Reducing False Positives in RAG Semantic Caching: A Banking Case Study

Reducing False Positives in RAG with Semantic Caching: A Production Case Study

Author: Elakkiya Daivam
This article examines why Retrieval-Augmented Generation (RAG) and semantic caching are powerful for minimizing false positives in AI applications, based on a production-level evaluation of seven bi-encoder models against 1,000 query variations.

---
The Rise of Natural Language Interfaces
As natural language becomes the default medium for interacting with software—whether through intelligent search, chatbots, analytics assistants, or enterprise knowledge explorers—systems must process large volumes of queries that differ in wording but share the same intent.
Key requirements:
- Fast, accurate retrieval
- Reduced redundant LLM calls
- Consistency in responses
- Cost efficiency
---
Understanding Semantic Caching
Semantic caching stores queries and answers as vector embeddings, enabling reuse when new queries have similar meanings.
Compared to string-based caching, it operates on meaning and intent, bridging cases where phrasing changes but the user's need stays the same.
Benefits in production:
- Faster responses
- Stable output quality
- Lower compute costs
Risk: Poorly designed caching can produce false positives—semantically close but incorrect matches—undermining trust.
---
Initial Deployment Challenges
In a financial services FAQ deployment, we encountered:
- High-confidence wrong matches (e.g., account closure queries rerouted to payment cancellation).
- Extreme mismatch rates: Some models with a 0.7 similarity threshold showed up to 99% false positives.
Lesson: A validated embedding model and threshold alone are not enough—cache design must be robust.
---
Experimental Methodology
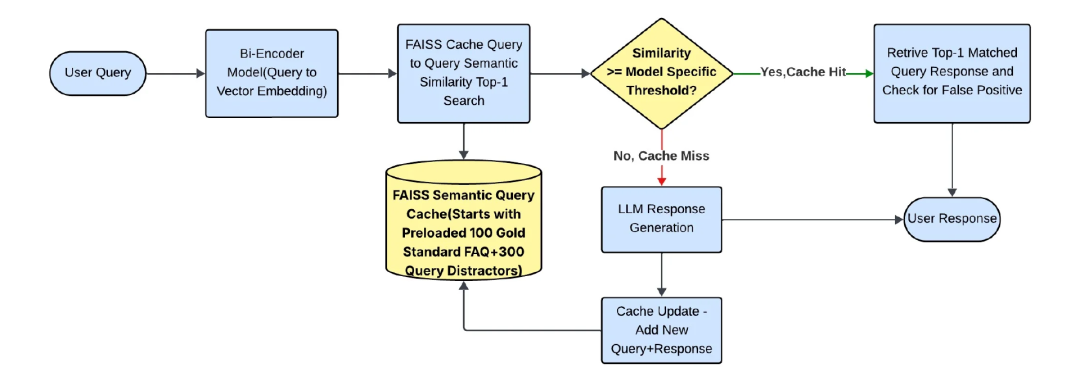
System Architecture
- Query-to-query semantic cache using FAISS.
- Workflow:
- Convert incoming queries to embeddings.
- Compare against cached embeddings.
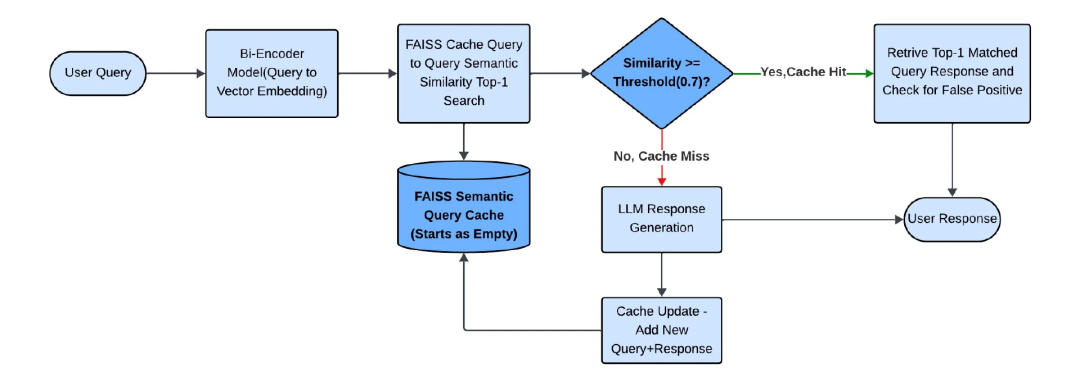
- Return gold-standard answer if similarity ≥ threshold; otherwise, query LLM and store result.
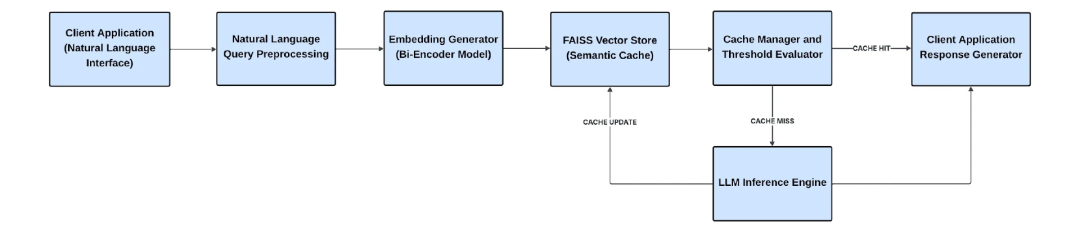
Figure 1: High-Level Semantic Cache Architecture
Cache Modes
- Incremental Mode: Empty cache at start; grow on misses.
- Pre-Cache Mode: Start preloaded with 100 gold answers + 300 crafted distractors.
Infrastructure
- AWS g4dn.xlarge (NVIDIA T4 GPU, 16GB memory)
- 1,000 query variations tested
- Models: all-MiniLM-L6-v2, e5-large-v2, mxbai-embed-large-v1, bge-m3, Qwen3-Embedding-0.6B, jina-embeddings-v2-base-en, instructor-large
- Dataset: 100 banking FAQs
- Validation accuracy: 99.7%
- Metrics: Cache hit %, LLM hit %, FP %, Recall@1, Recall@3, latency
---
Dataset Design
Real-world banking queries from 10 domains (payments, loans, disputes, accounts, investments, ATMs, etc.).
Each FAQ → 10 variations + 3 distractor types:
- topical_neighbor: 0.8–0.9 similarity
- semantic_near_miss: 0.85–0.95 similarity
- cross_domain: 0.6–0.8 similarity
Purpose: Test semantic precision under realistic conditions.
---
Model Selection Considerations
Example FAQ:
"How do I cancel a Zelle payment?"
Core Intent
- Cancel if recipient not enrolled
- Instant transactions are irreversible
- Unenrolled transactions cancelable via app or support
Query Variation Coverage
- Formal, casual, typos, slang, urgency, vague phrasing
Distractor Handling
- Same domain, different actions (view history)
- Similar mechanism, different service (wire transfer reversal)
- Different payment system entirely (credit card dispute)
Recommended Retrieval Strategy
- Hybrid matching: Dense embeddings → top candidates → LLM re-ranking
- Preprocessing: Spell correction, slang normalization
- Action/domain filters to ensure intent match
---
Experiment Results
Experiment 1: Zero-Shot Baseline
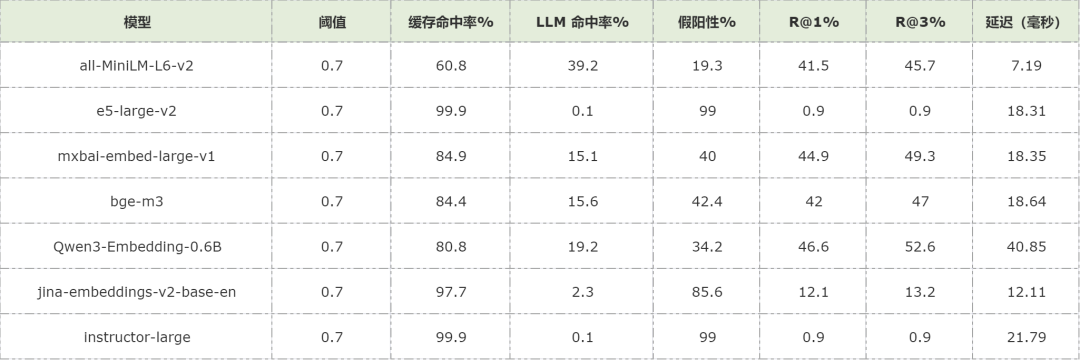
Findings:
- Default threshold (0.7) → extremely high FP rates (up to 99%).
- Domain context absence = inaccurate matches.
---
Experiment 2: Similarity Threshold Optimization
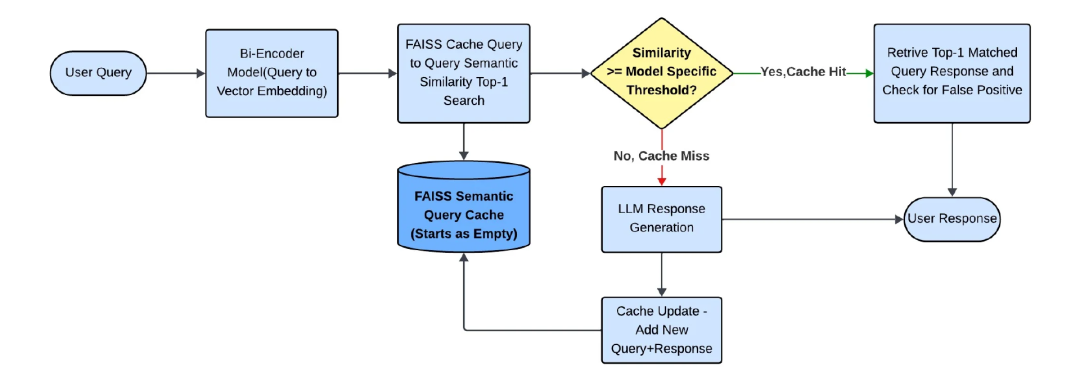
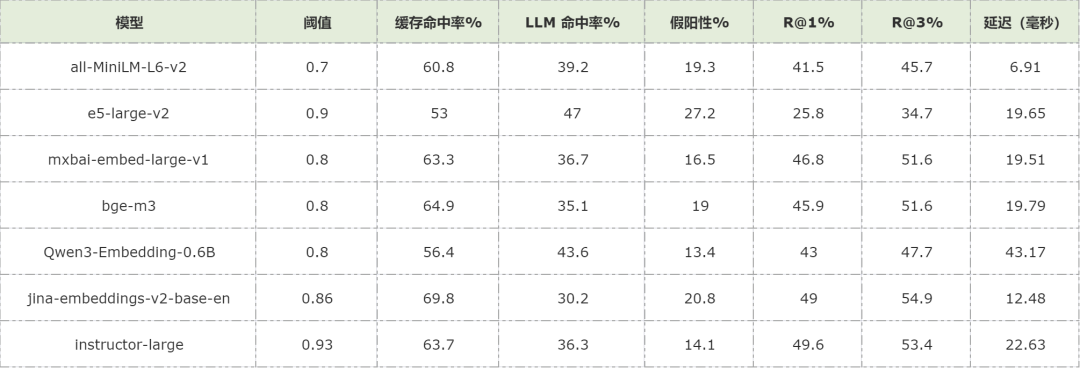
Outcome:
- Threshold tuning helped but did not eliminate high FP rates.
- Lower FPs came at the expense of higher cache misses → more costly LLM calls.
---
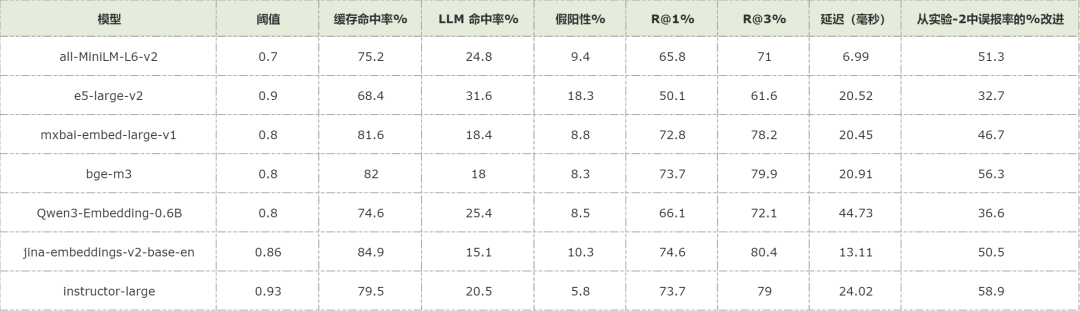
Experiment 3: Optimal Candidate Principle
Key Insight:
Strong candidate availability matters more than search optimization.
Approach:
- Preload cache with 100 gold answers + 300 distractors
- Simulate real-world similarity boundaries
Improvement:
- FP rate ↓ 59%
- Cache hit rate ↑ to 68.4%–84.9%
---
Experiment 4: Cache Quality Control
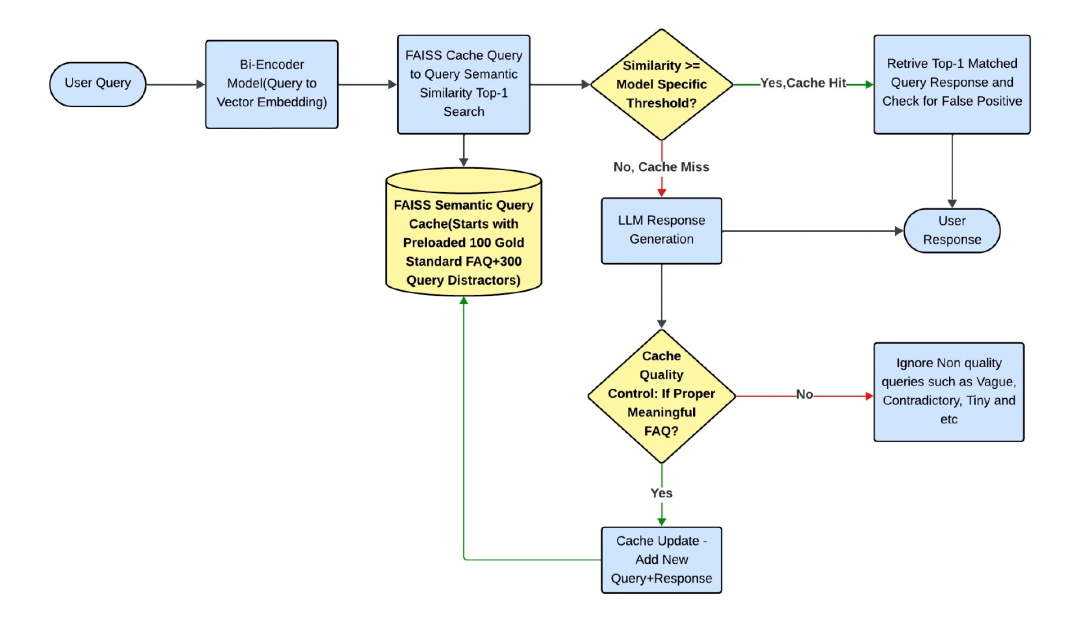
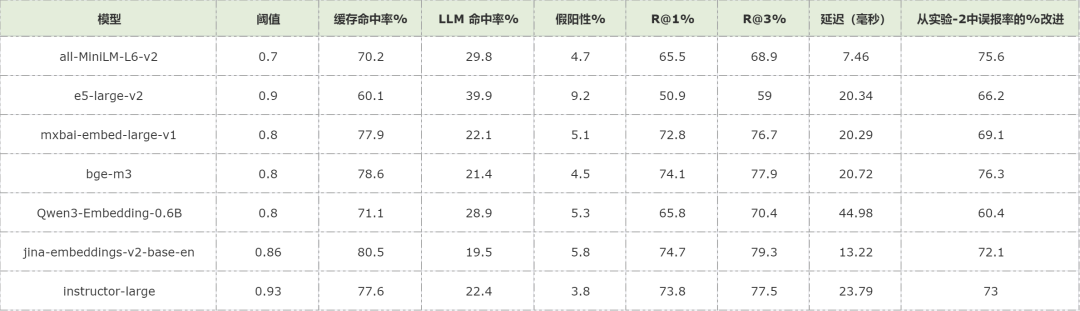
Strategy:
- Filter ambiguous, typo-heavy, or vague queries before caching
Result:
- FP rates < 6% for all but one model
- Best performer: Large teacher model → 3.8% FP (96.2% reduction)
---
Conclusion
From 99% to 3.8% false positives — the transformation required:
- Architectural redesign (Optimal Candidate Principle)
- Cache quality safeguards
- Domain-aware preloading
Preferred models:
- Best accuracy: Large teacher model
- Balanced: bge-m3
- Low latency: all-MiniLM-L6-v2
- Avoid: e5-large-v2 (high FP persistency)
---
Roadmap for <2% False Positives
Multi-Layer Improvements
- Advanced preprocessing (typo/slang normalization)
- Domain-specific fine-tuning
- Multi-vector representation (content, intent, context)
- Cross-encoder re-ranking
- Rule-based domain validation layer
---
Lessons for Any RAG System
- Cache design > threshold tuning
- Preprocessing is mandatory to avoid polluting the cache
- Pure similarity-based matching struggles with fine-grained intent differences
---
Final Thought
Fix the cache first. Then tune models. Architectural principles—not bigger embeddings—turn prototypes into production systems.
Original article:
https://www.infoq.com/articles/reducing-false-positives-retrieval-augmented-generation/
---
Platforms like AiToEarn (官网, 博客, 开源) extend these ideas by combining AI generation, multi-platform publishing, analytics, and model ranking—ensuring not just accurate retrieval but also scalable content monetization across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).


