Please, Stop Letting Your GPU Slack Off in Public!

Why Your GPU Is Probably Idle — And How HAMi Fixes That
Most of the time, your GPU’s computing power is idle, with utilization often dropping below 20%.


---
Expensive GPUs, Low Usage
Let’s look at a few tempting — and wallet-draining — models: NVIDIA A100 80GB, H800 80GB, RTX 4090 24GB...

These AI‑era “super engines,” whether bought outright for a hefty sum or rented at a high cost, are only available as complete units. Outside of full‑scale model training, they’re often used for inference, development, or testing — activities that don’t require dozens or hundreds of GB of VRAM running at full tilt.
In most cases, your GPU power is just sitting idle, running at less than 20% utilization.
Idle GPUs in today’s world are burning cash, not “resting.”
---
The Pain Points
- AI Team Leaders: Struggling with massive compute bills and constant “we need more GPUs” complaints.
- MLOps / Platform Engineers: GPU cluster utilization below 20%, but still dealing with endless resource contention tickets.
- AI Algorithm Engineers: Waiting hours in queues for an under‑utilized A100 or H800 just to run preprocessing, validation, or debugging.
---
Introducing HAMi — your open-source solution to idle GPU waste.
> GitHub: github.com/Project-HAMi/HAMi
---
What is HAMi?
HAMi is an open‑source heterogeneous AI computing virtualization middleware for Kubernetes, started by Shanghai Migua Intelligence.
Its core capability:
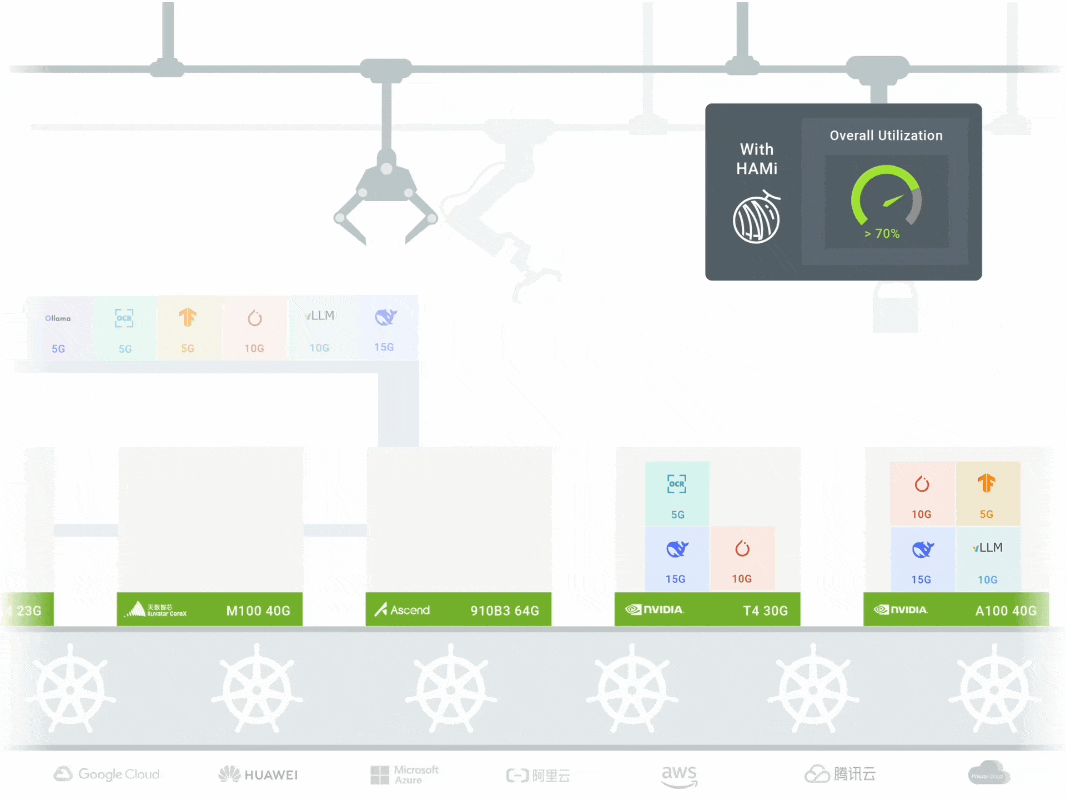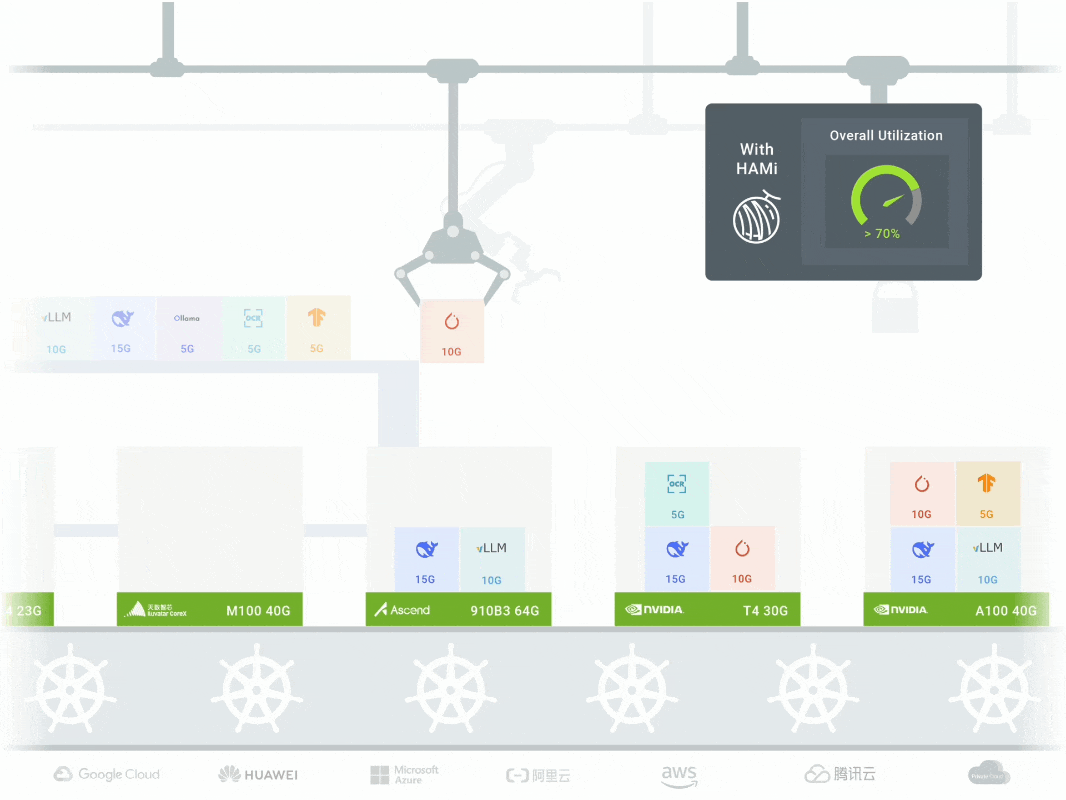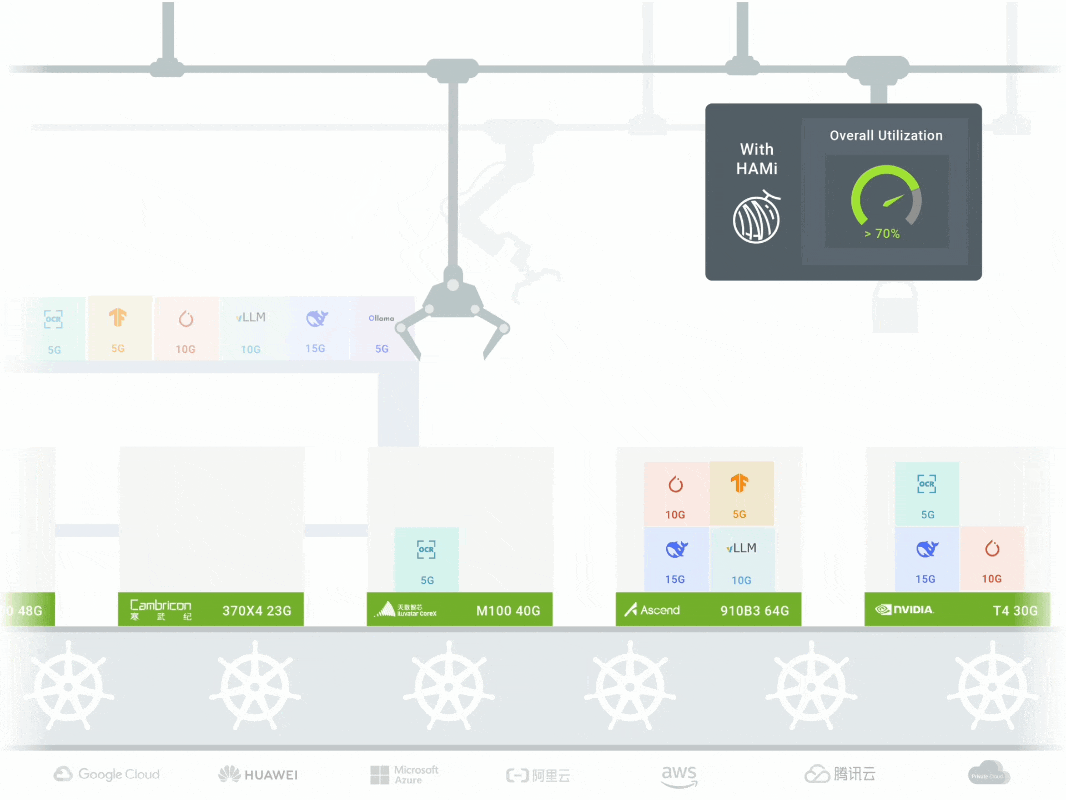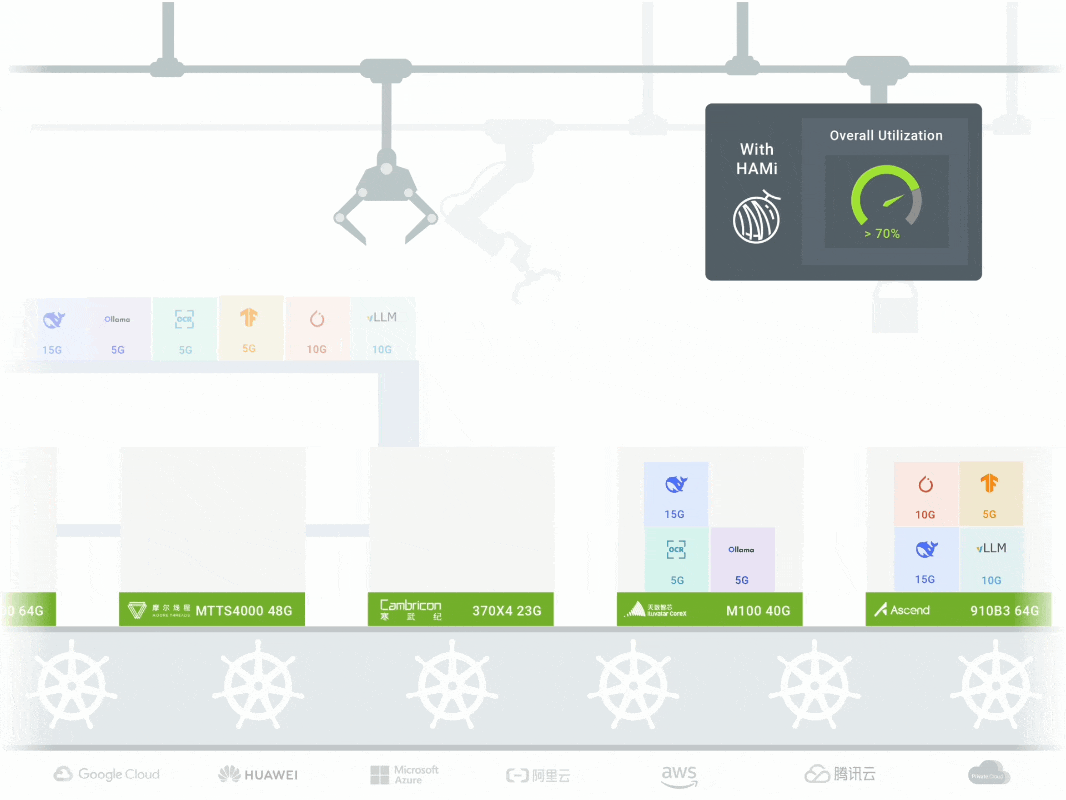
- Slices a physical GPU into multiple virtual GPUs (vGPUs)
- Allocates them on demand to different workloads (Pods)
- Offers fine‑grained resource sharing and isolation
No changes to your AI application code are required.
---
1. The Two “Traps” of GPU Sharing
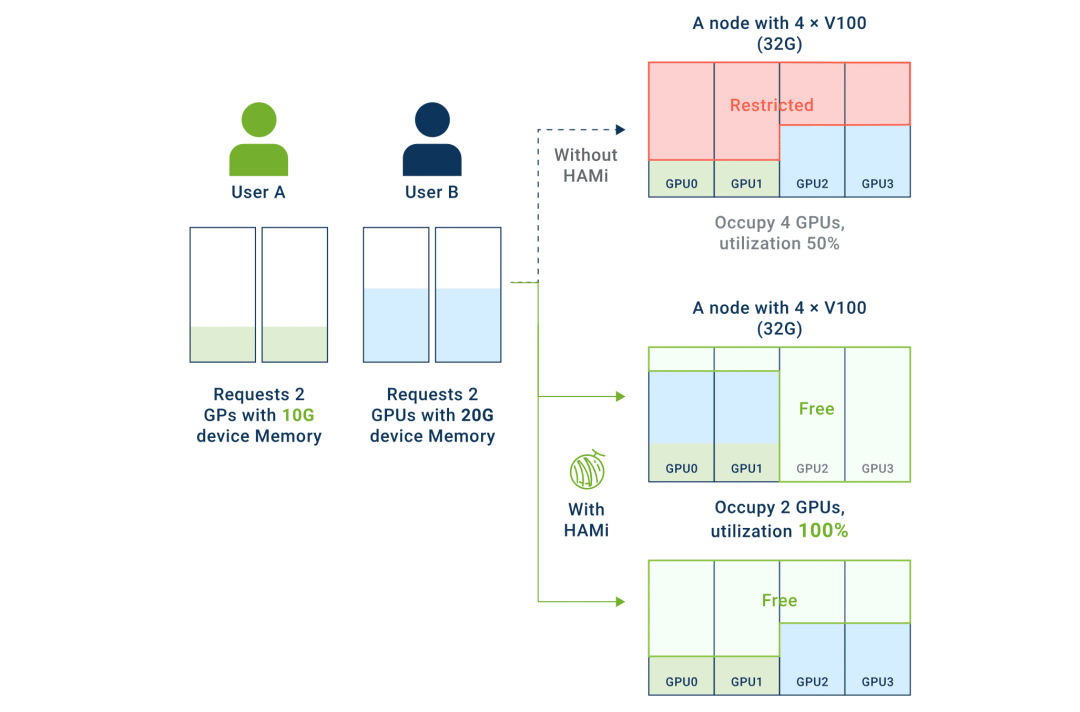
A GPU provides two core resources: VRAM and compute cores. Without control, native sharing runs into issues:
- VRAM Exclusivity — A process must load enough VRAM before it can run. In uncontrolled sharing, it’s “first‑come, first‑served,” causing OOM errors for others.
- Chaotic Compute Competition — Multiple tasks sharing cores means one heavy task can monopolize them, slowing everyone else down.
---
HAMi’s Solution
VRAM: Hard Isolation
- Assigns each task a fixed virtual VRAM space (e.g., 2GB per pod).
- Prevents one task’s overuse from causing OOM errors in others.
Compute: Proportional Allocation
- Assign a percentage of compute (e.g., 30%) to each task.
- Guarantees predictable performance without performance “jitter.”
---
In workflows from training to inference, HAMi maximizes GPU utilization, reduces costs, and frees budget for innovation.
---
2. Easy Kubernetes Integration
Traditionally, Kubernetes requires a pod to occupy an entire GPU card. HAMi changes that — you can now request resources like “1GB VRAM, 30% compute.”
Install in 3 Helm Commands
# 1. Label the GPU-enabled node
kubectl label nodes {nodeid} gpu=on
# 2. Add HAMi chart repo
helm repo add hami-charts https://project-hami.github.io/HAMi/
# 3. Install HAMi in kube-system namespace
helm install hami hami-charts/hami -n kube-systemOnce `hami-device-plugin` and `hami-scheduler` Pods are running, you can request vGPUs:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 1024
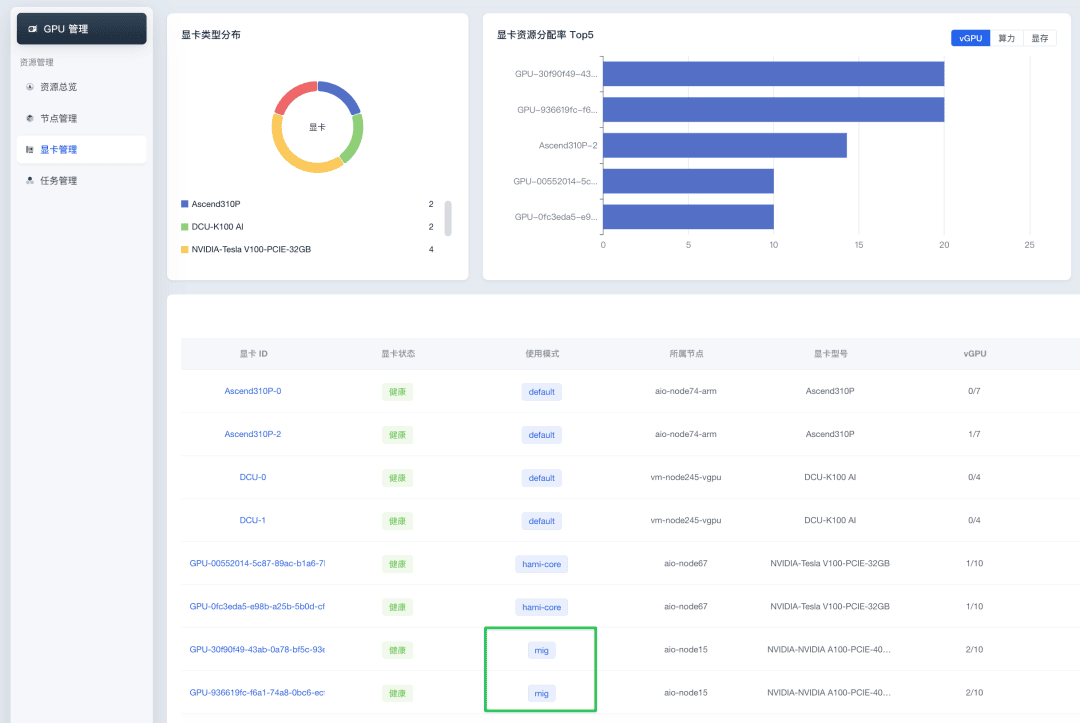
nvidia.com/gpucores: 30HAMi also includes HAMi-WebUI for visual management.
---
3. Technical Core of HAMi
HAMi’s magic is done via HAMi-core — a dynamic library (`libvgpu.so`) that hooks into CUDA APIs.
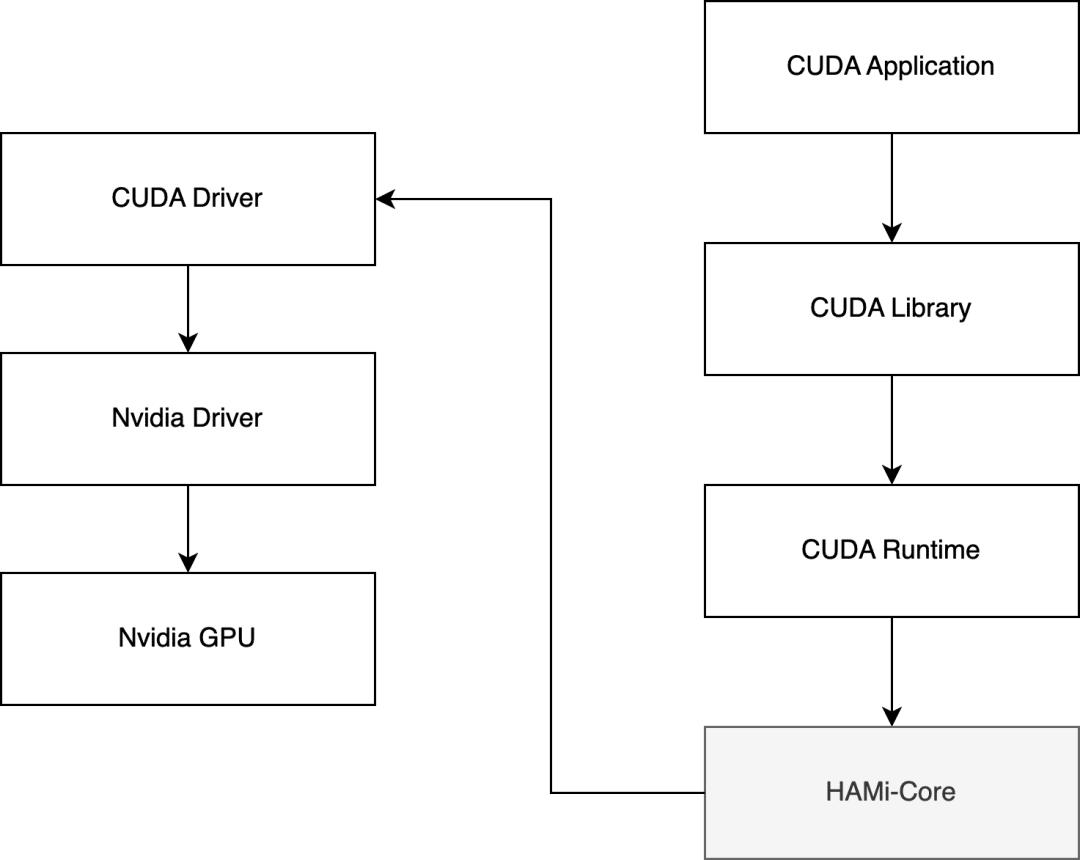
Using `LD_PRELOAD`, HAMi intercepts CUDA calls, applies limits (VRAM, cores), and responds as if the application had a full GPU — enabling virtualization and monitoring without the program knowing.
---
3.2 Local GPU Virtualization (Docker)
You can run HAMi-core without Kubernetes, even locally:
Step 1: Build Docker image with HAMi-core
docker build . -f=dockerfiles/Dockerfile -t cuda_vmem:tf1.8-cu90Step 2: Setup environment mounts
export DEVICE_MOUNTS="..."
export LIBRARY_MOUNTS="..."Step 3: Run container with limits
docker run ${LIBRARY_MOUNTS} ${DEVICE_MOUNTS} -it \
-e CUDA_DEVICE_MEMORY_LIMIT=2g \
-e LD_PRELOAD=/libvgpu/build/libvgpu.so \
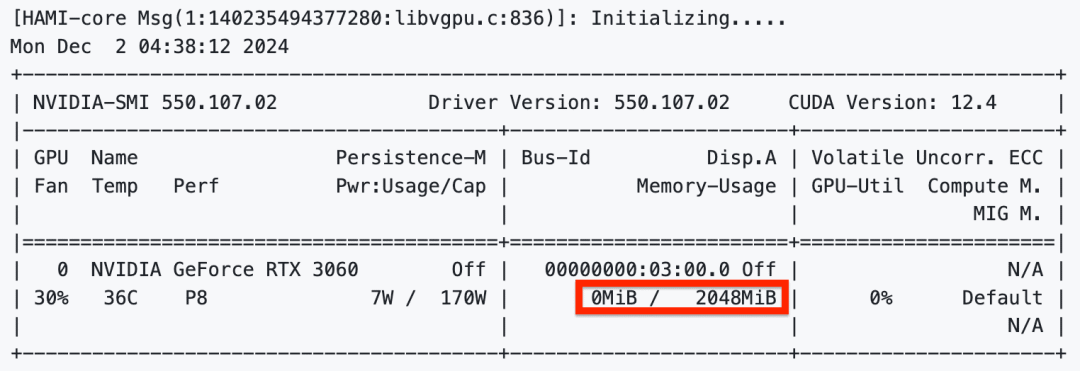
cuda_vmem:tf1.8-cu90Inside this container, `nvidia-smi` will show exactly 2048MB memory.
---
4. Why Choose HAMi?
- Reduce Cost & Boost Efficiency — Run more tasks per GPU, instantly doubling utilization.
- Supports Domestic AI Chips — Works with NVIDIA, Cambricon, Hygon, Ascend, etc.
- CNCF Sandbox Project — Legitimate, cloud-native, with strong community backing.
- Proven in Production — Used by SF Express, AWS, and other enterprises.

---
5. Final Thoughts
In the AI “arms race,” precise and economical compute usage wins. HAMi is the Swiss Army Knife for GPUs — unassuming, elegant, and powerful.
Don’t let your GPU idle — put it to work!
- GitHub: github.com/Project-HAMi/HAMi
- Community Update: HAMi 2.7.0 Major Release
---
Bonus: Monetize Your AI Output
If you’re building AI-powered projects, AiToEarn官网 can complement HAMi’s efficiency. AiToEarn:
- Open-source global AI content monetization platform
- Connects AI generation tools, cross-platform publishing, analytics, and model ranking (AI模型排名)
- Publishes simultaneously to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter)
For HAMi users creating AI services or demos, AiToEarn offers a natural extension to share and monetize your work worldwide.
---
Would you like me to also add a quick “HAMi vs alternatives” comparison table so readers can instantly see why HAMi stands out? That could make this Markdown even more reader‑friendly.