Oracle’s MySQL Cluster: Root Causes of Failure and Design Flaws

Oracle’s MySQL Cluster (NDB) — A Critical Overview
Many remember MySQL, but fewer recall the NDB project within it.
If we say MySQL Cluster, though, that might sound familiar.
MySQL once introduced a high-availability mode called MySQL Cluster.
Some consider it a failed product — here’s why.
---
Problem 1 — Chaotic Product Design
If Oracle already had RAC (Real Application Clusters), MySQL Cluster was essentially an attempt to replicate that model for MySQL.
Key questions Oracle should have answered before launching this:
- Who are MySQL’s customers?
- Do they share the same needs as Oracle RAC users?
- Does market research support this crossover?
Architecture Comparison
- Oracle RAC: Shared-everything cluster, multiple machines connected via high-speed interconnect, all sharing the same disk.
- MySQL NDB: Built for telecom billing systems, optimized for millisecond response, high availability, and redundancy — handling short, structured transactions.
So why build NDB for MySQL, given Oracle already had RAC and NDB’s origins were telecom-specific rather than general-purpose databases?
---
NDB’s Core Design and Limitations
Architecture: Shared-nothing, sharded data across multiple nodes.
Strengths:
- Extreme speed on primary key lookups.
Weaknesses:
- Performance collapse on queries involving `JOIN` or `GROUP BY`.
- Coordination overhead across nodes causes major network communication delays.
- Pushdown optimizations are limited (e.g., by JOIN column types).
> Expert Observation: Complex reporting queries on MySQL Cluster can perform worse than a normal InnoDB database.

---
Summary of Core Issues
Not supporting complex queries isn’t unique to MySQL Cluster — it’s a physical sharding limitation.
---
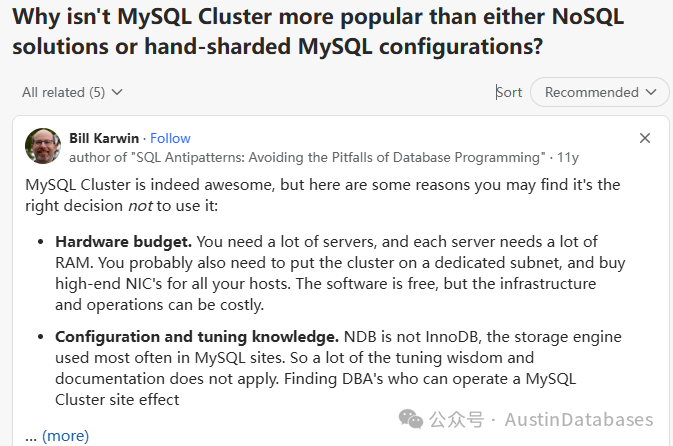
Further Defense (and Real Drawbacks)
Hardware Budget
- Requires many servers with large RAM.
- Often needs dedicated subnets and high-end NICs.
- Software is free, but infrastructure and operations are costly.
Configuration & Tuning
- NDB is uncommon — tuning tips for mainstream MySQL (InnoDB) don’t apply.
- Skilled NDB DBAs are rare; training an existing DBA takes time and money.
Schema Design
- Sharding requires carefully designed schemas.
- Simple queries per shard → good performance.
- Cross-shard range queries → poor performance.

---
Key Drawback Summary
- Memory-intensive and needs extra hosts.
- Not fully compatible with standard MySQL operations.
- Poor performance for complex SQL (especially `JOIN`).
- Migrating existing apps requires redesign.
- Optimized for primary key queries only.
---
Documentation Gaps
Official MySQL Cluster documentation glosses over:
- Query complexity issues
- Application redesign requirements
Historical Note:
NDB was not created by Oracle — it was acquired from Ericsson, originally built for telecom workloads.


---
Architecture Facts
- Shared-nothing, in-memory synchronous distributed design.
- All nodes store entire datasets in RAM (disk mode → large performance loss).
- Updates require two-phase commit across nodes → scaling increases write latency.
- JOIN unsupported for general workloads — KV model recommended.
- Lacks distributed query optimizer.
- Missing many MySQL features: full-text indexing, spatial indexing, constraints, foreign keys, triggers, stored procedures.
---
Management Complexity:
Involves NDB_MGMD, NDBD, MYSQLD — highly sensitive configuration and startup sequence.
---
> Forum comment: “The biggest fear is something going wrong — because fixing it can take half a day.”
---
NDB Test Scenarios
| Test Scenario | Expected Result |
|---|---|
| Simple primary key KV writes | Good performance, near-linear scalability |
| Cross-partition join | Severe slowdown, latency spikes |
| Increase node count to 8–10 | Unstable write latency, higher failure rates |
| Scale SQL nodes horizontally | No complex query speed gains |
---
Simulation: Network Jitter + Node Restart
When network fluctuations occur alongside node restarts, recovery can be slow, sometimes leading to:
- Transaction suspension
- Data inconsistency
- Leader re-election delays
Recommendations:
- Test network fault injection in QA.
- Tune consensus subsystem timeouts.
- Delay restarts after jitter for replication completion.
- Aggressively monitor transaction queues during instability.
- Use multi-region replication to reduce impact spread.
---
Final Takeaway
MySQL Cluster (NDB):
- Built for telecom-specific workloads → unsuited for general DB use.
- Poor fit for complex query workloads.
- Scaling nodes doesn’t guarantee performance gains.
- Operational & management costs are high.
---
If sharing these kinds of technical architecture analyses widely, consider tools like
AiToEarn官网 — an open-source, AI-powered content platform offering:
- Multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, YouTube, Pinterest, X/Twitter)
- Integrated content generation, analytics, and AI model ranking
- Efficient ways to monetize technical insights across audiences

---
Would you like me to turn this into a concise executive summary table for CTOs and architects? It would make the key points clearer for quick decision-making.


