Precisely Targeting "Tough Nuts": Hard Sample Filtering Breaks SFT Dependence, GRPO-Only Achieves Dual Optimality in Perception and Reasoning
A set of new experiments accepted by AAAI 2026 tackles one of the toughest challenges in post-training large multimodal models head-on.
On two major benchmark categories — visual reasoning and visual perception — a GRPO-only paradigm, trained solely on medium + hard samples and without any SFT (supervised fine-tuning), achieves nearly all the best results.
MathVista score: 68.3, OCRBench: 77.8, MMMU improvement: 0.107, MMStar improvement: 0.083 — all representing significant jumps compared to full-data training, and even surpassing the traditional “SFT + RL” two-stage paradigm.
The conclusion is straightforward:
> In multimodal post-training, sample difficulty is more critical than training paradigm, and SFT is not necessarily a prerequisite for RL.
---
This new research, carried out by Central South University & ZTE Corporation, establishes a quantifiable and actionable difficulty sampling standard for multimodal large models. For the first time, it systematically validates a training approach previously thought to be “impossible to work”:
optimizing multimodal capability using RL (GRPO) alone, with no prior SFT.
The authors focus precisely on two long-standing bottlenecks in multimodal post-training:
---
1. Lack of quantifiable sample difficulty metrics
Multimodal data include both visual and textual features. The difficulty in the text modality often cannot directly represent the difficulty of the overall multimodal sample (e.g., OCR, object detection). Thus, pure-text difficulty classification methods are not applicable, making it hard to filter out the most valuable training samples for optimization.
2. Training paradigms failing to co-optimize perception & reasoning
Current methods predominantly use a fixed “supervised fine-tuning + RL fine-tuning” process. Most research focuses on boosting reasoning ability, yet multimodal scenarios typically blend visual reasoning tasks (math, science, chart analysis) with visual perception tasks (object detection, localization, counting, OCR). A single paradigm often cannot meet both data type requirements, leading to imbalanced performance between perception and reasoning.
---
To address these challenges, the team introduces two complementary difficulty quantification strategies from intra-modal sensitivity and cross-modal interaction complexity perspectives:
- PISM (Progressive Image Semantic Masking)
- CMAB (Cross-Modal Attention Balance)
These strategies enable hierarchical training and prove that RL alone can independently optimize multimodal capabilities — opening a fresh technical path for multimodal post-training.
---
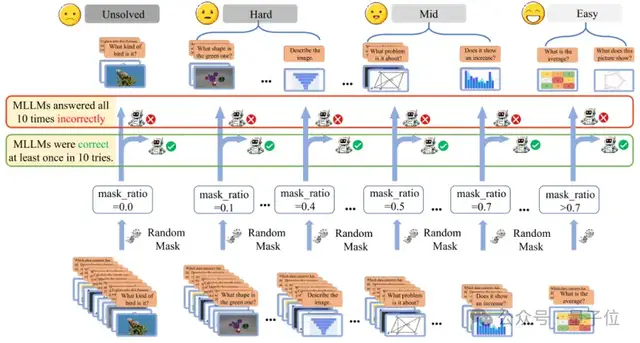
PISM: Progressive Image Semantic Masking
Below is a schematic of the PISM method:
From no mask (mask_ratio = 0.0) to heavy masking (mask_ratio > 0.7), the team progressively masks different parts of an image.
---
Each masked image randomly hides a certain percentage of pixel regions, simulating various degrees of visual information loss. The model’s performance on these masked images reveals how strongly it depends on visual detail to reason accurately.
Core Hypothesis: Hard samples are more sensitive to loss of visual information.
The PISM approach quantifies difficulty through systematic image degradation experiments.
---
Workflow:
1. Mask Design
For each image-text pair \( s = (I, Q) \), define a mask ratio set
\( \Lambda = \{\lambda_i \ | \ \lambda_i = 0.0, 0.1, \dots, 0.9\} \), simulating scenarios from no degradation (\(\lambda = 0.0\)) to heavy degradation (\(\lambda = 0.9\)).
2. Performance Evaluation
For each mask ratio \( \lambda_i \), produce disturbed images:
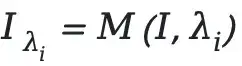
\( M(\cdot) \): random pixel masking operation.
Feed the masked image into the model to get predictions:
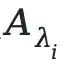
Evaluate using binary correctness metrics:
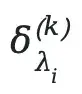
(1 = correct, 0 = incorrect).
3. Robustness Calculation
Repeat each mask ratio experiment \( K = 10\) times to reduce randomness. Calculate robust accuracy:
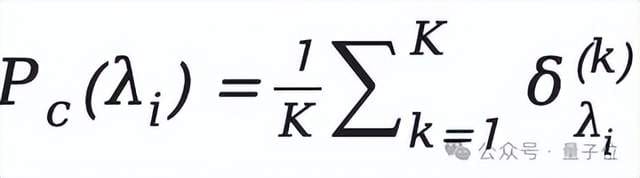
4. Difficulty Classification
Define a failure threshold:
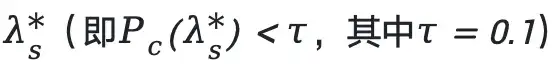
Accordingly, classify samples into 4 categories.
---
By using PISM and CMAB, the researchers demonstrate that fine-grained difficulty-aware sampling allows reinforcement learning to achieve both reasoning and perception improvements without any SFT — a result that could redefine multimodal fine-tuning workflows.
Interestingly, in the broader context of AI-powered content creation, difficulty-based strategies are also relevant for optimizing outputs. Platforms like AiToEarn官网 apply modular AI pipelines combining generation, cross-platform publishing, analytics, and model ranking. For creators working across channels such as Douyin, Kwai, WeChat, Bilibili, Instagram, and YouTube, the precise matching of task difficulty to AI capabilities — much like in PISM — can maximize efficiency and monetization potential.

The diagram above illustrates the Cross-Modality Attention Balance (CMAB) method.
For each generated token, we compute its average attention score to the input text tokens and image tokens across all Transformer layers, then take the average of these scores over all generated tokens.
(N) represents the total number of Transformer layers.
---
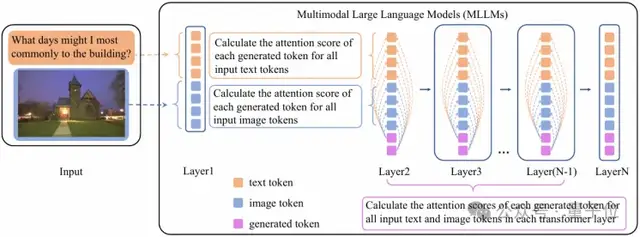
As shown in the figure above, CMAB evaluates the complexity of cross-modal interaction by analyzing the ratio of the model’s attention to text versus image when generating responses. The specific logic is as follows:
1. Attention Decomposition
For an input image:
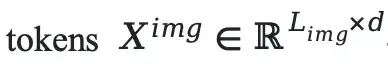
and text:
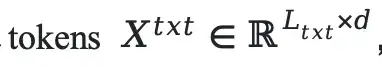
We calculate the cross-modal attention weight in layer l of the Transformer for each response token \(y_t\):
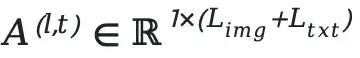
This is then decomposed into image attention sum:
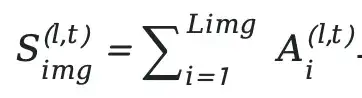
and text attention sum:
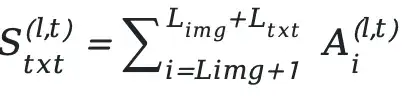
---
2. Attention Balance Ratio Calculation
We define the token-level cross-layer attention balance ratio:
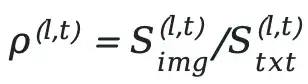
To reduce inter-layer noise, we exclude the first and final layers (mainly responsible for input encoding and output decoding) and use the geometric mean:
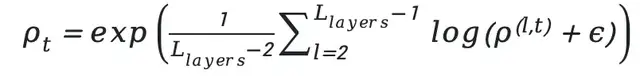
(ε ≈ 10⁻⁸ to avoid numerical instability).
---
3. Sample-Level Balance Ratio
We take the arithmetic mean across all response tokens to obtain the sample-level attention balance ratio:
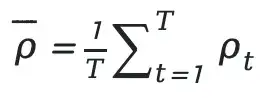
---
4. Difficulty Categorization
Based on:
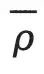
we classify sample difficulty:

Based on PISM and CMAB difficulty stratification results, two post-training paradigms were designed for comparison:
First — GRPO-only Paradigm
Directly apply Group Relative Policy Optimization (GRPO) to difficulty-stratified samples (medium + hard) without SFT pre-processing.
Second — SFT+GRPO Paradigm
First apply Supervised Fine-Tuning (SFT) to filtered samples (e.g., hard samples, medium samples), then apply GRPO to the target samples. The experiment tests how difficulty order in SFT affects model performance (e.g., SFT(hard)+GRPO(medium) vs. SFT(medium)+GRPO(hard)).
---
Experiment Configuration
- Base Model: Qwen2.5VL-7B (multimodal large model supporting vision-text joint reasoning)
- Hardware: 5 nodes (each with 8×80GB NVIDIA A800 SXM4 GPUs) + 2 nodes (each with 8×96GB NVIDIA H20 GPUs)
- Framework Tools: SFT via LLaMA-Factory, GRPO via Swift framework, evaluation via OpenCompass, GPT-4o-mini as unified evaluator
- Benchmark Dataset: Multimodal tasks covering 6 general scenarios
---
Below is the table showing PISM stratification results with different training paradigms on visual reasoning datasets:
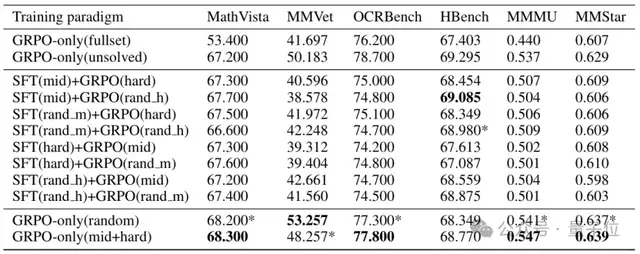
(Note: Table 1 compares SFT+GRPO vs. GRPO-only training results on visual reasoning datasets after PISM stratification. indicates second-best result; bold indicates best result.)*
Observation —
First, the GRPO-only (medium+hard) paradigm exhibits significant advantages.
---
In the context of multimodal reasoning research, tools that streamline data preparation, training workflows, and cross-platform publishing can help maximize the value of such experiments. For instance, AiToEarn官网 provides an open-source global AI content monetization platform that enables creators and researchers to use AI to generate, publish, and monetize content efficiently across multiple platforms like Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, YouTube, and X (Twitter). By integrating generation tools, analytics, and model ranking (AI模型排名), AiToEarn offers a powerful ecosystem for those working with cutting-edge AI models, including multimodal architectures like those explored in CMAB studies.
On the four metrics — MathVista (68.300), OCRBench (77.800), MMMU (0.547), and MMStar (0.639) — the approach achieved the best overall performance, with the largest improvements compared to full-data GRPO-only (MathVista +14.9 points, MMMU +0.107).
Second, the SFT stage brings no gain.
All SFT+GRPO paradigms performed worse than GRPO-only (medium + hard), and the order of sample difficulty in the SFT stage had little impact on results (e.g., SFT(medium)+GRPO(hard) vs. SFT(hard)+GRPO(medium) yielded similar performance). This suggests that SFT may introduce pseudo chains-of-thought (Pseudo-CoT), constraining true reasoning ability.
Third, random sample performance is limited.
GRPO-only (random samples) performed well on some metrics (e.g., MMVet) but was overall inferior to medium+hard sample training results, confirming that difficulty-based stratification effectively filters for quality samples.
The following table shows performance across visual perception datasets for different training paradigms after CMAB stratification.
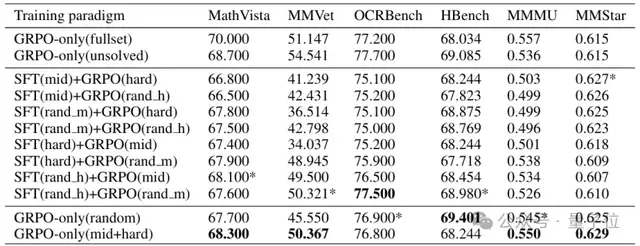
(Note: Table 2 compares SFT+GRPO and GRPO-only results on visual perception datasets after CMAB. An asterisk indicates second-best results; bold indicates the best.)
From the table, CMAB demonstrates clear advantages in reasoning tasks —
GRPO-only (medium + hard) achieved top scores in MathVista (68.300), MMVet (50.367), MMMU (0.550), and MMStar (0.629), especially in cross-modal deep fusion tasks (e.g., MathVista), improving 1.5–2.5 points over SFT+GRPO paradigms, validating CMAB’s effectiveness in assessing cross-modal interaction complexity.
From these experiments, the research team drew several conclusions:
First, difficulty-aware sampling is key.
Whether PISM or CMAB, GRPO-only training with medium+hard samples significantly outperformed full-data, random samples, and SFT+GRPO paradigms — proving that data quality (difficulty stratification) matters more than quantity.
Second, GRPO-only is viable.
The experiments challenge the traditional belief that “SFT is a necessary prerequisite for RL fine-tuning.” Removing SFT in favor of GRPO-only greatly simplifies training, increases post-training efficiency, and offers new avenues for general multimodal model training.
The study proposes a multimodal sample difficulty quantification standard, the first to measure from both visual sensitivity and cross-modal attention balance, establishing a quantifiable assessment system to solve the problem of “hard-to-filter” multimodal data.
By focusing on the core issue of “sample filtering” in multimodal post-training, this work provides a new technical path for improving multimodal large model performance and opens a fresh data-driven optimization perspective for future research.
Finally, the team outlined three directions for future work:
- Dynamic difficulty adjustment: Current evaluation is static; in the future, it can be updated dynamically during training to enable adaptive curriculum learning.
- Multi-strategy integration: Exploring combined sampling strategies from PISM and CMAB to further refine sample selection accuracy.
- Validation on larger models: Testing effectiveness on multimodal models with tens of billions of parameters, to explore the generalizability of difficulty-aware sampling at larger scales.
The research code is open-sourced, with an extended version including full experimental configurations, providing a reproducible technical foundation for subsequent studies.
The team hopes more researchers will build upon this method to advance practical multimodal AI applications in healthcare, education, autonomous driving, and beyond.
arXiv:
https://arxiv.org/abs/2511.06722
GitHub:
https://github.com/qijianyu277/DifficultySampling
To further explore how AI-generated content and cross-platform dissemination can accelerate multimodal AI research adoption, creators can leverage AiToEarn官网, an open-source global platform that helps generate, publish, and monetize content across major channels like Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). AiToEarn integrates AI generation tools, multi-platform publishing, analytics, and model rankings, enabling efficient monetization of AI creativity while extending research reach.


