Ray with TPU on GKE: A More Hardware-Optimized Experience
Scaling AI Workloads on TPUs with Ray
Engineering teams are increasingly using Ray to scale AI workloads across diverse hardware, including GPUs and Cloud TPUs.
While Ray provides a robust scaling framework, developers have traditionally needed to address the unique architectural and programming models of TPUs — including their distinct networking and Single Program Multiple Data (SPMD) style.
As part of our collaboration with Anyscale, we’re streamlining TPU adoption for Google Kubernetes Engine (GKE).
Our goal: make Ray-on-TPU as native, seamless, and low-friction as possible.
---
Key Enhancements
1. Ray TPU Library
Library: `ray.util.tpu`
Purpose: Improved TPU awareness and scaling within Ray Core.
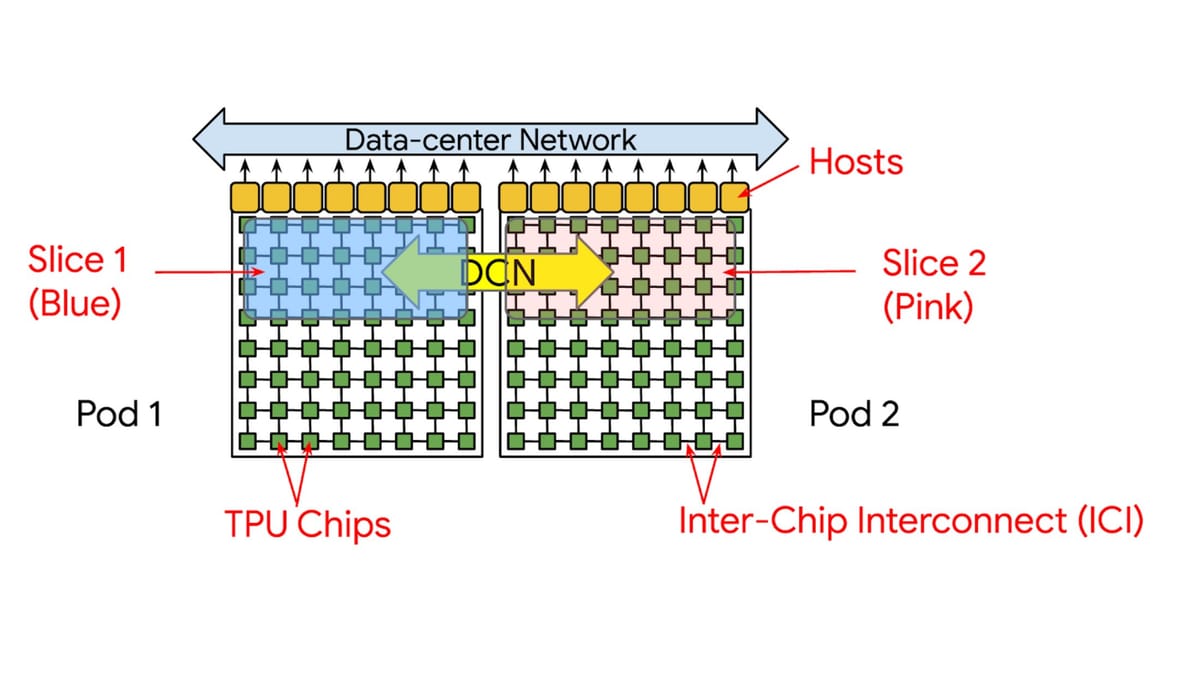
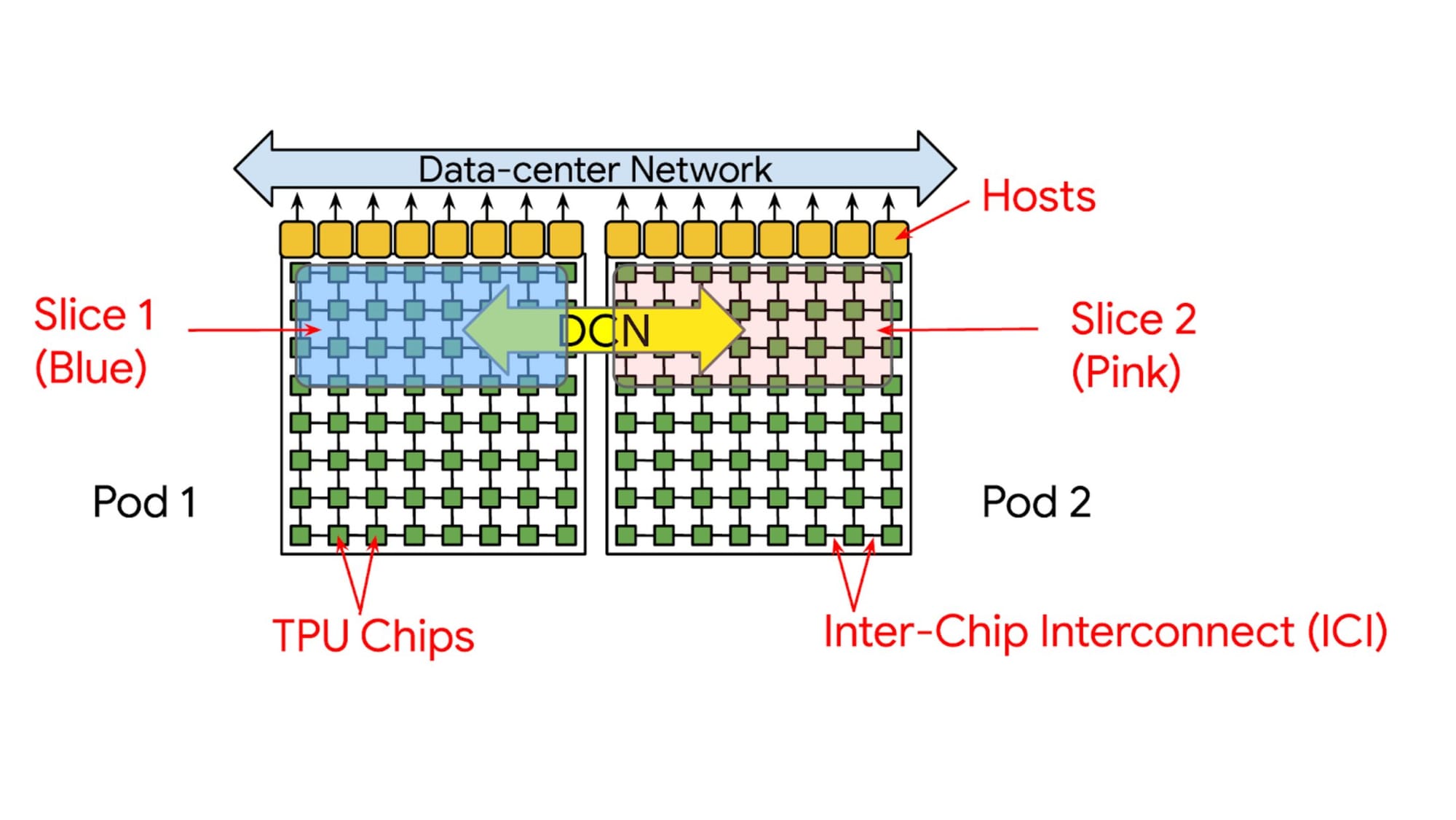
- TPUs run workloads on a slice — a set of interconnected chips via the Interchip Interconnect (ICI).
- Previously, configuring Ray to account for TPU topology was manual and error-prone.
- The new library automatically reserves a co-located TPU slice using SlicePlacementGroup and label_selector.
- Prevents fragmented resource allocation that significantly hinders performance.
Benefits:
- Ensures atomic slice allocation.
- Enables Multi-slice training — jobs spanning multiple TPU slices.
---
2. Expanded Support for JAX, Ray Train, and Ray Serve
Training Improvements
- Alpha support for JAX via JaxTrainer and PyTorch on TPUs.
- Automates distributed host initialization for multi-host TPU training.
- Simplifies hardware configuration with a concise `ScalingConfig`.
Inference Improvements
- Ray Serve now benefits from TPU enhancements for smoother deployment.
Example: Multi-Host TPU Training with JaxTrainer
import jax
import jax.numpy as jnp
import optax
import ray.train
from ray.train.v2.jax import JaxTrainer
from ray.train import ScalingConfig
def train_func():
...
scaling_config = ScalingConfig(
num_workers=4,
use_tpu=True,
topology="4x4",
accelerator_type="TPU-V6E",
placement_strategy="SPREAD"
)
trainer = JaxTrainer(
train_loop_per_worker=train_func,
scaling_config=scaling_config,
)
result = trainer.fit()
print(f"Training finished on TPU v6e 4x4 slice")Key Point: Guarantees co-located TPU resources, unlocking full ICI interconnect speed.
---
3. Label-Based Scheduling API
What It Does:
Integrates with GKE custom compute classes for hardware targeting and fallbacks without manual YAML edits.
Features:
- Specify TPU type via `label_selector` (e.g., `"TPU-V6E"`).
- Use fallback strategies for different cost/performance scenarios.
- Automatically reads TPU metadata from GKE and maps to Ray labels:
- `ray.io/accelerator-type` → TPU generation
- `ray.io/tpu-topology` → chip topology
- `ray.io/tpu-worker-id` → worker rank
Example: TPU Targeting with Fallback
@ray.remote(num_cpu=1,
label_selector={
"ray.io/tpu-pod-type": "v6e-32",
"gke-flex-start": "true",
},
fallback_strategy=[
{"label_selector": {
"ray.io/tpu-pod-type": "v5litepod-16",
"reservation-name": "v5e-reservation",
}}
]
)
def tpu_task():
...ComputeClass YAML Example
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: cost-optimized
spec:
priorities:
- flexStart:
enabled: true
tpu:
type: tpu-v6e-slice
count: 8
topology: 4x8---
4. Integrated TPU Metrics and Logs
You can now view:
- TensorCore utilization
- Duty cycle
- HBM usage
- Memory bandwidth utilization
Directly in the Ray Dashboard, alongside `libtpu` logs.
This accelerates debugging and performance tuning.
---
Get Started
- Read the Docs
- Use TPUs with Kuberay
- JAX Workloads
- Getting Started with JAX guide
- JaxTrain Documentation
- Monitor TPU Metrics
- View TPU metrics
- Request TPU Capacity
- DWS Flex Start for TPUs
---
Connecting TPU Training to AI Content Monetization
Platforms like AiToEarn官网 — an open-source global AI content monetization system — let creators:
- Generate AI-driven outputs.
- Publish simultaneously to Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
- Track engagement and model rankings via AI模型排名.
Synergy:
- Use Ray TPU for model training.
- Deploy outputs using AiToEarn for global reach and monetization.
Resources:
---
Further Reading
- Ray on GKE — New Features for AI Scheduling and Scaling
- Kubernetes advancements: label-based scheduling, Device Resource Assignment (DRA), and vertical pod resizing — ideal for distributed AI/ML workloads.
---
Bottom Line:
By combining Ray TPU enhancements with GKE scheduling and publishing ecosystems like AiToEarn, teams can:
- Scale AI workloads efficiently on TPUs.
- Prevent performance loss from topology fragmentation.
- Monitor TPU metrics in real-time.
- Monetize AI outputs globally.
---
Do you want me to add a visual architecture diagram showing the relationship between Ray, GKE, TPUs, and AiToEarn for end-to-end AI workflows? That could make this document even more intuitive for technical audiences.


