OpenAI’s Attempt to Regain Human Control on the Eve of the Singularity | Analysis of OpenAI’s New Paper

The Age of the AI Black Box
We now live in an era ruled by black boxes — the systems we broadly call AI.
For decades, our relationship with these machines was simple:
We gave them large amounts of data, and they gave us a kind of magic — recommending the next song, recognizing cats with 99% accuracy, or composing a Shakespearean sonnet.
We didn’t care how they did it, only that they could.
But now, when the black box is diagnosing cancer, approving loans, or—heaven forbid—controlling nuclear weapons, the “how” question is unavoidable.
---
Why Mechanistic Interpretability Matters
Mechanistic interpretability aims to uncover what a model is actually thinking.
Anthropic, for example, has explored "probes" that reverse-engineer neural activity by watching attention shifts, but results are often fuzzy due to a core challenge: superposition.
This month, OpenAI made a breakthrough with:
“Weight-Sparse Transformers Are Interpretable” — tackling interpretability at its root.

📄 Paper: https://arxiv.org/abs/2511.13653
---
1. The Curse of Superposition
Think of superposition like an overcrowded one-room apartment:
- In dense neural nets, one neuron may perform multiple unrelated roles.
- It’s like having 10 cabinets for 1,000 items — each crammed with mixed contents.
Example for a single neuron:
- Seeing “cat” → activation: 0.8
- Seeing “dog” → activation: -0.5
- Seeing “quotation marks” → activation: 0.3
Worse, related information is scattered across multiple neurons — making the logic fragmented and opaque.
Superposition is efficient for AI performance, but terrible for human interpretability.
---
2. OpenAI’s Minimalist Strategy
OpenAI’s logic:
If superposition exists because models mix concepts to save space, change the rules so mixing is costly.
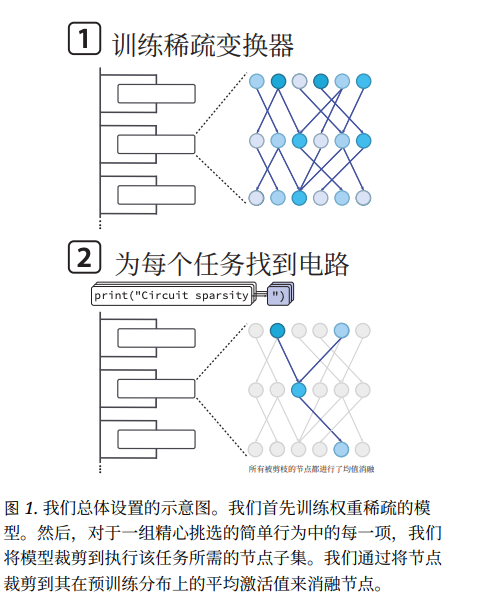
Step 1 — Sparse Training
- Train a weight-sparse model from scratch.
- After each training step: keep only the largest weights, set all others to 0.
- In extreme cases, 99.9% of weights become zero.
- Neurons get only a fraction of their usual connections.
Result:
Each neuron learns to handle a single concept — decluttering its “mental storage”.
---
Step 2 — Automated Pruning
Sparse training tidies the model. Pruning isolates the active wiring for a chosen task.
Process:
- Attach a “dimmer” (mask) to every neuron.
- Gradually turn off neurons with negligible effect on output.
- Surviving active nodes form a minimal core circuit for the task.
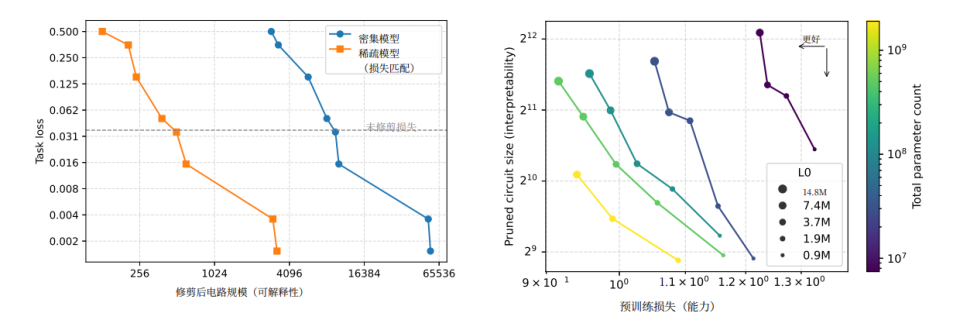
Circuits let researchers trace the AI’s exact decision path — often 16× smaller than in dense models for the same task.
---
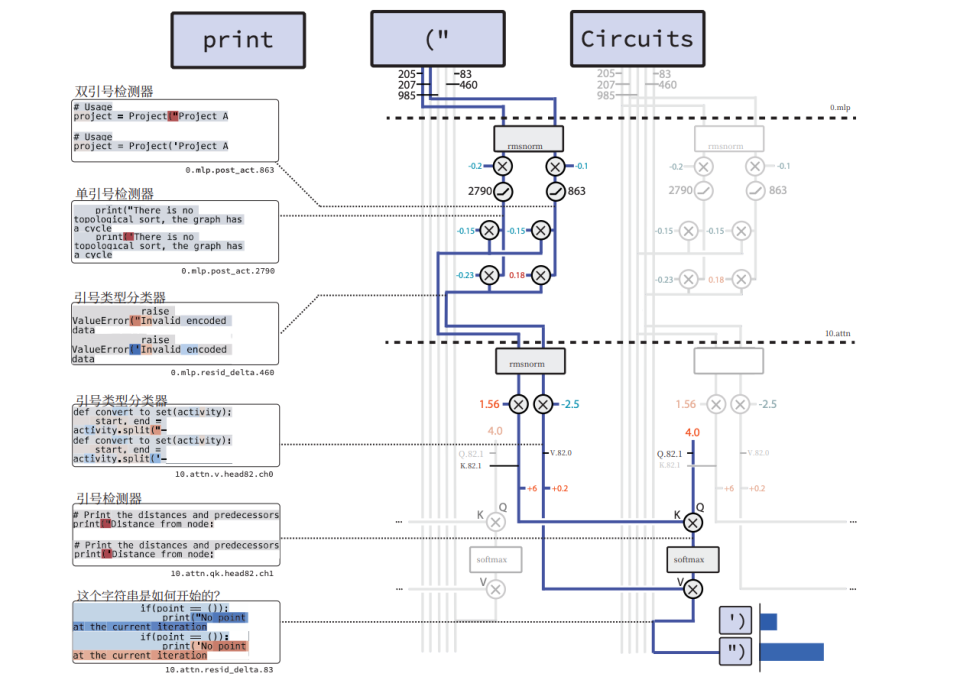
3. Reading the AI’s Mind
With tidy circuits, researchers can decode AI logic.
Example: Quotation Mark Matching
- Marking phase:
- Detects position of the opening quote.
- Classifies the type (double quote).
- Retrieval phase:
- Later, retrieves the stored info to decide the correct closing quote.
This is code-like logic — modular, traceable, and human-readable.
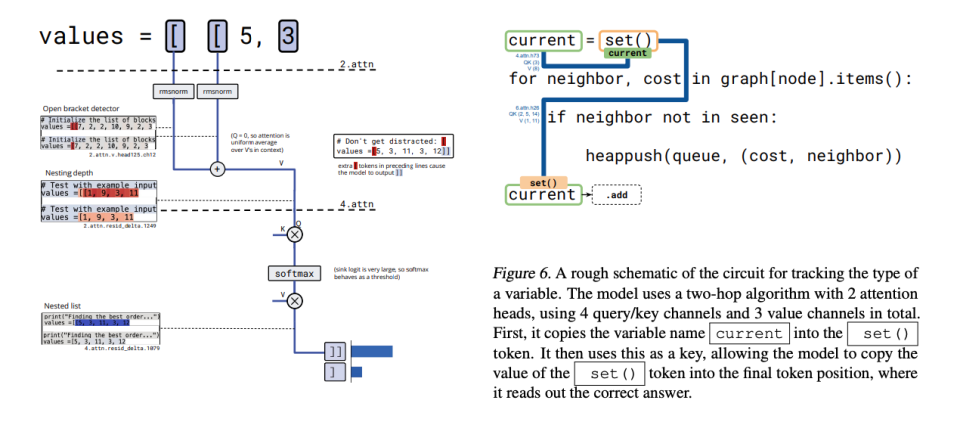
Researchers have also mapped variable-tracking circuits, where different attention layers pass data like a relay race.
---
4. Testing the Interpretation
Two key validation tests:
- Sufficiency: Disable everything outside the circuit → task still works perfectly.
- Necessity: Disable inside nodes → performance collapses.
Then they hacked the model:
- Found a shortcut in bracket-depth counting using averages.
- Gave the model extremely long inputs to break its heuristic.
- It failed exactly as predicted.
This was proof they understood its inner workings.
---
5. The Hardware Bottleneck
The dream: make all models sparse and interpretable.
The reality: current hardware is terrible at running sparse models.
Why:
- GPUs are built for dense, parallel computation.
- Sparse models activate few neurons at once, wasting GPU capacity.
- Matching dense performance often means huge model size — impractical for large-scale AI like GPT‑5.
---
6. Plan B — The Bridge Model
Instead of replacing dense models, OpenAI proposes building a bridge:
- Freeze the dense model.
- Train a small sparse model alongside it.
- Add translation layers to map sparse neuron activations to the dense model’s activity.
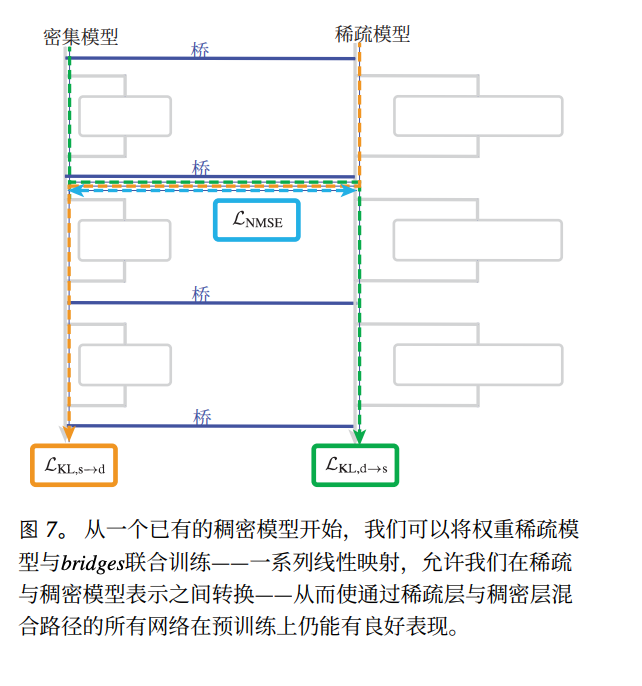
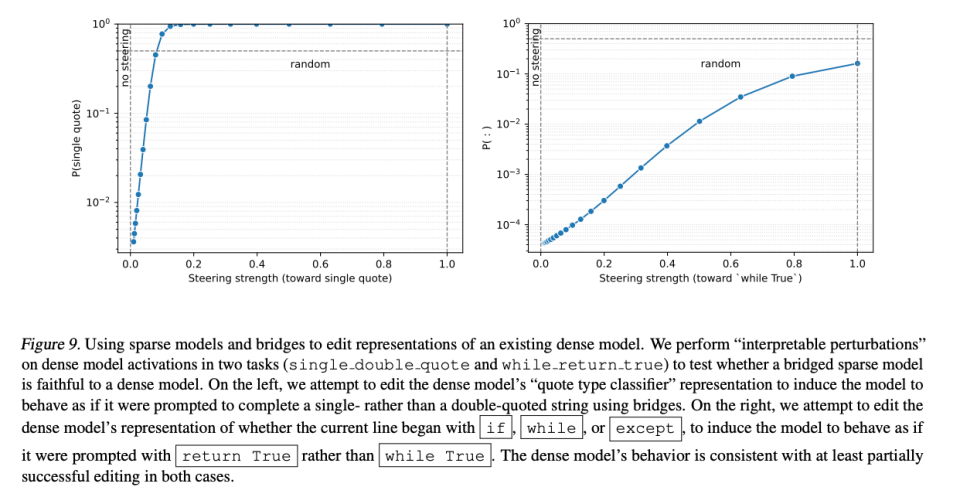
Targeted bridges can translate specific dangerous behaviours (e.g., deception) into human-readable logic — without translating the whole model.
---
7. Why This Matters
These techniques don’t yet solve AI safety, but they:
- Prove interpretability is possible.
- Provide tools to target and monitor risky internal processes.
- Offer a path to preempt dangerous behaviours before they emerge.
By making the black box speak, we move from passive observers to active guides of AI behaviour.
---
8. Beyond Research — Applied Ecosystems
Open-source platforms like AiToEarn官网 and AiToEarn博客 already integrate:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Instagram, YouTube, X)
- Analytics and model ranking (AI模型排名)
Such ecosystems could benefit interpretability research by combining creation, testing, and transparent feedback loops — vital for both safety and monetization of AI-driven work.
---
Bottom line:
Sparsity and pruning won't solve all interpretability challenges, but they let us shine a light into the AI’s hidden reasoning — a crucial step before superintelligent models fully arrive.


