# RND1: The Largest Open-Source Diffusion Language Model
**Date:** 2025-10-12 · **Location:** Beijing

---
## Introduction
Diffusion Language Models (DLMs) have fascinated researchers because—unlike **autoregressive (AR) models**, which must generate text left-to-right—**DLMs enable parallel generation**.
**Advantages:**
- Potential for **faster outputs**
- Incorporation of both preceding and following context during generation
**Challenges:**
- Lower scaling efficiency compared to AR models
- Direct DLM training often requires **more iterations** to match AR performance
- AR models benefit from a **first‑mover advantage** including robust training infrastructure, refined recipes, and deep practitioner expertise
---
## Radical Numerics’ Approach

Startup **Radical Numerics** took a different route:
### **Autoregressive-to-Diffusion (A2D) Conversion**
They adapted an existing high-performing AR model into a DLM.
**Release:**
- **RND1-Base** (Radical Numerics Diffusion)
- **Largest** open-source diffusion language model so far
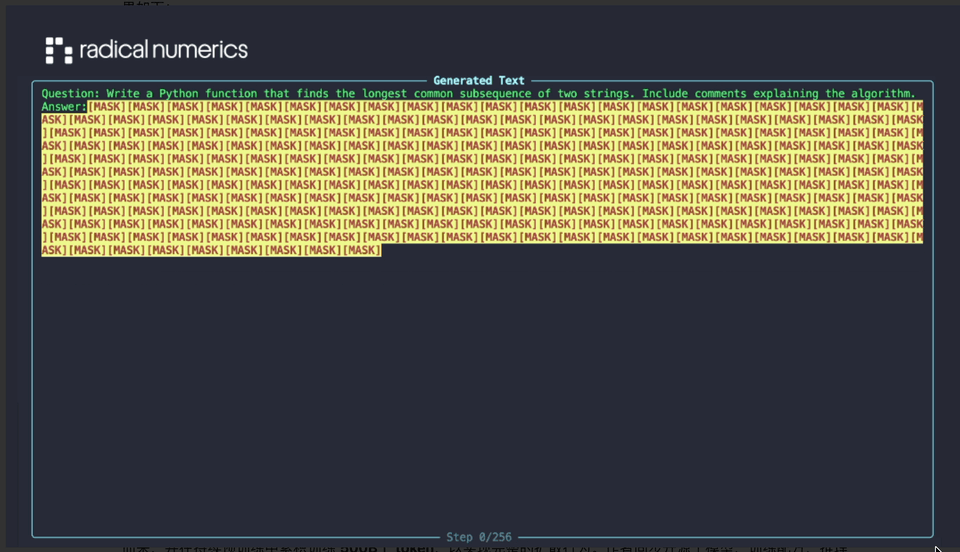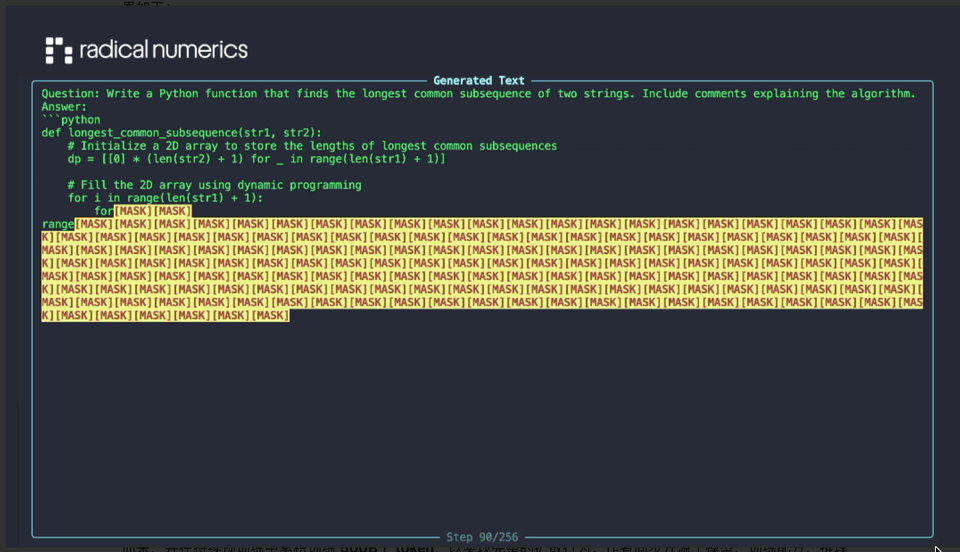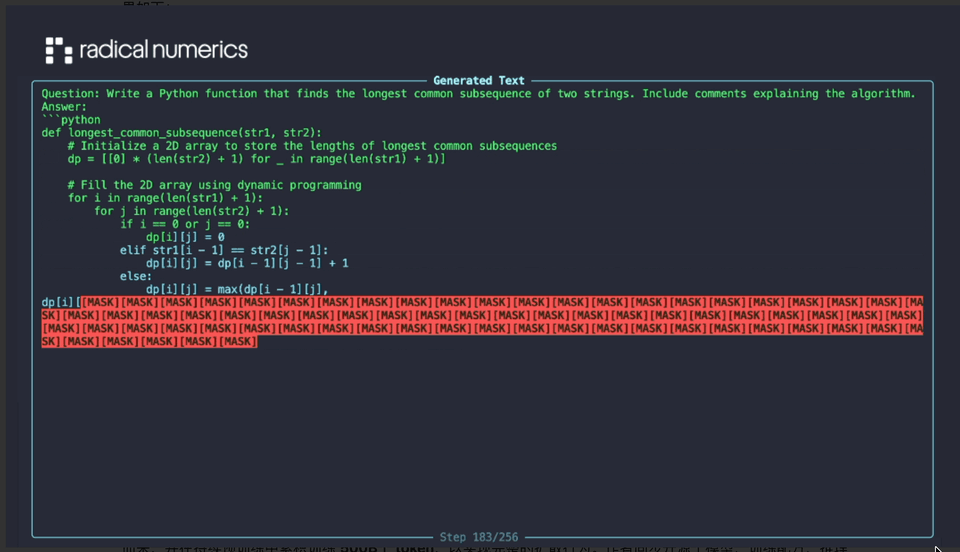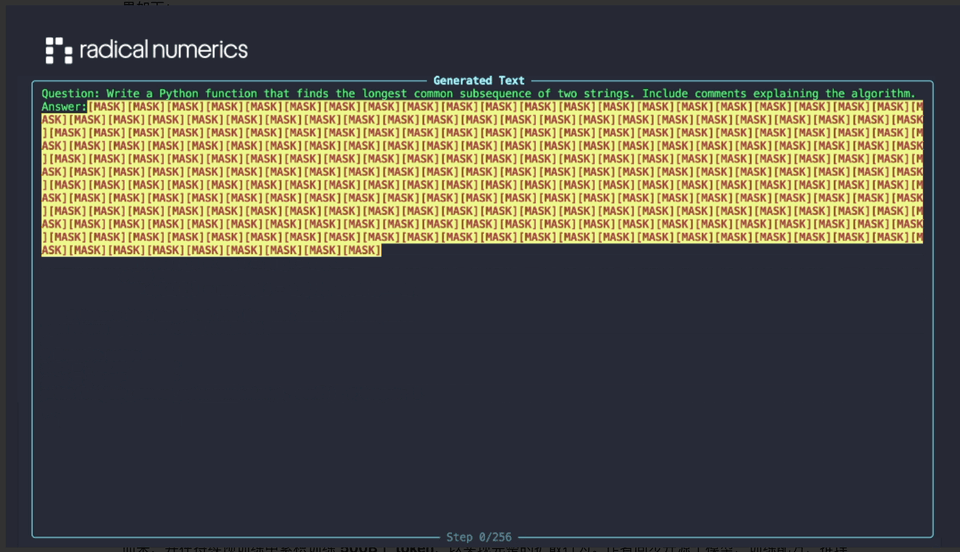
**Model Details:**
- **30B-parameter sparse MoE**
- **3B active parameters**
- Converted from **Qwen3-30BA3B**
- Continuous pretraining on **500B tokens** for full diffusion capabilities
- Open release: model weights, training recipes, inference code, and sample outputs

### **Resources**
- **Technical report:** *Training Diffusion Language Models at Scale using Autoregressive Models*
[Download PDF](https://www.radicalnumerics.ai/assets/rnd1_report.pdf)
- **Code repository:** [GitHub Link](https://github.com/RadicalNumerics/RND1)
- **HuggingFace model:** [HF Link](https://huggingface.co/radicalnumerics/RND1-Base-0910)
---
## Main Contributions
- **Systematic study** of large-scale A2D conversion: initialization strategies, hierarchical learning rates, critical batch sizes
- **Scalability & stability** gains by combining AR pretraining with diffusion-specific techniques
- Released **RND1-30B**, proving very large foundational DLMs are viable and competitive
---
## Benchmark Performance
**Benchmarks Tested:**
- **Reasoning & QA:** MMLU, ARC-C, RACE, BBH
- **STEM tasks:** GSM8K
- **Code generation:** MBPP
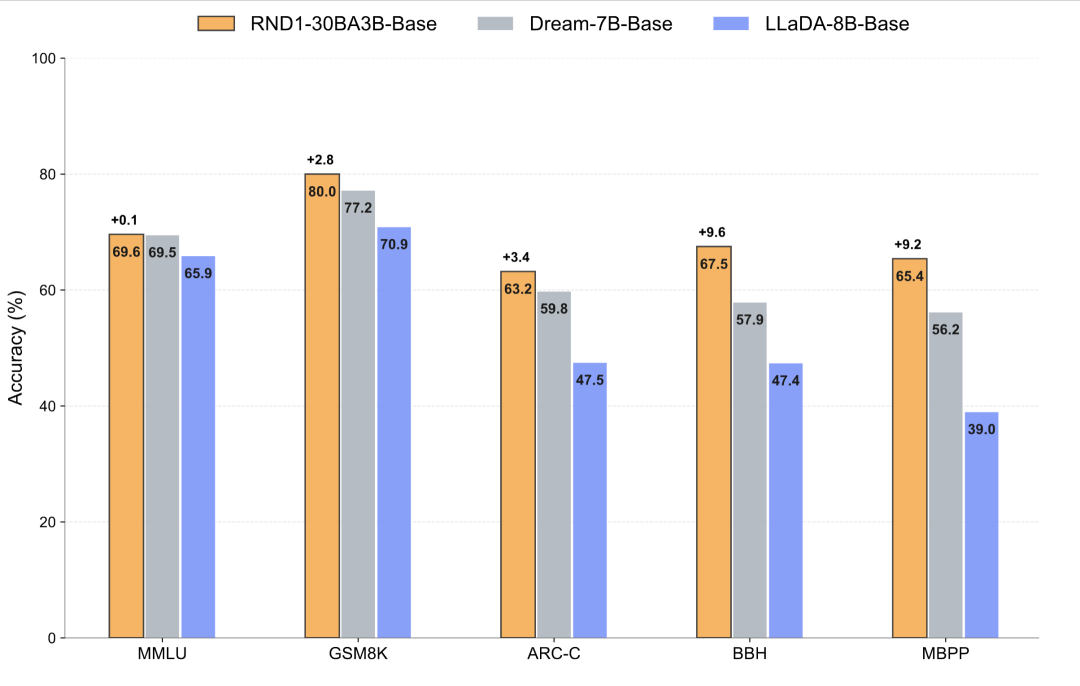
**Findings:**
- RND1 **outperforms** competing models like **Dream-7B** and **LLaDA-8B**
- Retains strong capabilities from its AR predecessor
- **Note:** No direct comparison with **LLaDA-MoE-7B-A1B**; head-to-head performance remains unclear
_Source: [arXiv 2509.24389](https://arxiv.org/pdf/2509.24389)_
---
## Simple Continuous Pretraining (SCP)
When converting from AR to diffusion:
1. **Enable bidirectional context** in a causal-only architecture
2. **Preserve** AR-trained language knowledge
### Complex Past Approaches:
- **Attention mask annealing**
- **Grafting new attention blocks**
Often hard to scale to large models
### SCP Method:
A simpler recipe with competitive results:
1. Start from a strong **AR checkpoint**
2. Replace **causal mask → bidirectional mask** at init
3. Continue pretraining under **masked diffusion objective** with LR warmup
---
## Preserving AR Knowledge via Layer-Wise Learning Rates
**Goal:** Prevent **catastrophic forgetting**
**Insights:**
- Factual knowledge often resides in **FFN/MLP layers**
- **Strategy:**
- Higher LR in **attention layers** (adapt faster to bidirectional context)
- Lower LR in **MLP & embedding layers** (preserve learned knowledge)
---
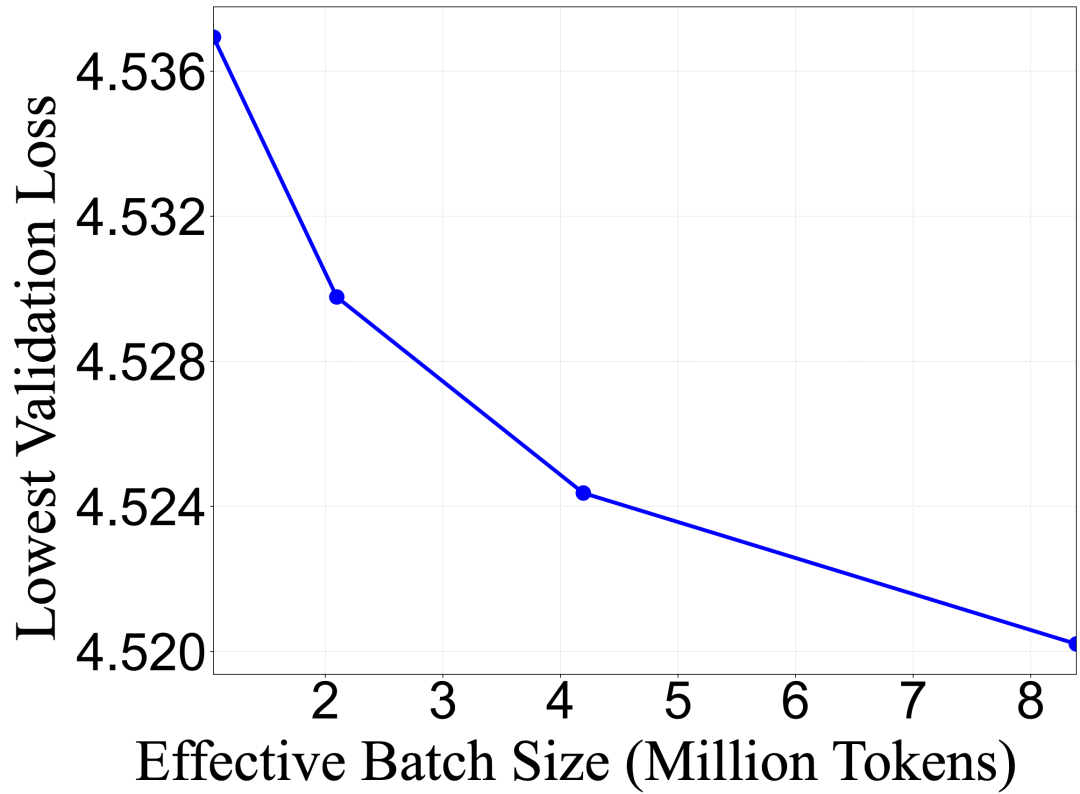
## Benefits of Larger Batch Sizes in A2D
**Key Observation:**
- AR loss: every token contributes
- Diffusion loss: only masked tokens (~50%)
**Impact:**
- Diffusion training needs **larger batches** for effective learning
**Experiment:**
- Used a 4B-parameter model
- Ran 4 branches with varying batch sizes
- Found **loss improvement persists up to ~8M tokens/batch**
---
## Why Retrofit AR Models?
**Advantages:**
- Avoid starting from scratch
- Harness robust AR pretraining infrastructure
- Explore **new architectures** more efficiently
---
## Ecosystem for AI Creators: AiToEarn
In parallel to research, creators can benefit from publishing and monetizing outputs globally.
**AiToEarn官网** ([visit here](https://aitoearn.ai/)) offers:
- Open-source platform
- AI-assisted content creation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Instagram, YouTube, X/Twitter, etc.)
- Analytics and monetization tools
Fits well for sharing **diffusion model outputs**, **benchmarks**, and creative applications.
---
## Radical Numerics’ Vision & Team

Core philosophy:
- **Automated AI research platform**
- Self-improving AI systems through **recursive optimization**
- Faster experimentation via automated loops
**Team Background:**
- From DeepMind, Meta, Liquid, Stanford
- Interests in **hybrid architectures**, **Hyena**, and **Evo**

**More Info:** [Read Blog](https://www.radicalnumerics.ai/blog/rnd1)

---
## Conclusion
**RND1** proves:
- Large-scale DLMs (>8B params) are practical
- A2D + SCP enables efficient, stable training
- High potential when paired with publishing/monetization infrastructures like **AiToEarn**
© **THE END**
[Read the original](2650994927)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=467c04ea&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2650994927%26idx%3D2%26sn%3Dabb637d57d22a7c5b334b8cad2cf4b85)




