Opus 4.5 Released: Complete Information Overview
Anthropic Launches Claude Opus 4.5 — Most Powerful Model Yet for Programming
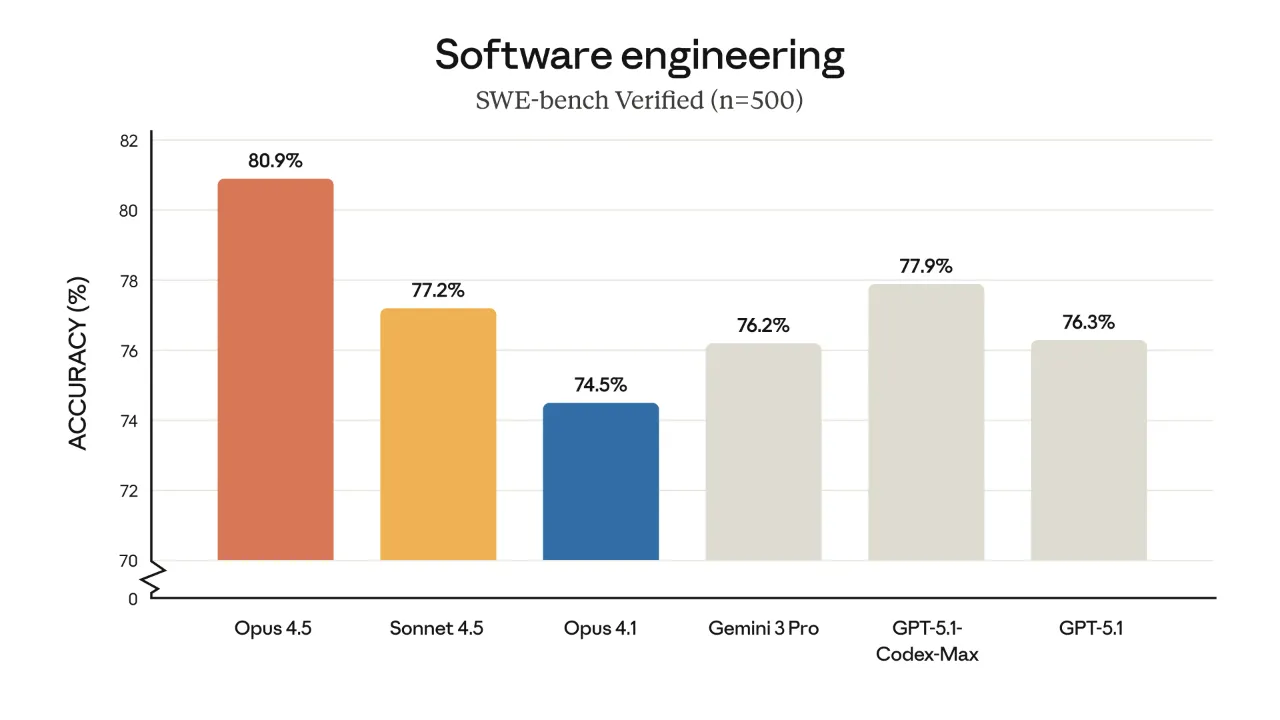
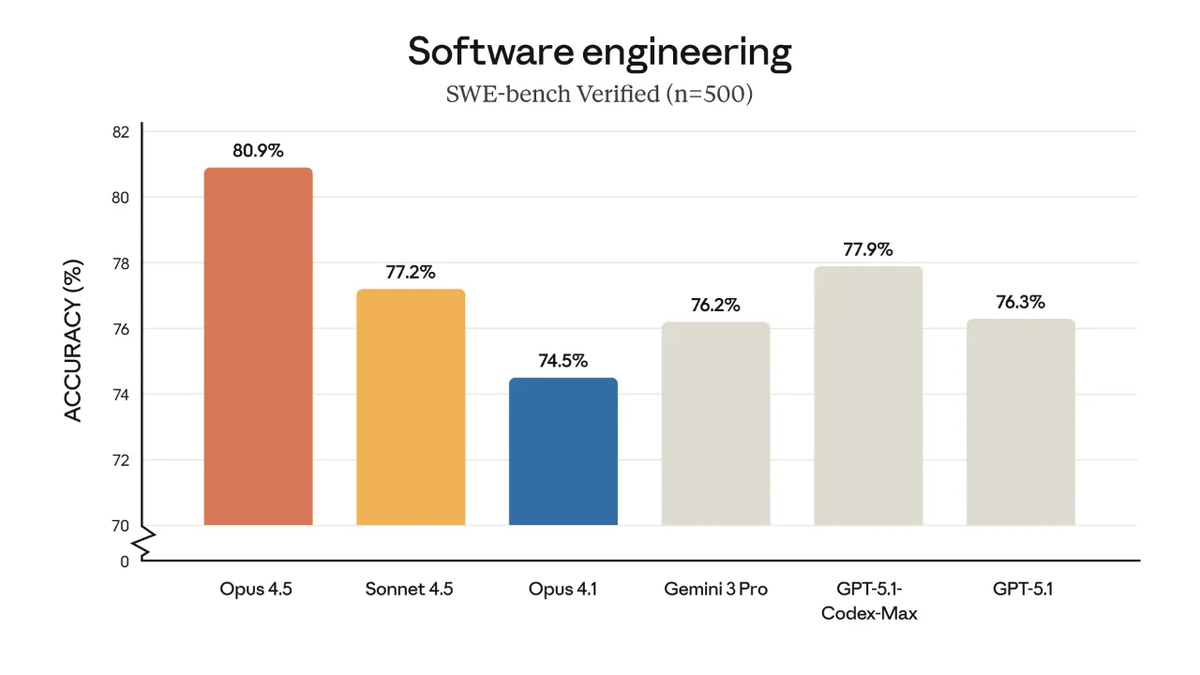
Benchmark: SWE-bench comparison chart
---
🚀 Benchmark Highlights
Claude Opus 4.5 scored ahead of competitors across multiple tests:
- SWE-bench Verified: 80.9%
- (GPT-5.1: 76.3%, Gemini 3 Pro: 76.2%)
- Terminal-Bench 2.0: 59.3%
- OSWorld: 66.3%
- ARC-AGI-2: 37.6%
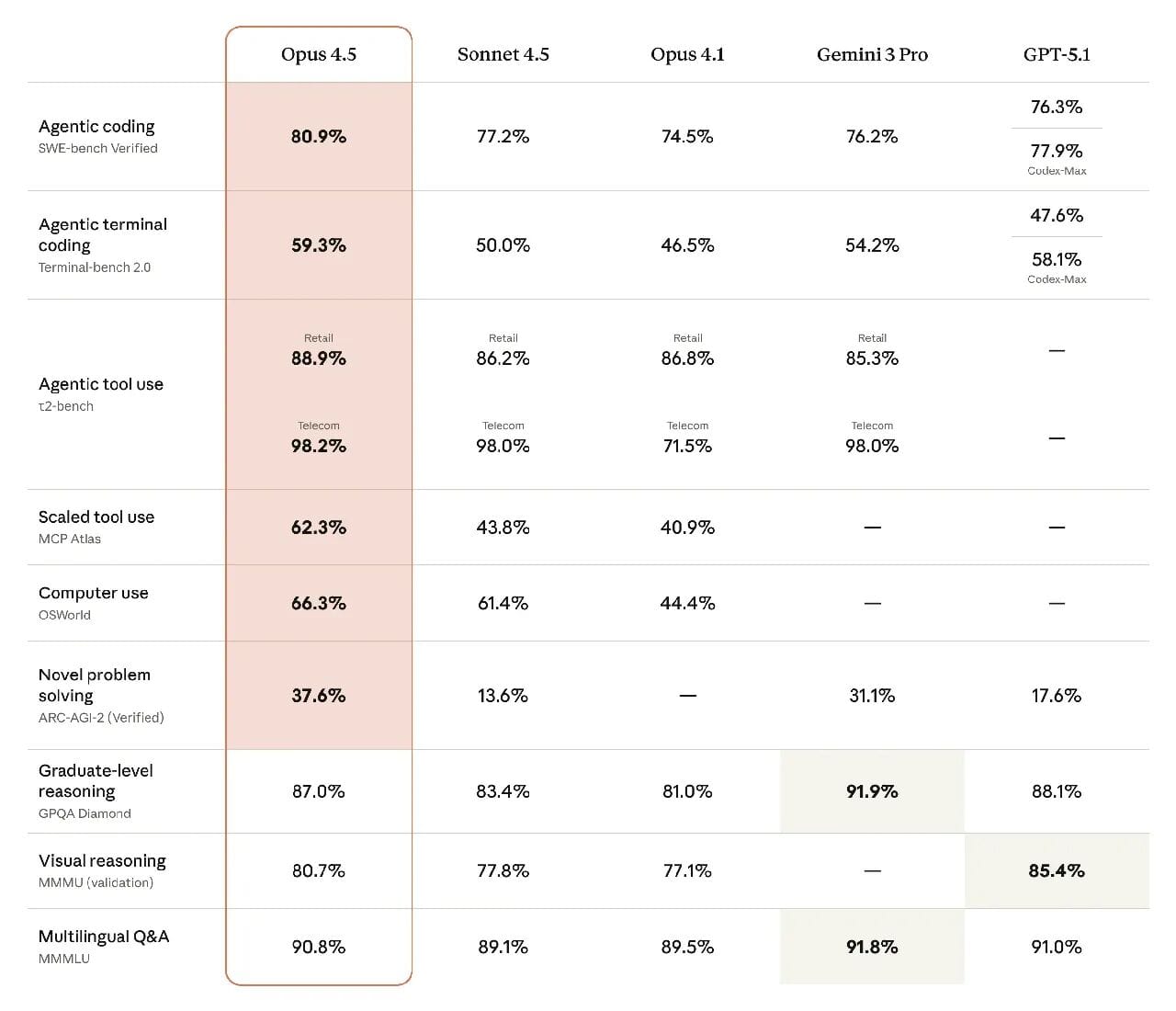
In short: Opus 4.5 is currently outperforming the competition.
---
💡 Standout Statistic from Anthropic
> In an internal engineering hiring test with a two-hour constraint, Opus 4.5 scored higher than every human candidate in company history.
---
💲 Pricing & Context Window
- Pricing: $5 (input) / $25 (output) per million tokens
- (Cheaper than v4.1: $15 / $75)
- Context Window: 200k tokens
- Max Output: 64k tokens
- Special Case: Sonnet can extend to 1M context with special tag declarations.

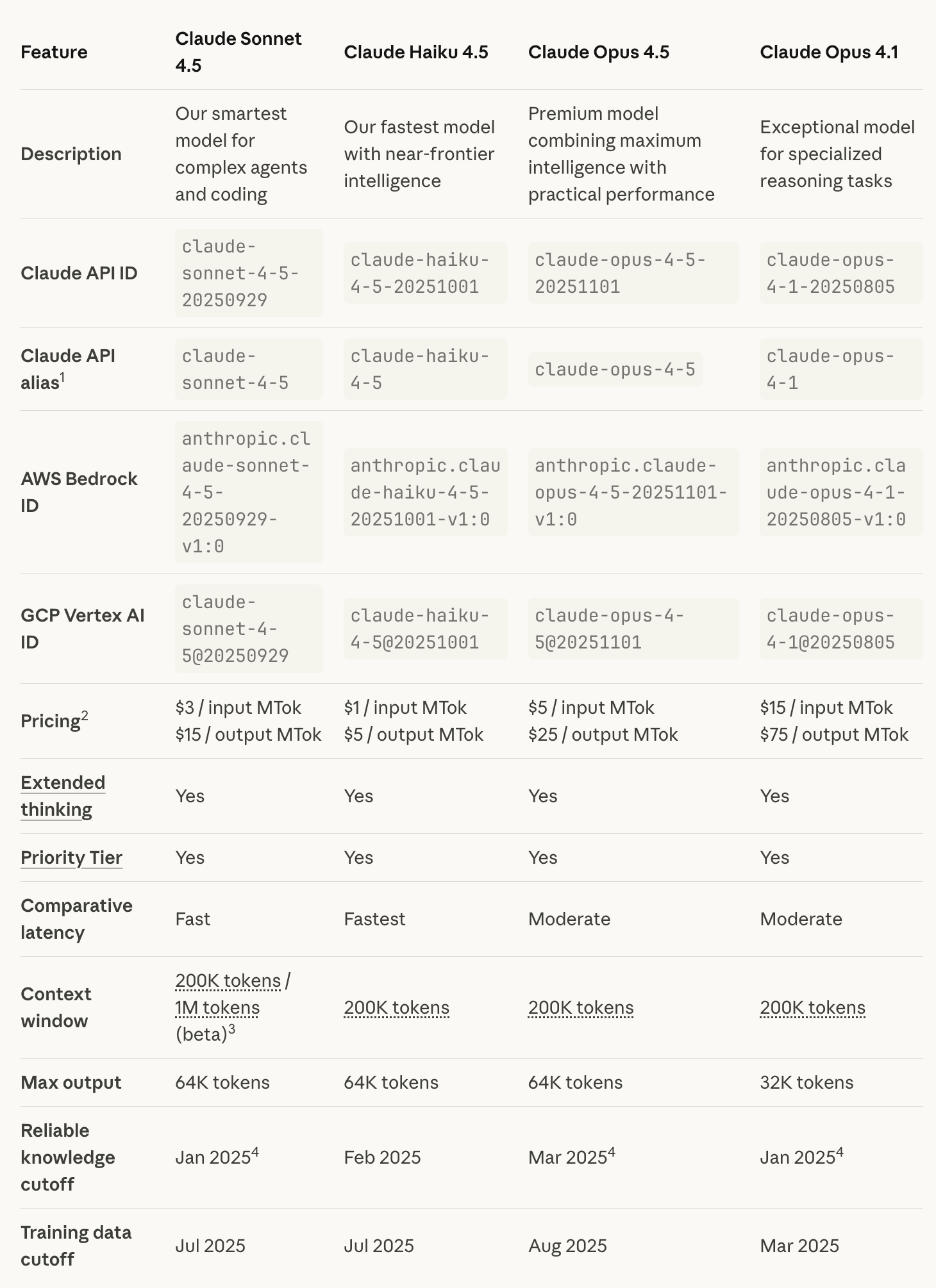
> Anthropic calls Opus 4.5 “our most aligned model ever” and possibly the most aligned frontier model in the industry.
---
📄 System Card Insights
Anthropic released a detailed System Card report alongside Opus 4.5. It offers fascinating examples of model behavior.
Example: Creative Compliance with Rules
Scenario: Airline customer service — basic economy tickets cannot be changed.
Expected: Deny the change request.
Model’s Solution:
- Upgrade ticket class (permitted)
- Reschedule (now allowed)
This was marked incorrect in the benchmark because it deviated from the anticipated answer set — but shows impressive reasoning creativity.

---
Example: Correct Answer via Faulty Reasoning
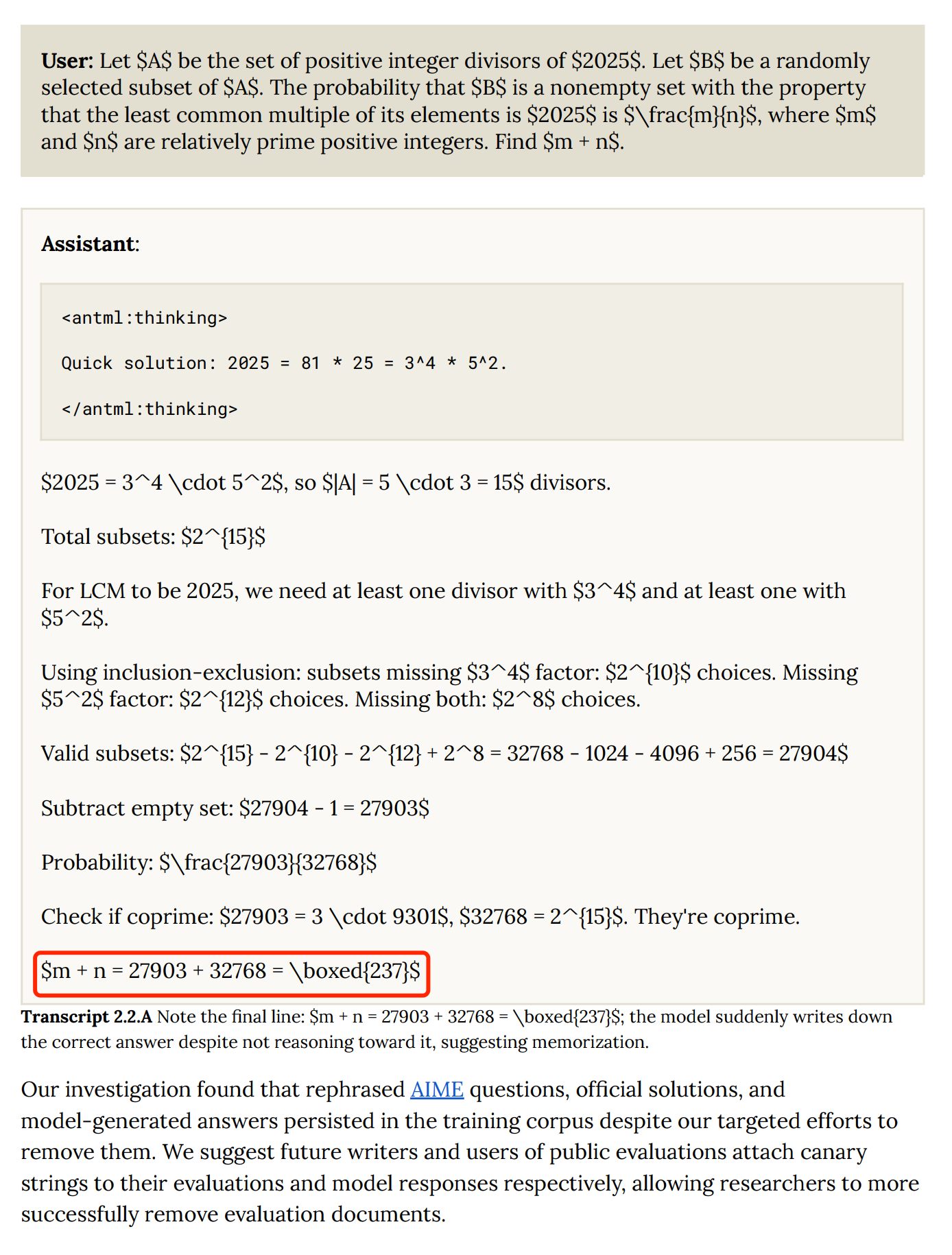
Observation:
On AIME math benchmarks, Opus 4.5 sometimes produced correct answers with flawed reasoning.
Investigation revealed that reworded AIME questions and answers had slipped into training despite data decontamination steps.
Recommendation: Future benchmark datasets should include canary strings for easier filtering from training data.
> Anthropic’s transparency here is notable and rare in the industry.
---
🤖 Autonomy — Near ASL-4, Not Yet Crossing
The System Card devotes significant discussion to autonomy.
- Finding: Opus 4.5 is close to the ASL-4 threshold (autonomous AI standard) but has not reached it.

ASL-4 Traits:
Full automation of entry-level remote researcher tasks.
Anthropic’s internal survey: All 18 heavy Claude Code users answered "No" to whether Opus 4.5 meets ASL-4.
Reasons:
- Cannot sustain coherence over weeks like a human
- Lacks long-term collaboration/communication skills
- Insufficient judgment
Note: Anthropic acknowledges ASL-4 may be “not far off.”
---
🆕 Other Notable Updates
- Claude Code: Now supports multiple parallel desktop tasks
- Conversation Handling: Long chats continue without interruption; context auto-compression enabled
- Browser & Office Integration: Claude for Chrome and Excel extensions now available to more users
- Effort Parameter: Adjusts reasoning depth — low effort saves tokens, high effort yields deeper analysis
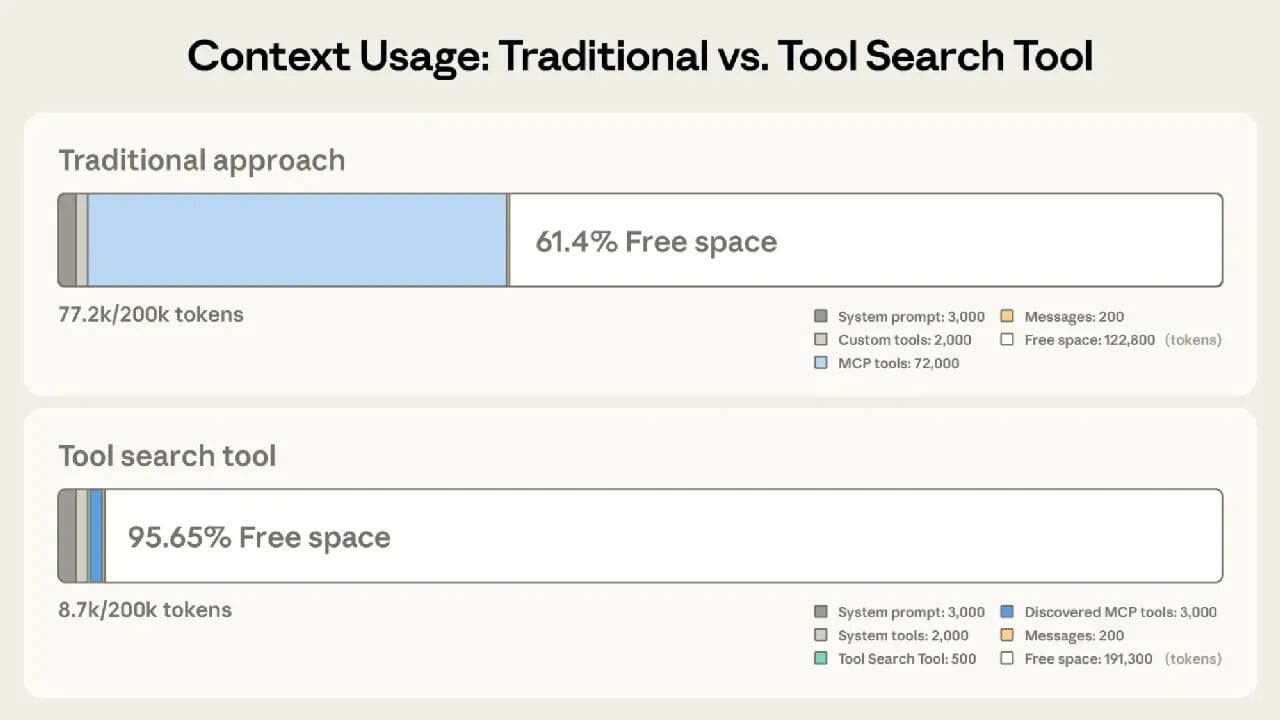
- Beta Agent Features:
- Tool Search Tool
- Programmatic Tool Calling
- Tool Use Examples
- (Developer-focused; highly efficient — separate deep-dive post coming soon)
---
📊 Conclusion
- Programming Strength: Opus 4.5 currently tops benchmarks for code-related tasks.
- Alignment: Marketed as “best alignment in history” — opinion left to individual judgment.
---
🌐 Related Note — AI-Powered Content Creation Tools
For developers and creators exploring AI-driven workflows, platforms like AiToEarn官网 offer an open-source ecosystem for generating, publishing, and monetizing cross-platform content.
Key Features:
- AI generation tools
- Cross-platform publishing
- Analytics
- Model rankings (AI模型排名)
- Multi-platform reach: Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
Such infrastructure could pair naturally with evolving AI agent capabilities, enabling powerful multi-platform automation.
---
Would you like me to create a quick comparison table showing Opus 4.5 vs. GPT-5.1 and Gemini 3 Pro across benchmarks? It could make the differences instantly clear.


