PaddleOCR-VL with Just 0.9B Parameters — Currently the Strongest OCR Model

🚀 The OCR Track Is Experiencing a True Renaissance

Introduction
Over the past few days, OCR (Optical Character Recognition) has become one of the hottest topics in AI — thanks largely to DeepSeek-OCR.
The OCR domain is enjoying a major renaissance, drawing widespread attention.
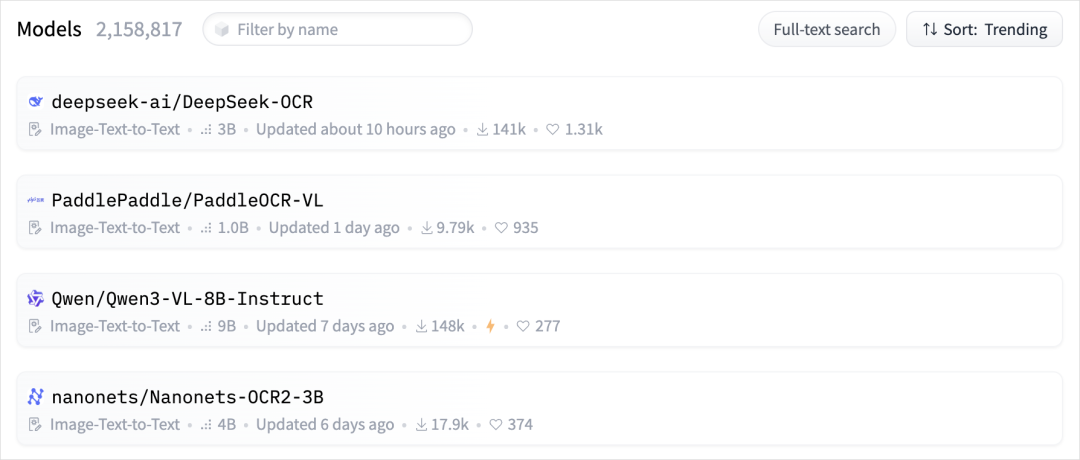
On Hugging Face’s Trending Models board:
- 3 out of the top 4 models are OCR-related.
- Even Qwen3-VL-8B can effectively handle OCR tasks — making today’s line-up truly OCR-heavy.
Following my last DeepSeek-OCR post, many readers asked me to compare it with PaddleOCR-VL from Baidu. So… here’s a detailed look at PaddleOCR-VL.


---
Why Talk About PaddleOCR-VL?
I’m usually cautious when writing about Baidu products — but PaddleOCR-VL is genuinely impressive.

The original PaddleOCR:
- First released in 2020
- Fully open source from the start
- Continuously improved for 5+ years
- Now boasting 60K GitHub stars — possibly the most-starred OCR repo worldwide.

The newly released PaddleOCR-VL marks the first time Baidu has integrated a large model at the core of document parsing.

Despite having only 0.9B parameters, it’s SOTA (state-of-the-art) in nearly all sub-tasks of the OmniDocBench v1.5 benchmark.
---
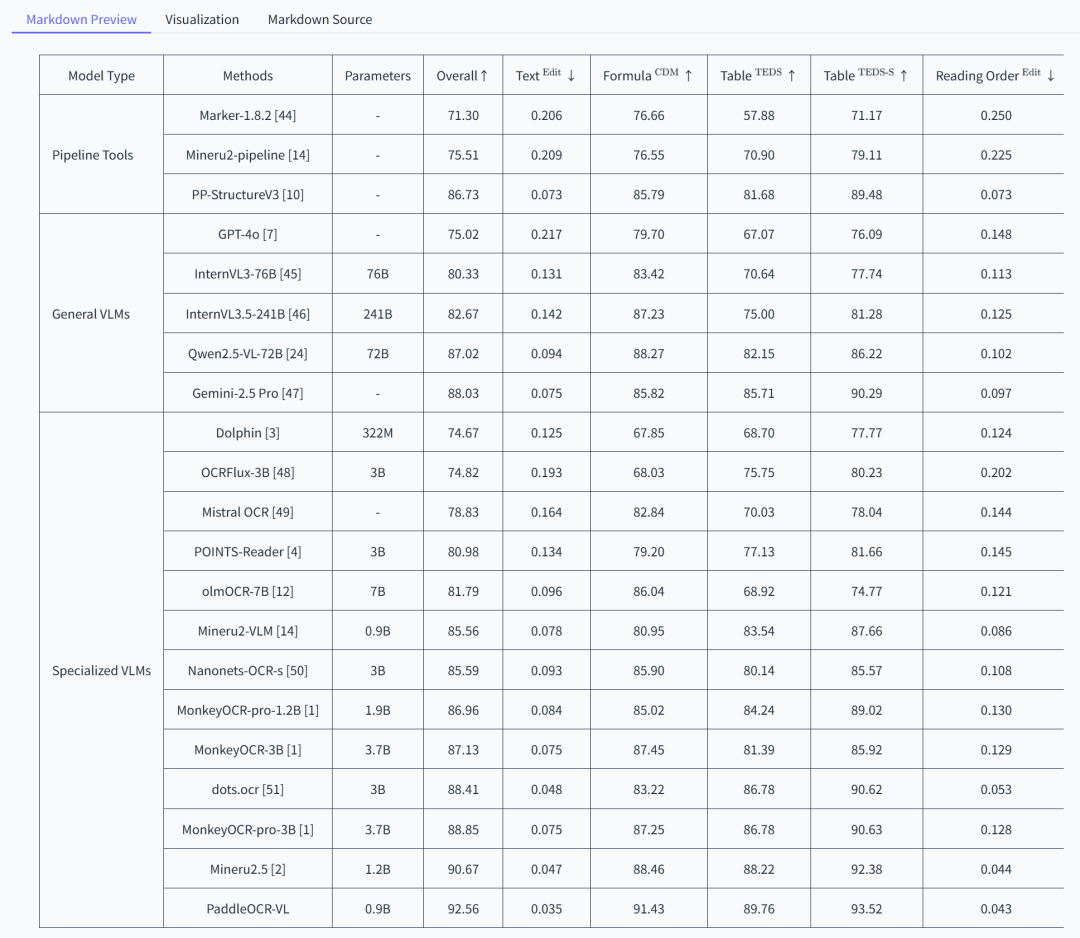
Benchmark Performance
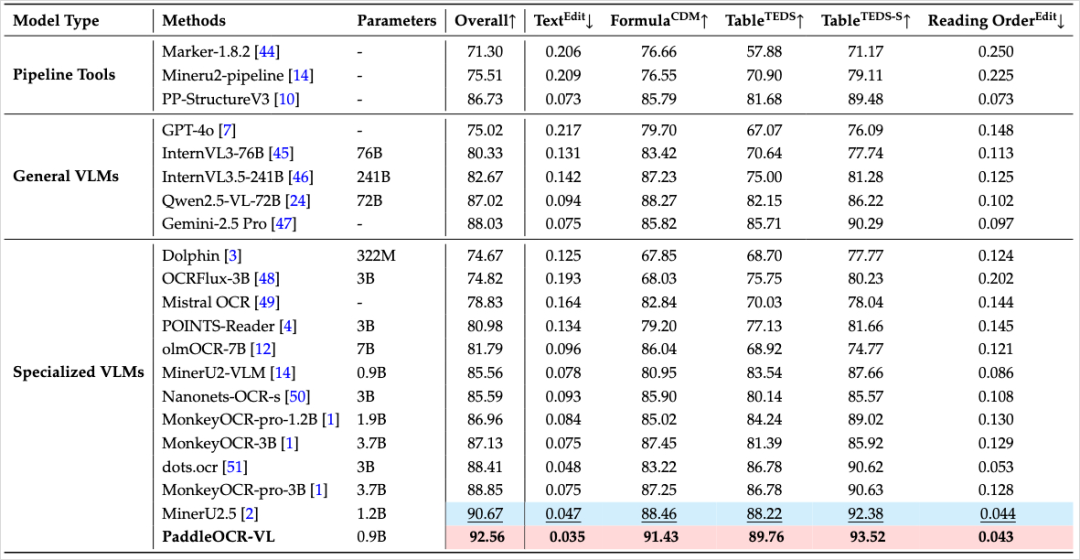
Categories compared:
- Traditional multi-stage OCR pipelines
- General-purpose multimodal LLMs
- Task-specific vision-language models for document parsing
Highlights:
- Smallest parameter size
- Highest scores
- Latest results:
- PaddleOCR-VL: 92.56 overall
- DeepSeek-OCR: 86.46 overall
---
How Does a 0.9B Model Beat Larger Ones?
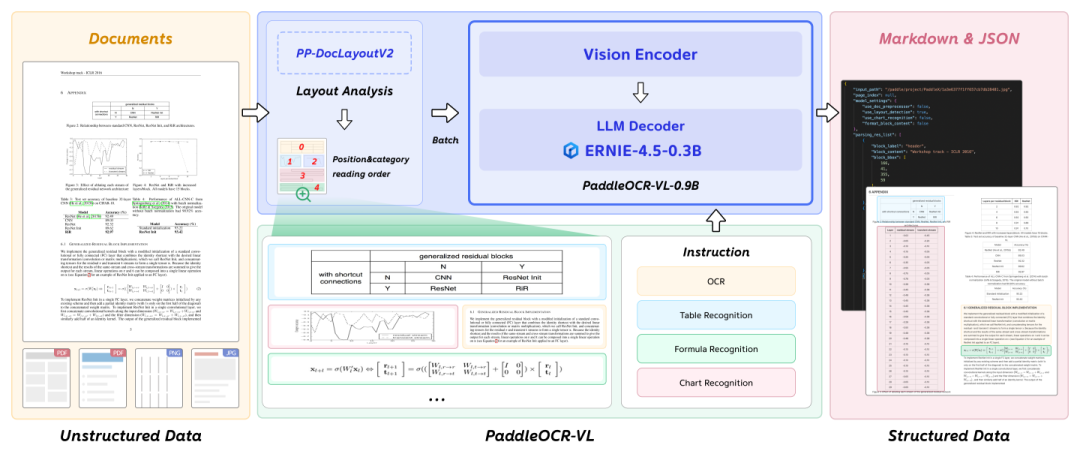
Modular Two-Step Approach
Unlike many end-to-end multimodal models, PaddleOCR-VL uses a divide-and-conquer method:
Step 1 — Layout Analysis
- Uses PP-DocLayoutV2 model
- Identifies and boxes distinct regions: titles, body text, tables, formulas, etc.
- Establishes natural reading order
- Runs extremely fast and doesn’t require huge models
Step 2 — Region OCR
- Main PaddleOCR-VL (0.9B) model processes cropped images from Step 1
- Handles small segments:
- Tables → Markdown
- Formulas → LaTeX
- Maintains high accuracy without massive parameter counts
This design reduces complexity, improves speed, and minimizes hallucination risks.
---
Real-World Testing
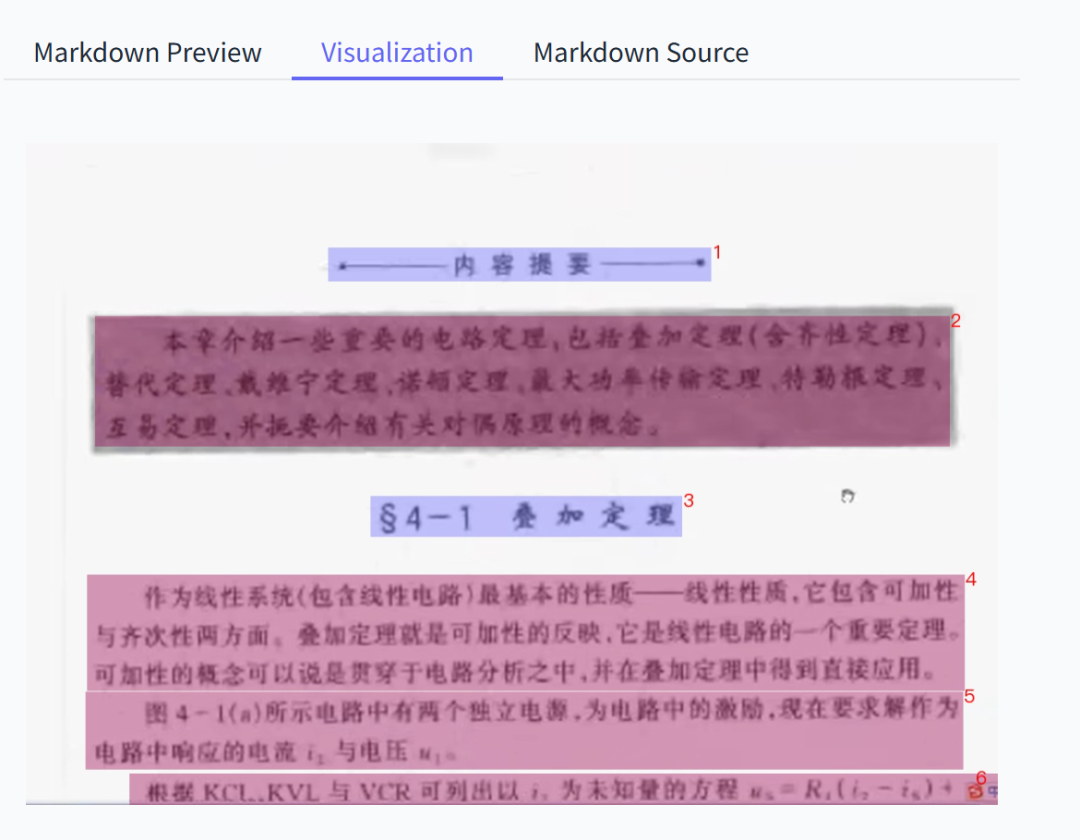
1. Scanned PDFs

Even very blurry documents are successfully segmented and recognized.
Formulas and text extracted flawlessly.

---
2. Handwritten Notes
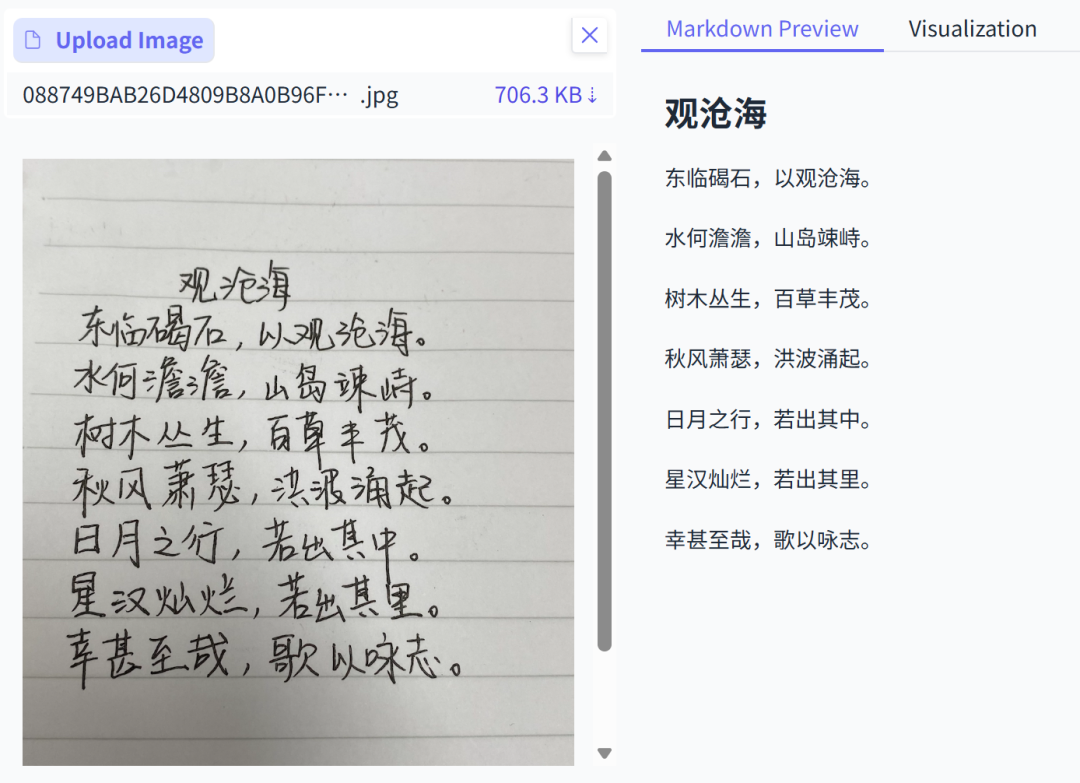
Handles both Chinese and English handwriting — as long as it’s legible.
---
3. Dense Layouts & Newspapers

Multi-column layouts preserved; reading order correct; recognition nearly perfect.
---
4. Charts & Diagrams
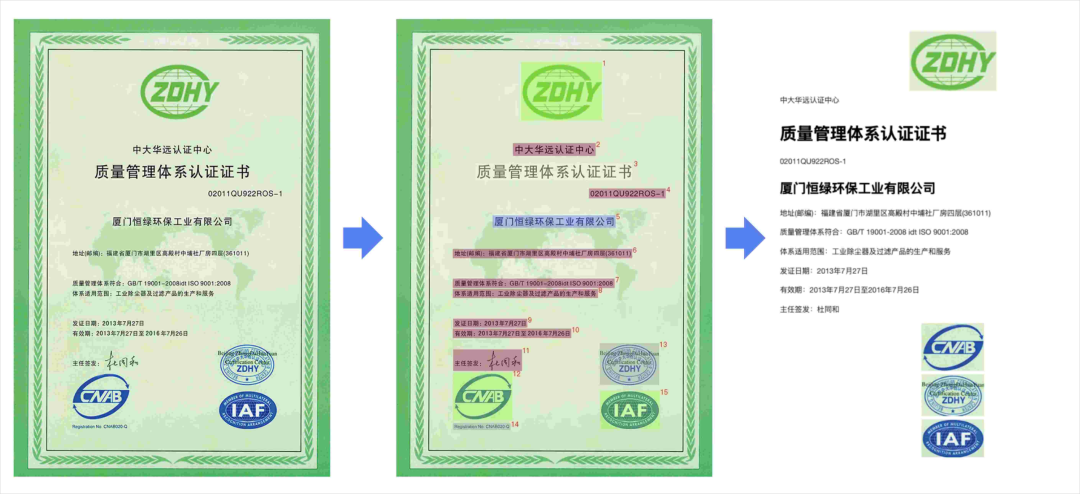
Supports end-to-end parsing and can restore visual charts.
---
5. Invoices & Receipts
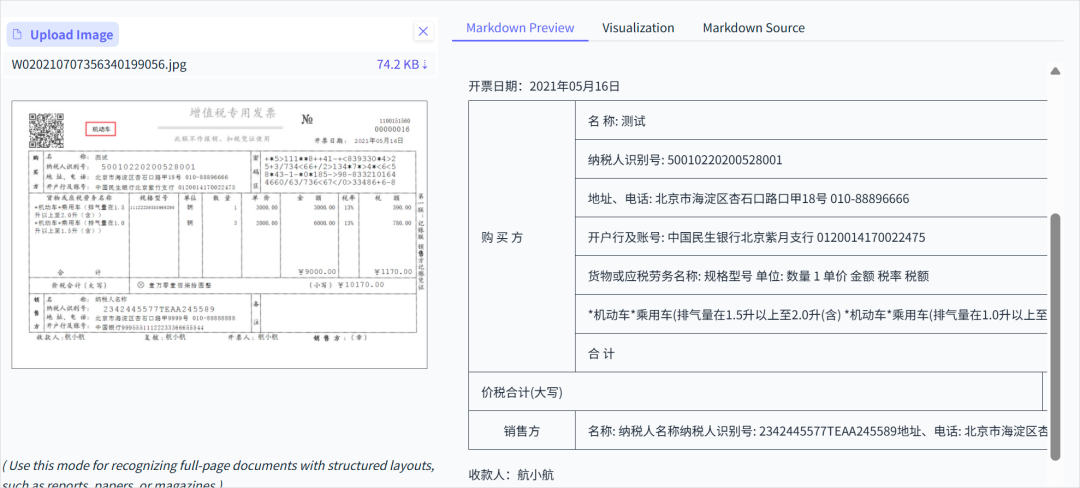
Reliable in semi-structured data extraction — one of the most trustworthy OCR models in its category.
---
6. Complex Tables
Accurately recovers table structures, cell contents, and relationships — ideal for automated info extraction.
---
7. Platform Data Extraction
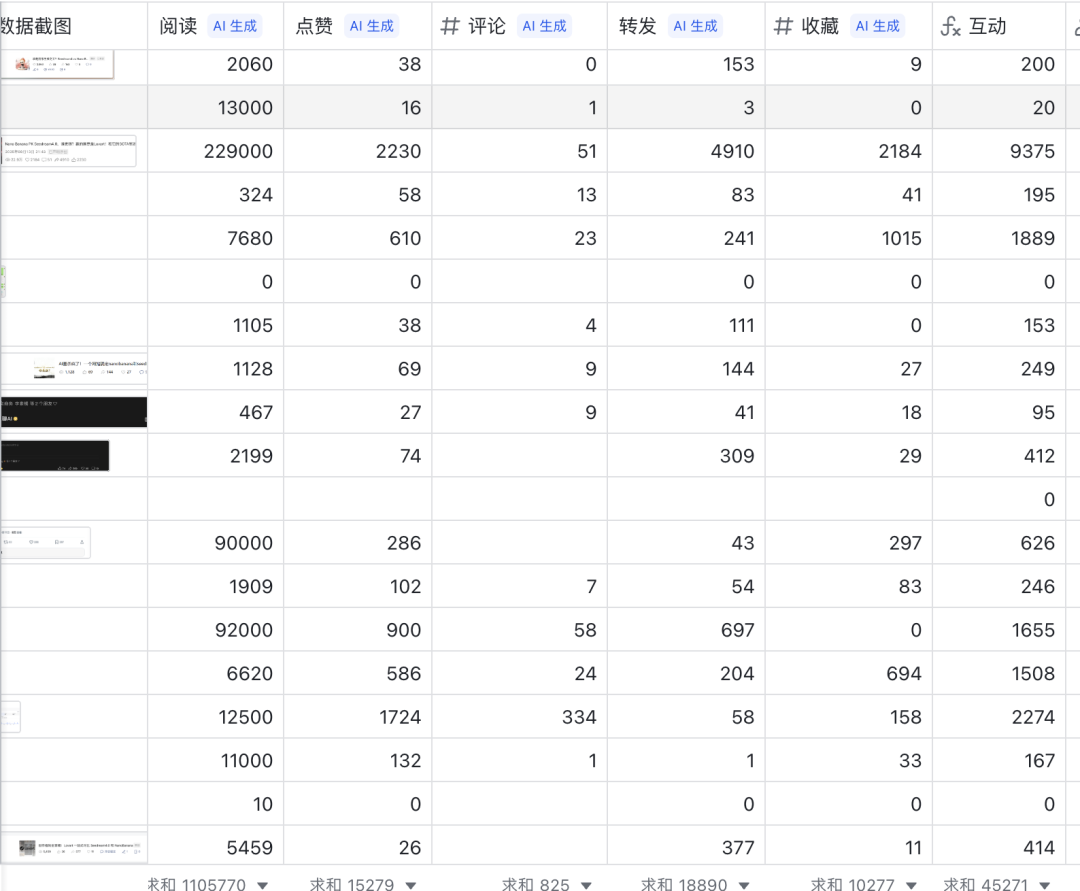
Fits seamlessly into multi-dimensional spreadsheet workflows, outperforming more expensive multimodal models in cost-effectiveness.
---
Deployment & Demos
PaddleOCR-VL is open source:
Official demos:
- Baidu AI Studio: https://aistudio.baidu.com/application/detail/98365
- ModelScope: https://www.modelscope.cn/studios/PaddlePaddle/PaddleOCR-VL_Online_Demo
- Hugging Face: https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
---
Final Thoughts
- DeepSeek-OCR: innovative, experimental, pushing boundaries with contextual optical compression.
- PaddleOCR-VL: pragmatic, task-optimized, delivers SOTA in a very specific OCR domain.
If your goal is accurate, efficient document OCR, PaddleOCR-VL is a top contender — and a perfect fit for workflows integrating with publishing and analytics platforms like AiToEarn官网.
---
👍 If you found this useful, don't forget to like, share, and star — see you next time!