OpenAI’s Attempt to Regain Human Control on the Eve of the Singularity | Analysis of OpenAI’s New Paper

Living in the Age of Black-Box AI
We live in an era dominated by black boxes — systems we call AI.
For decades, the contract was simple:
We feed AI massive amounts of data, and it gives us magic back — recommending the next song, recognizing cats with 99% accuracy, or writing a Shakespearean sonnet.
We didn’t care how it worked. We only cared that it worked.
Now, when AI is diagnosing cancer, approving loans, or — worst of all — controlling nuclear weapons, understanding how it works becomes unavoidable.
---
Enter Mechanistic Interpretability
A research field called mechanistic interpretability aims to uncover exactly what a model is thinking.
Companies like Anthropic have introduced techniques such as probes, in which researchers try to reverse-engineer a network’s “thought process” by tracking attention changes.
However, these methods face a fundamental neural network challenge: superposition.
Until recently, the problem seemed intractable — until OpenAI published
> Weight-Sparse Transformers are Interpretable Circuits
offering a direct approach to dismantling AI opacity.

---
1. The Curse of Superposition
Superposition turns a neural network into an overcrowded studio apartment.
In dense networks, a single neuron often represents multiple concepts to save on parameters.
Example:
- 0.8 activation → Cat
- -0.5 activation → Dog
- 0.3 activation → Quotation mark
This compressed representation boosts efficiency — but makes understanding any one neuron nearly impossible.
Worse still: Logic for even simple tasks, like detecting quotation marks, can be scattered across dozens of neurons.
The result? A tangled web that's extremely powerful, but hard to interpret.
---
2. Sparse Learning — Changing the Rules
OpenAI’s approach: Change the “economic rules” so neurons stop multitasking.
Method:
- Train a weight‑sparse model from scratch.
- After each training step, zero out all but the largest weights.
- Extreme case: 99.9% of weights removed.
Impact:
- Neurons keep fewer connections — “concept stuffing” becomes wasteful.
- Forced toward concept disentanglement — each neuron represents one idea.
---
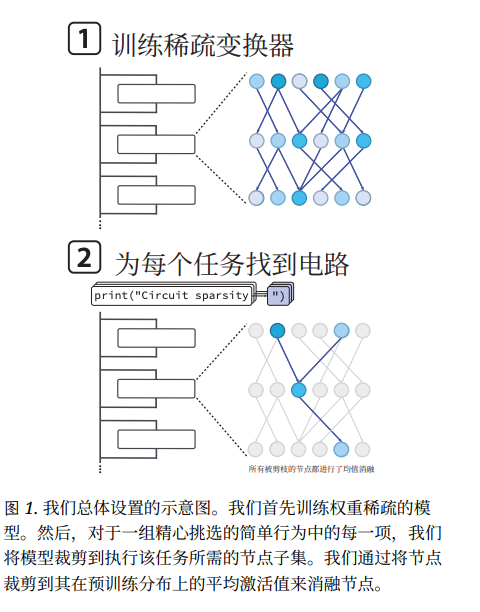
Automated Pruning — Finding the Task Circuit
Sparse training makes the network tidy. Pruning finds which neurons actually matter for a task.
Steps:
- Add a mask (dimmer switch) to each neuron.
- Gradually turn off neurons.
- Permanently remove ones that don’t affect performance.
Result: A small set of lit-up neurons forming an interpretable circuit — the minimal reasoning subgraph for the task.
---
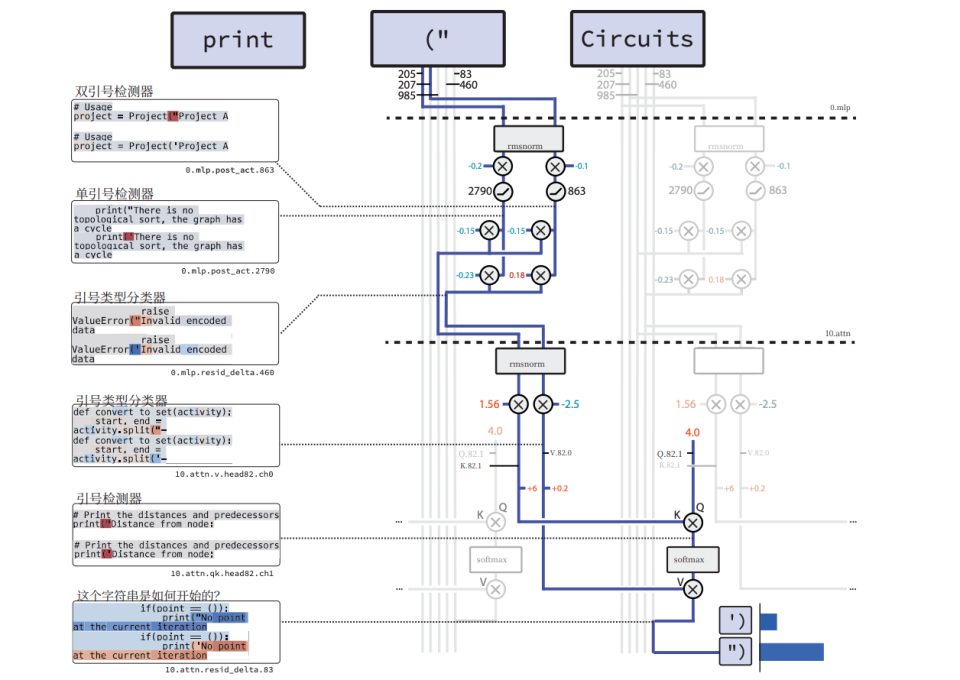
3. Reading the AI’s Mind
With clear, minimal circuits, researchers can trace AI reasoning step-by-step.
Example: Quotation Mark Detection
- Tagging Phase
- Opening `"` → Activates circuit component.
- Stores: Position marker (location) + Type marker (double quote).
- Retrieval Phase
- At sentence end → Layer 10 attention head retrieves both markers.
- Model predicts closing `"`, eliminating `'`.
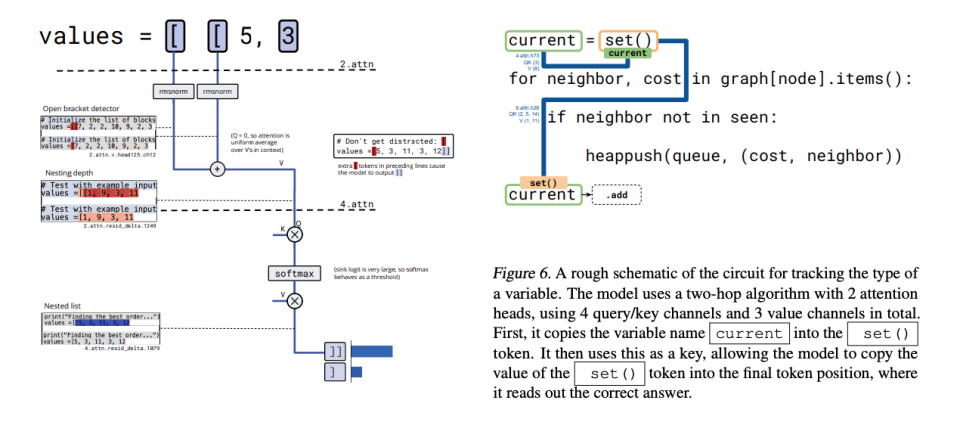
Other discoveries:
- Variable tracking circuits — multi-layer relays store & retrieve variable type via name.
---
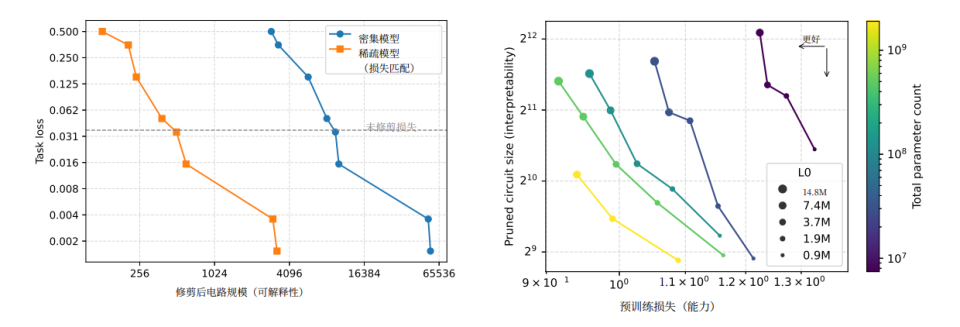
4. Proof of Effectiveness
Researchers tested sufficiency and necessity:
- Sufficiency: Removing all neurons outside the circuit — model still works perfectly.
- Necessity: Removing only circuit nodes — model fails instantly.
Bonus: Circuit hacking proves true understanding.
Example: Bracket nesting depth → Model averaged values.
Adding extra-long context diluted averages → Model failed exactly as predicted.
---
5. The Hardware Problem
Sparse models are slow and bloated on current GPUs:
- 100–1000× more compute to train.
- Larger parameter counts to match dense model intelligence.
Reality: Sparse GPT‑5 is unrealistic with current hardware.
---
6. Plan B — Bridging Dense and Sparse Models
Solution:
- Freeze dense model.
- Train a small sparse model alongside.
- Build translation layers linking sparse neurons to dense neuron groups.
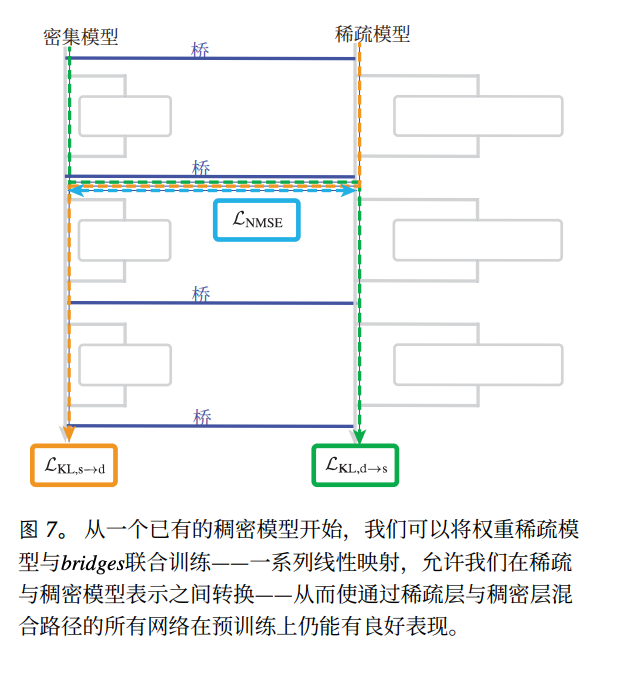
Benefit:
- Sparse model acts as an X-ray machine for dense model behaviour.
- Practical for high‑risk tasks: deception, manipulation, bioweapons.
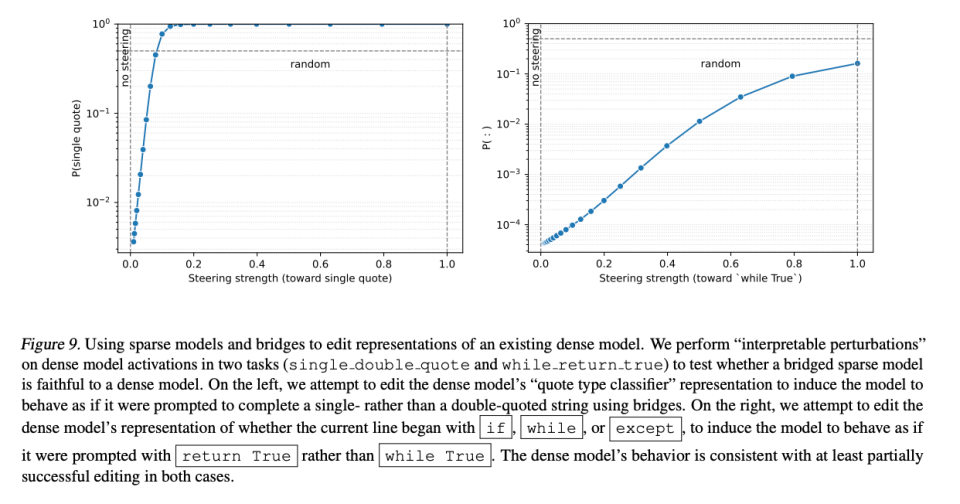
Example:
Data of deceptive outputs → Bridge reveals exactly where & why the dense model lied.
---
7. Imperfect — Yet Profoundly Important
We now have:
- Proof AI’s black box can be opened.
- Tools to understand core reasoning paths.
- Bridging approaches for targeted interpretability.
Why it matters:
As AI approaches superintelligence, these methods may be our only way to detect and stop malicious behaviour before it grows.
---
AI Transparency Meets the Creative Ecosystem
Platforms like AiToEarn官网 combine AI generation, multi‑platform publishing, and model analytics.
Creators can produce, distribute, and monetize AI‑driven work on platforms including Douyin, Bilibili, YouTube, and X (Twitter).
This open, transparent pipeline echoes the need for interpretable AI — showing how AI systems can remain powerful and aligned with human values.
Explore model rankings → AI模型排名
---
Final Thought:
> In the race toward safe superintelligence, interpretable models and open ecosystems may be the intellectual bridle humanity needs — enabling us to act with understanding, not blind trust.


