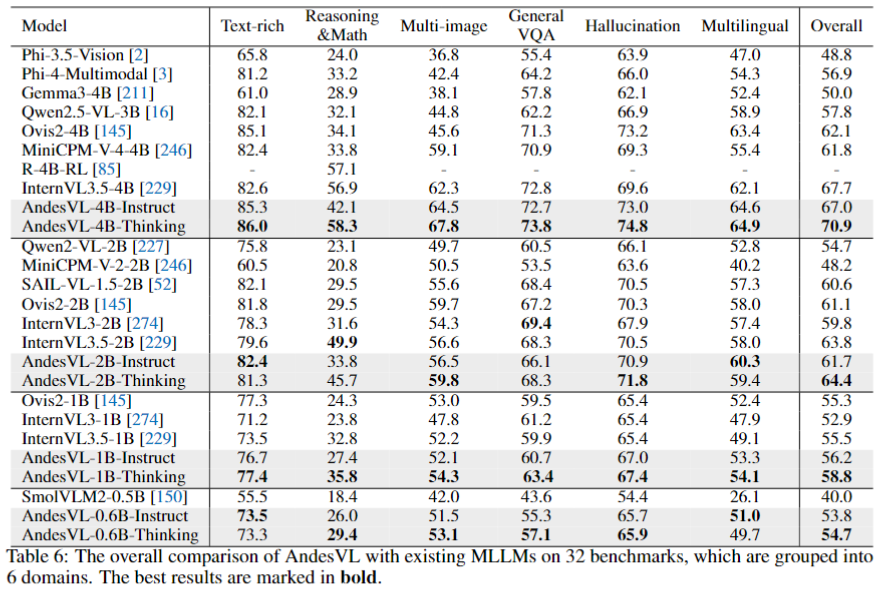
**Highlights:**
- 4B-Thinking: **70.9** score, +3.2 over next best
- Smaller models (0.6B, 1B, 2B) also top their size categories
- High performance across reasoning, multi-image, multilingual, hallucination suppression
---
## Domain-Specific Capabilities
### Mathematics & Logical Reasoning
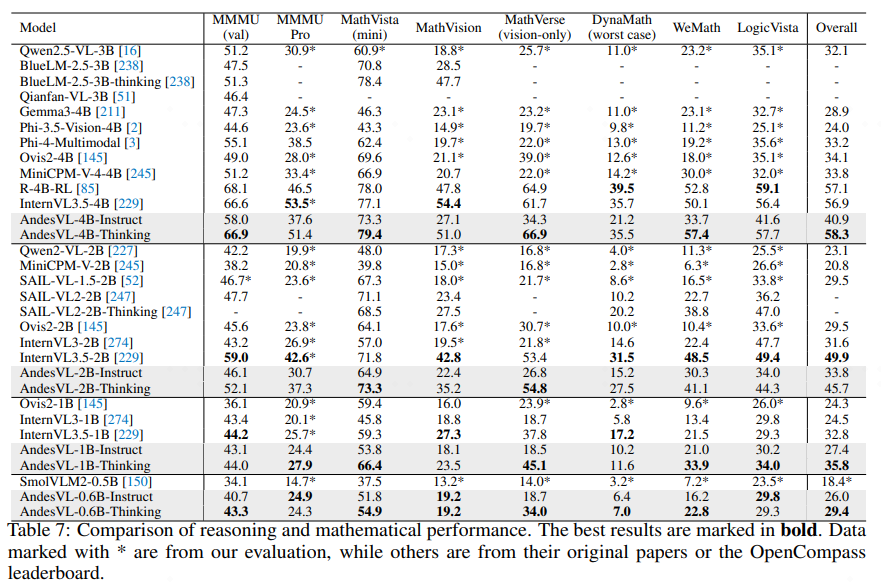
- 4B-Thinking: Top composite score (**58.3**)
- Edge benefit: Strong chain-of-thought reasoning
### Visual–Text Understanding
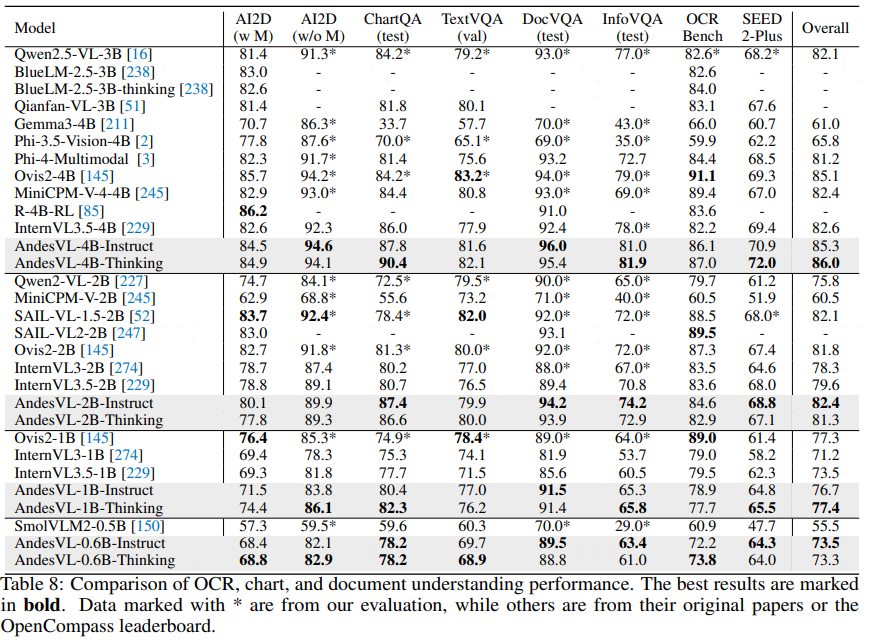
- ChartQA score: **90.4** vs previous best 86.0
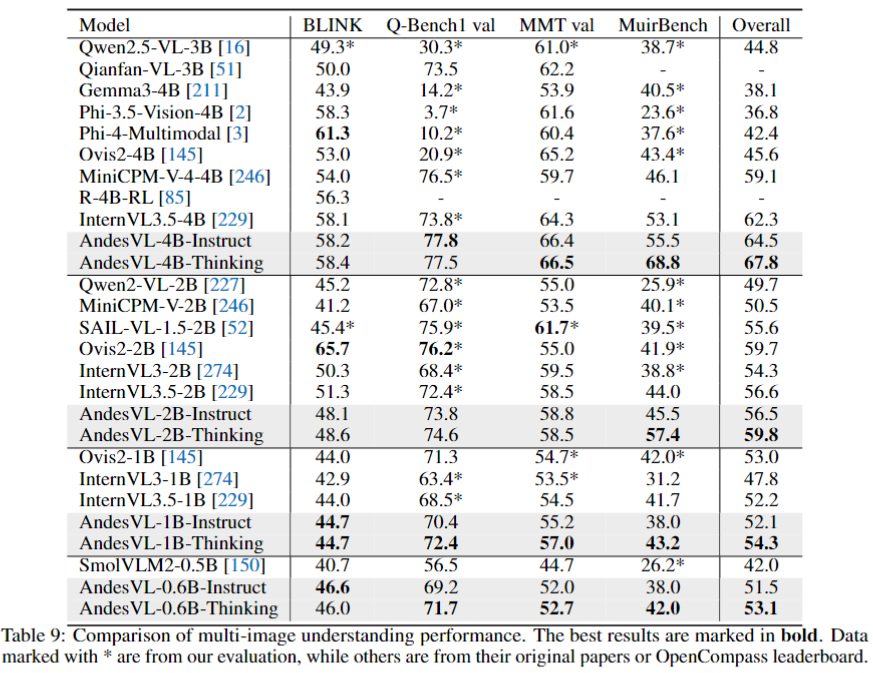
### Multi-Image Understanding
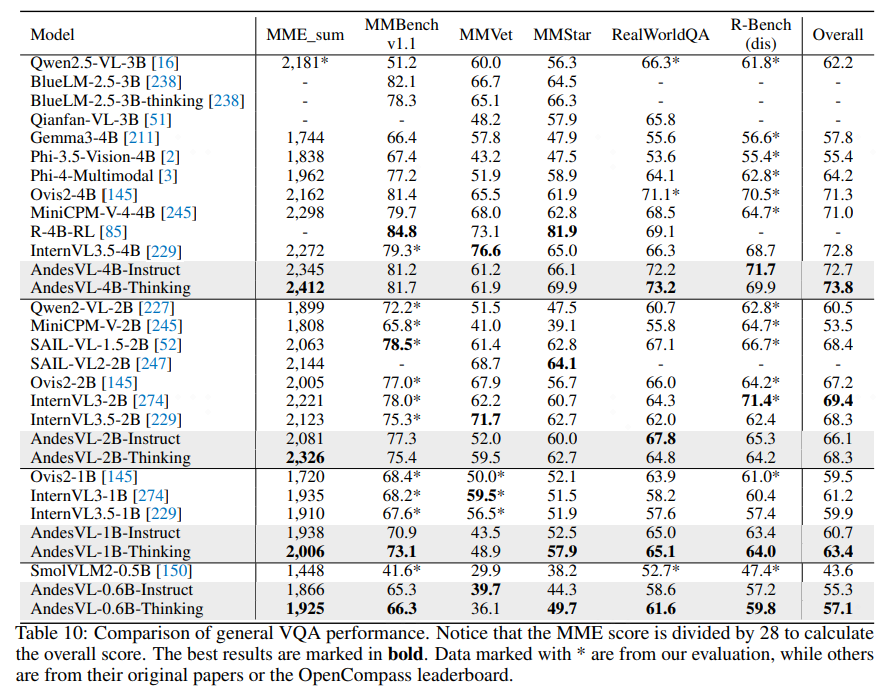
### General Q&A
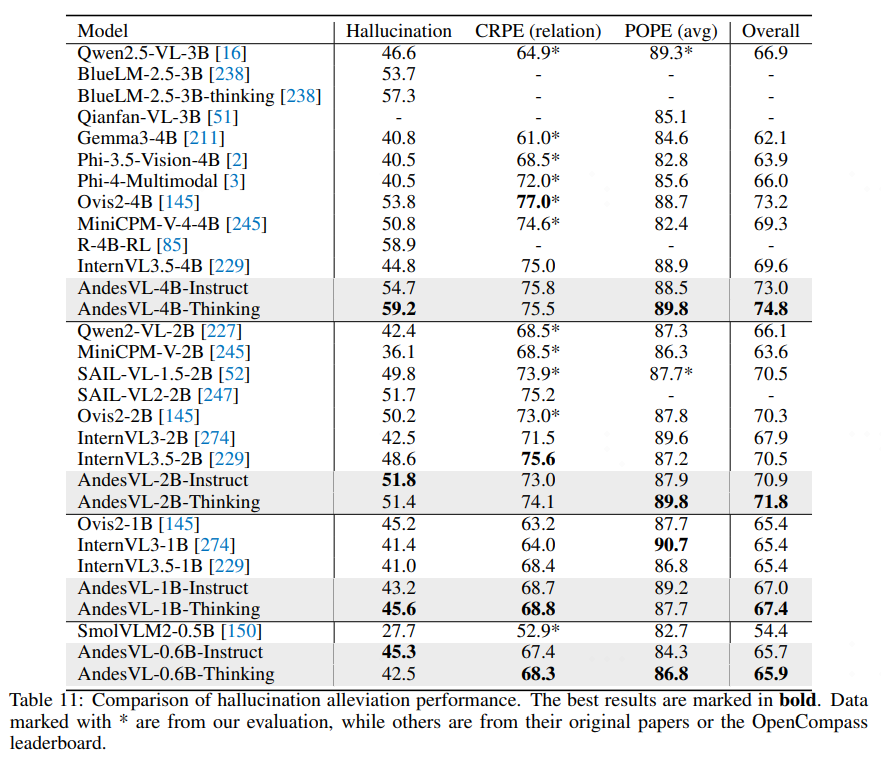
### Hallucination Suppression
---
## Multilingual & UI Understanding
### Multilingual
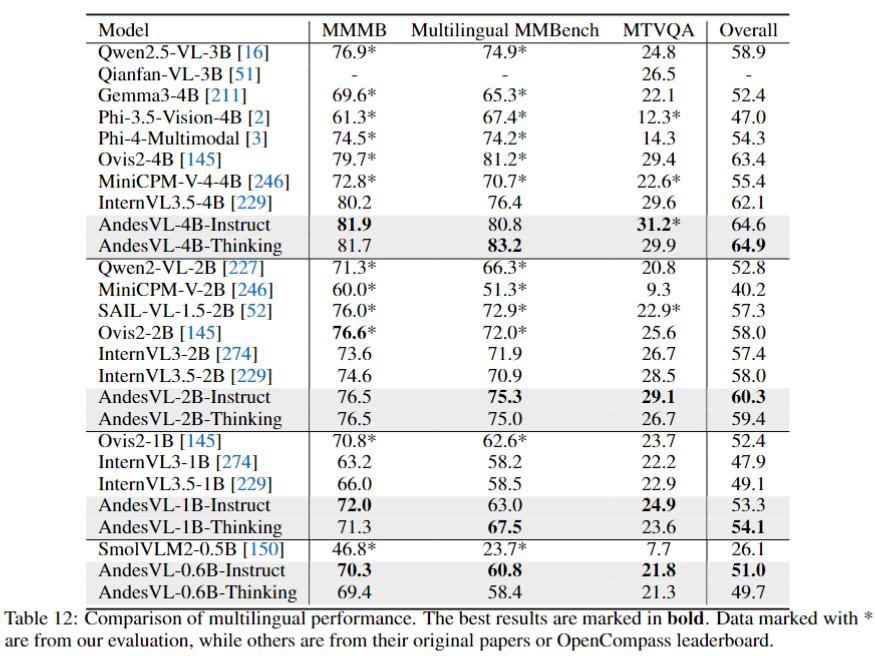
- Top score: **64.9**, surpasses Ovis2-4B (+1.5)
### UI
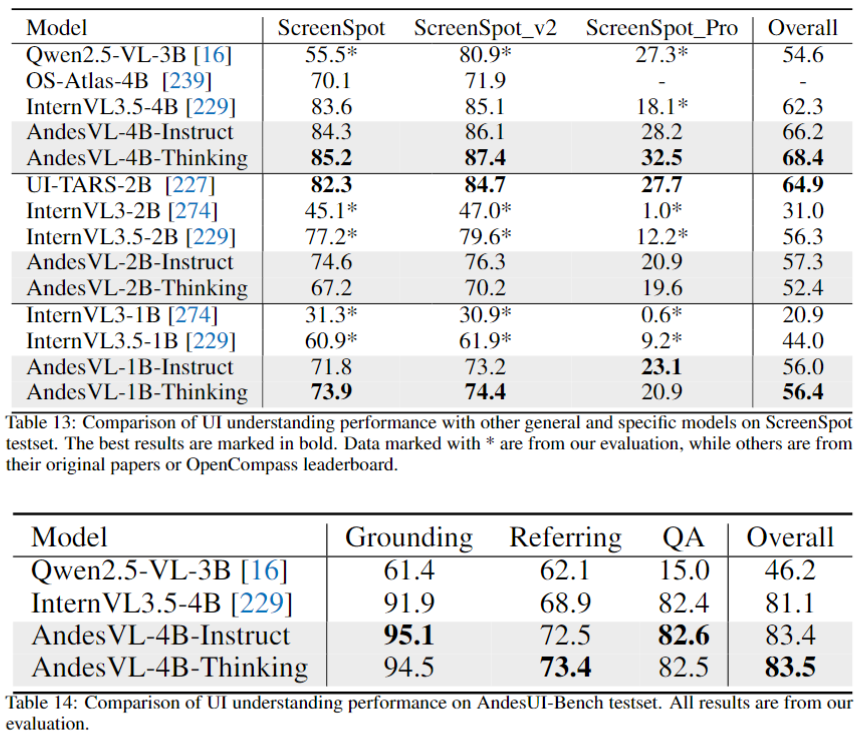
- Leading scores in ScreenSpot & **AndesUI**
---
## Device-Level Evaluation
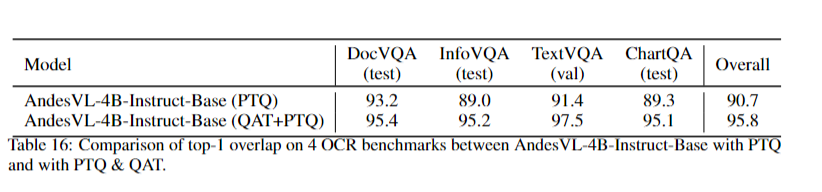
### QAT Accuracy
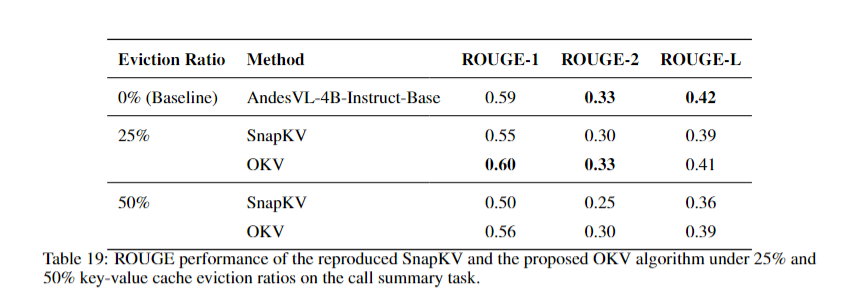
### Cache Eviction
### Speculative Decoding
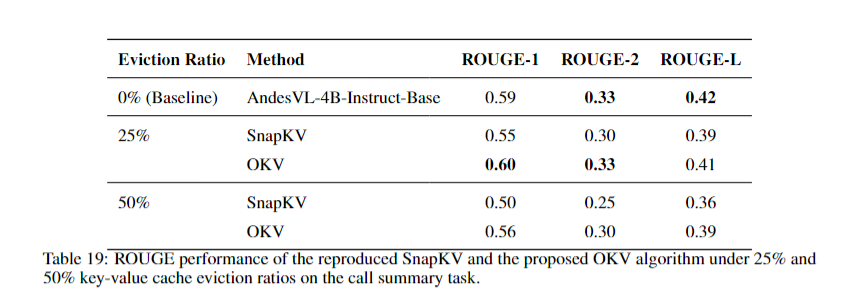
---
## AndesUI Benchmark Dataset
- Screenshots from **90 apps** (65 third-party, 25 native)
- **227,000 labeled UI elements**
- Two tiers: basic (pointing/location) + advanced (descriptions/Q&A)


---
## Model Output Examples

---
## Future Outlook
**Roadmap:**
- Optimized visual encoders
- Post-training enhancements
- Knowledge distillation for efficiency
- Tri-modal (text + vision + speech) integration
As multimodal AI matures, **platforms like [AiToEarn](https://aitoearn.ai/)** will be key to:
- **Cross-platform publishing**
- **Automated analytics & ranking**
- **Monetization for creators**
OPPO aims to deliver secure, fast, and intelligent mobile AI experiences — driving industry-wide innovation.
---




