Qdrant 1.16 - Hierarchical Multi-Tenancy & Disk-Optimized Vector Search

Qdrant 1.16.0 Release Highlights

---
On This Page
- Tiered Multitenancy Using Tenant Promotion
- ACORN – Filtered Vector Search Improvements
- Benchmarks
- When Should You Use ACORN?
- Inline Storage – Disk-efficient Vector Search
- Benchmarks
- Full-Text Search Enhancements
- Match Any Condition for Text Search
- ASCII Folding – Improved Search for Multilingual Texts
- Conditional Updates
- Web UI Visual Upgrade
- Honorable Mentions
- Upgrading to Version 1.16
- Engage
---
Overview
Qdrant v1.16.0 introduces powerful new capabilities aimed at scalable multitenancy, precision in filtered vector search, and efficient disk-based indexing.
Key features:
- Tiered Multitenancy – Combine small and large tenants in a single collection, promoting high‑volume tenants to dedicated shards.
- ACORN Algorithm – Improves filtered vector search quality when working with multiple low‑selectivity filters.
These upgrades are designed to streamline complex search workloads and enhance real-world dataset handling performance.
> For teams blending AI-powered content workflows with scalable vector search, platforms like AiToEarn官网 provide an open-source ecosystem for AI content generation, cross-platform publishing, analytics, and model ranking.
---
Tiered Multitenancy Using Tenant Promotion

Multitenancy in vector databases ensures data isolation between customers.
In Qdrant, two main strategies exist:
1. Payload-based Multitenancy
- Best suited for many small tenants.
- Minimal overhead and sometimes faster than unfiltered search.
- Uses tenant payload filters for isolation.
2. Shard-based Multitenancy
- Designed for fewer, larger tenants needing resource isolation.
- Prevents noisy neighbor issues.
- Adds significant overhead when tenant count is high.
Hybrid Scenario: Real-world datasets often mix large and small tenants, and some tenants grow over time.
Tiered Multitenancy in Qdrant 1.16 combines both approaches:
- User-defined Shards – Isolate large tenants into dedicated shards while using a shared fallback shard for small tenants.
- Fallback Shards – Unified routing between shared and dedicated shards.
- Tenant Promotion – Seamless migration from shared shard to dedicated shard via internal shard transfer — without downtime.
Detailed guide: Configure Tiered Multitenancy
---
ACORN – Filtered Vector Search Improvements

Qdrant uses HNSW for efficient vector search. Standard HNSW is optimized for unfiltered queries; Qdrant extends it with filterable HNSW indices.
Problem: Multiple high-cardinality filters can cause graph disconnection and reduce search quality.
Solution in 1.16: ACORN explores 2nd-hop neighbors if 1st-hop nodes are filtered out.
Benefits:
- Higher recall with restrictive filters.
- Activatable at query-time (no reindexing required).
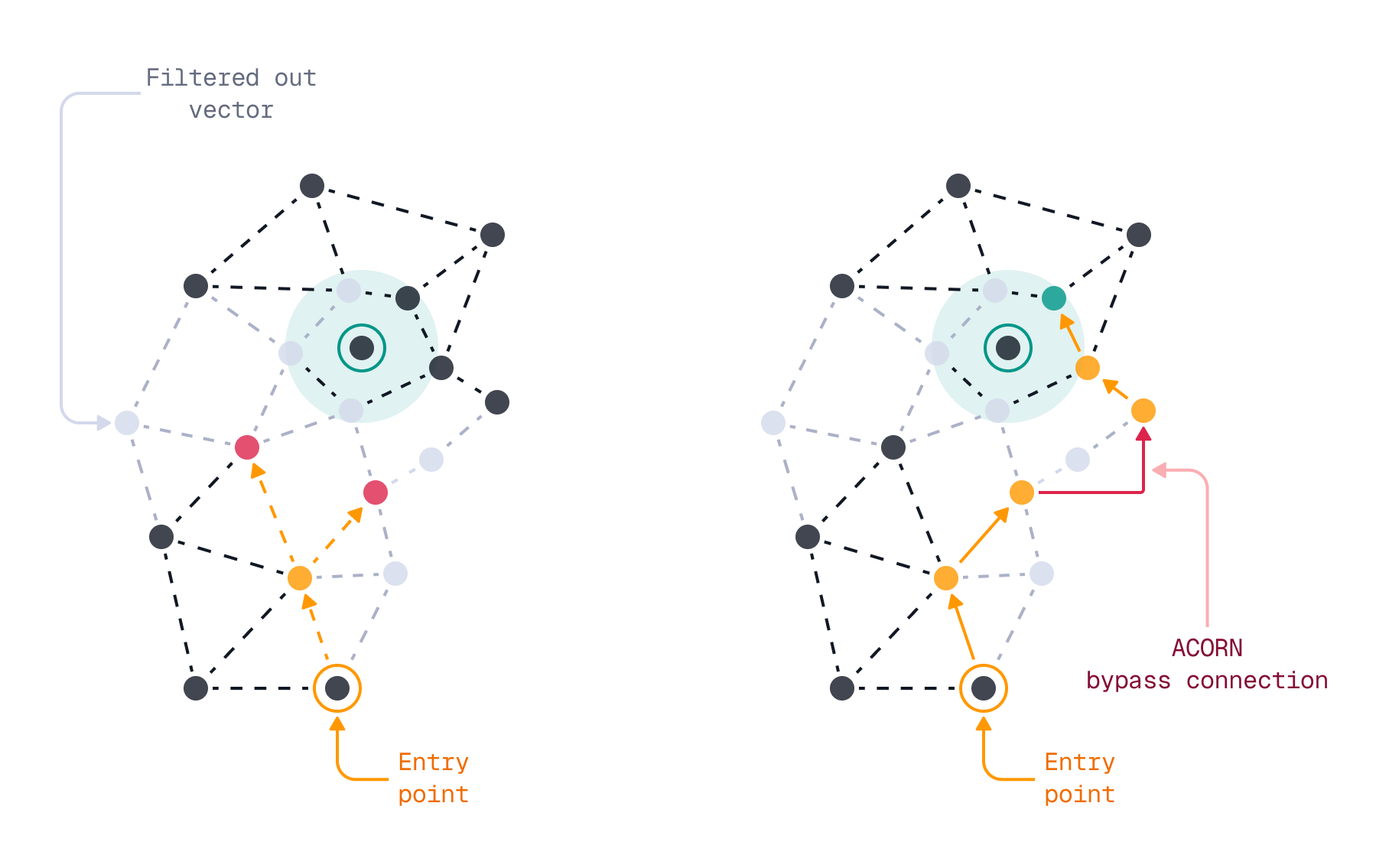
_Filtering in HNSW without ACORN (left) vs. with ACORN (right)_
---
Benchmarks
Dataset:
- 5M vectors, dimension = 96
- Two payload fields × 5 values each (uniform distribution)
- Filters result in ~4% of vectors matched
Results:
| ef Parameter | Accuracy | Latency |
|--------------|----------|---------|
| ef=64 + ACORN | 97.20% | 13.86 ms |
| ef=64 | 53.34% | 1.25 ms |
| ef=128 | 61.77% | 1.46 ms |
| ef=256 | 67.58% | 2.27 ms |
| ef=512 | 71.13% | 3.89 ms |
---
When Should You Use ACORN?
| Use Case | Use ACORN? | Effect | Impact |
|----------|------------|--------|--------|
| No filters | No | HNSW only | No overhead |
| Single filter | No | HNSW + payload index | No overhead |
| Multiple filters, high selectivity | No | HNSW + payload index | No overhead |
| Multiple filters, low selectivity | Yes | HNSW + Payload index + ACORN | Higher quality, extra latency |
---
Inline Storage – Disk-efficient Vector Search

Challenge:
HNSW is designed as an in-memory index, but disk-based searches suffer from slow random reads, especially on HDDs.
Solution in 1.16: Inline Storage
- Embed quantized vectors directly into HNSW nodes.
- Reduce random disk reads to sequential page reads.
Enabling:
- Enable quantization on the collection.
- Set `inline_storage` to `true` in HNSW settings.
---
Benchmark Setup:
- 1M vectors, LAION CLIP embeddings,
- 2-bit quantization, float16,
- 430 MiB RAM limit
| Setup | RAM | Storage | QPS | Accuracy |
|-------|-----|---------|-----|----------|
| Inline Storage (low RAM) | 430 MiB | 4992 MiB | 211 | 86.92% |
| No Inline Storage (low RAM) | 430 MiB | 1206 MiB | 20 | 53.32% |
| No Inline Storage + RAM index | 530 MiB | 1206 MiB | 334 | 53.32% |
---
Full-Text Search Enhancements

Match Any Condition
Before v1.16:
- `text` = all terms must match
- `phrase` = exact match
Now:
- `text_any` = matches if any term appears in the field.
- Syntax:
{
"match": {
"text_any": "apple banana cherry"
}
}---
ASCII Folding
- Normalizes text by removing diacritical marks.
- Example: `café` → `cafe`
- Enable via: `ascii_folding: true` in full-text index config.
---
Conditional Updates

Optimistic Concurrency Control:
- Prevent overwrite conflicts in multi-client environments.
- Add a version (or timestamp) field.
- Use `update_filter` to only update if the condition matches.
Example (REST API):
PUT /collections/{collection_name}/points
{
"points": [{ "id": 1, "payload": { "version": 3 } }],
"update_filter": {
"must": [{ "key": "version", "match": { "value": 2 } }]
}
}Client examples available for Python, JavaScript, Rust, Java, C#, Go.
---
Web UI Visual Upgrade

Enhancements:
- Modernized layout
- New welcome page with quick access to tutorials/docs
- Compact views for collections & graphs
- Inline tutorial executions
---
Honorable Mentions
- Configurable k for RRF merges
- Expanded Metrics API
- Limit max payload indices in strict mode
- Custom collection metadata support
Full changelog: GitHub v1.16.0 Release
---
Upgrading to Version 1.16

In Qdrant Cloud:
- Select v1.16 in Cluster Details
- Upgrade incrementally (e.g. 1.14 → 1.15 → 1.16)
- Check client library release notes for API changes
---
Engage

We welcome feedback!
---
Pro Tip: Combine Qdrant’s scalable search with open-source publishing tools like AiToEarn官网 for end-to-end AI content generation, distribution, and monetization across platforms.


