RAG — Practical Chunking Strategies | Dewu Tech

Background
In Retrieval-Augmented Generation (RAG) systems, even highly capable LLMs with repeatedly tuned prompts can still produce missing context, incorrect facts, or incoherent merges of information.
While many teams keep switching retrieval algorithms and embedding models, improvements are often marginal.
The real bottleneck is often a seemingly small preprocessing step — document chunking.
Poor chunking can:
- Break semantic boundaries
- Scatter key clues
- Mix signals with noise
The result is retrieval returning “out of order” or incomplete fragments. Even strong models then struggle to produce accurate answers.
Quality chunking sets the performance ceiling for RAG: it determines whether the model receives coherent context or fragmented, unmergeable data.
A common mistake is to cut content purely by fixed length, ignoring the document’s structure:
- Definitions separated from explanations
- Table headers detached from data
- Step-by-step instructions chopped mid-flow
- Code blocks split away from their comments
High-quality chunking aligns with natural boundaries—titles, paragraphs, lists, tables, code blocks—while using moderate overlap for continuity and preserving metadata for traceability.
Good chunking improves both retrieval relevance and factual consistency more than swapping vector models or tweaking parameters.
> Note: This discussion focuses on embedding Chinese documents in practice.
---
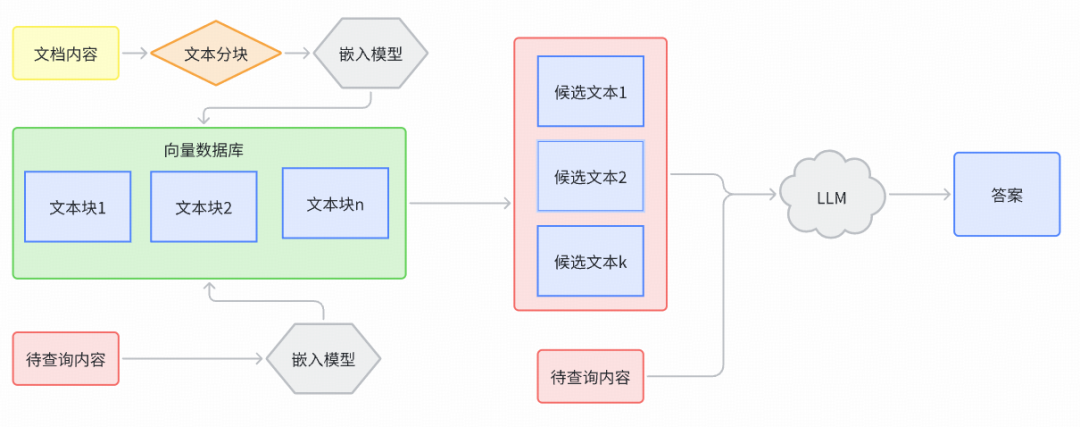
What is Chunking?
Chunking breaks large text blocks into smaller pieces to:
- Make embedding and retrieval more efficient
- Improve relevance and accuracy in vector database search
Benefits:
- Efficiency — Smaller segments are easier to process for embedding/retrieval.
- Better Query Matching — Chunks can match user intent more precisely, helping high-precision search and content generation.
Platforms like AiToEarn官网 show how effective chunking integrates into AI content generation → cross-platform publishing → monetization pipelines.
See AiToEarn文档 for open-source tools supporting chunking, analytics, and model ranking.
Key concepts:
- chunk_size — Size of each chunk
- chunk_overlap — Overlapping window between chunks

---
Why Apply Content Chunking?
- LLM Context Limits
- Split long documents so they fit LLM input limits
- Preserve semantic boundaries to avoid context loss or drift
- Retrieval Signal-to-Noise Ratio
- Large chunks = diluted relevance
- Small chunks = insufficient context
- Semantic Continuity
- Preserve cross-boundary clues with reasonable `chunk_overlap`
- Align boundaries with headings/sentence breaks
Ideal chunking balances:
- Context integrity (chunk_size)
- Semantic continuity (chunk_overlap)
---
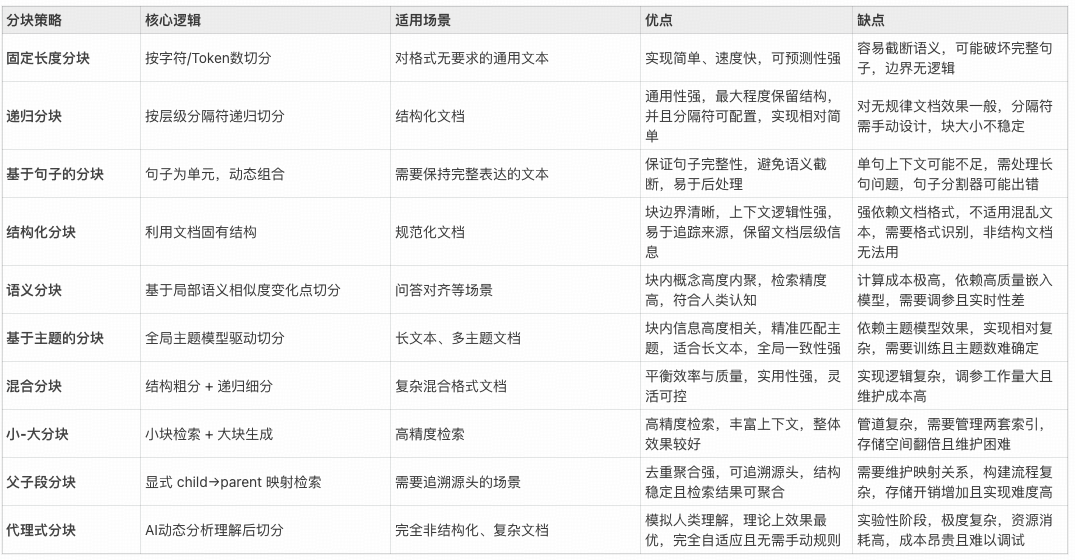
Chunking Strategies Overview
We cover:
- Fixed-length chunking
- Sentence-based chunking
- Recursive character chunking
- Structure-aware chunking
- Dialogue chunking
- Semantic & topic-based chunking
- Parent-child chunking
- Agent-based chunking
- Hybrid chunking
Each includes:
- Strategy
- Advantages / Disadvantages
- Applicable scenarios
- Parameter recommendations
- Example code for Chinese text
---
Fixed-Length Chunking
Strategy:
Split by fixed number of characters without considering structure.
Pros:
- Easiest to implement
- Fast
- Works with any text
Cons:
- Disrupts semantic flow
- Large chunks carry more noise, small chunks lack context
Params (Chinese corpus):
- `chunk_size`: 300–800 characters (~350/700 chars for 512/1024 tokens)
- `chunk_overlap`: 10–20% (avoid >30%)
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="", chunk_size=600, chunk_overlap=90
)
chunks = splitter.split_text(text)---
Sentence-Based Chunking
Strategy:
Split into sentences, then aggregate to desired chunk size.
Pros:
- Preserves sentence integrity
- Ideal for QA & citation
Cons:
- Chinese splitting needs custom handling
- May produce too-short chunks
For Chinese, use regex or libraries like:
- HanLP
- Stanza
- spaCy + pkuseg
import re
def split_sentences_zh(text: str):
pattern = re.compile(r'([^。!?;]*[。!?;]+|[^。!?;]+$)')
return [m.group(0).strip() for m in pattern.finditer(text) if m.group(0).strip()]Aggregation example:
def sentence_chunk(text: str, chunk_size=600, overlap=90):
sents = split_sentences_zh(text)
chunks, buf = [], ""
for s in sents:
if len(buf) + len(s) <= chunk_size:
buf += s
else:
if buf: chunks.append(buf)
buf = (buf[-overlap:] if overlap > 0 and len(buf) > overlap else "") + s
if buf: chunks.append(buf)
return chunks---
Recursive Character Chunking
Split by ordered separators (headings → newlines → spaces → characters).
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
separators=["\n#{1,6}\s", "\n\n", "\n", " ", ""],
chunk_size=700, chunk_overlap=100, is_separator_regex=True
)
chunks = splitter.split_text(text)Pros: Balanced semantic preservation & block size control
Cons: Needs correct separator config
---
Structure-Aware Chunking
Use headings, lists, code blocks, tables as boundaries.
Merge short blocks; split long blocks further.
Preserve metadata for traceability.
---
Dialogue Chunking
Split by conversation turns & speakers; use turn overlap not character overlap.
def chunk_dialogue(turns, max_turns=10, max_chars=900, overlap_turns=2):
...---
Semantic Chunking
Detect semantic shifts using sentence embeddings and similarity thresholds.
def semantic_chunk(...):
...Params:
- `window_size`: context window for novelty detection
- `min/max_chars`: control chunk length
- `lambda_std`: novelty threshold sensitivity
- `overlap_chars`: preserve continuity
---
Topic-Based Chunking
Use clustering (e.g., KMeans) on sentence embeddings; smooth topic labels; cut on stable topic changes.
---
Parent-Child Chunking
Index child chunks (sentences); recall them; aggregate by parent chunk to provide full context.
---
Agent-Based Chunking
Let an LLM agent decide chunk boundaries with explicit rules & constraints; validate output.
---
Hybrid Chunking
Combine coarse structural splitting with targeted fine-grained methods for overlong/mixed-format blocks.
---
Summary
Key points:
- Chunking is a major determinant of RAG accuracy.
- Align with natural document boundaries when possible.
- Use moderate overlaps to preserve context continuity without blowing up index size.
- Special-case handling for code, tables, dialogue, etc.
- Evaluate chunking strategies with Recall@k, nDCG, MRR, and faithfulness metrics—not just retrieval hit rate.
For multi-platform AI content workflows:
- Integrate chunking into the full pipeline — generate → chunk → embed → retrieve → publish
- Tools like AiToEarn make this seamless, connecting AI generation, intelligent chunking, analytics, and publishing to 10+ major platforms.
---
Scan to add WeChat assistant for more technical updates

Read original: 2247541482
---
For creators wanting AI-driven, multi-channel publishing + monetization, see: