Refactoring a Class Saved 2.9GB of JVM Memory
1. Optimization Results
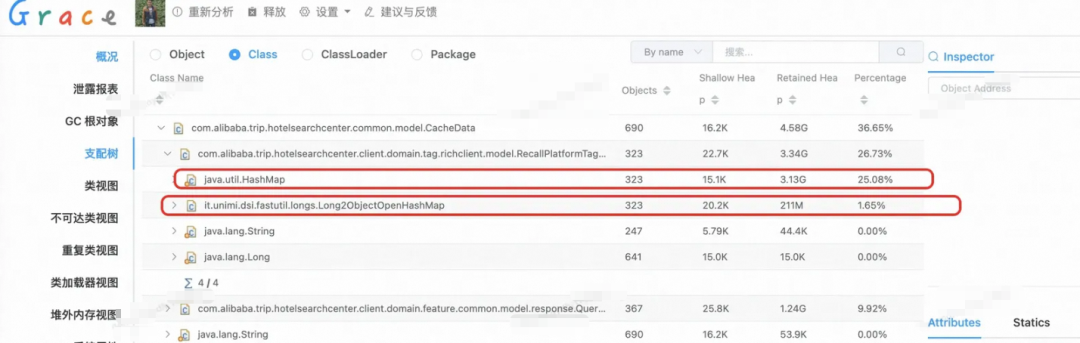
By refactoring just one class, JVM heap memory usage dropped by 2994 MB (~3 GB) — from 3205 MB down to 211 MB.
The new structure consumes only 6.5% of the memory used by the old one.
This result was verified in production, not from stress‑test simulations:
- Dual-write release strategy: old & new structures wrote in parallel while tracking real-time memory usage.
- Post-verification switchover: new structure fully replaced the old, which was retired.
Such a dramatic gain came from rethinking one core class.
You might ask: "How can touching a single class save 3 GB?"
The answer: generic containers — `HashMap`, `HashSet`, auto‑boxing, object headers, and hidden overheads — which work fine at small scale but become silent memory hogs at massive scale.
This write‑up details the entire optimization process — from thought process to technical decisions, production comparisons, and implementation.
---
2. Background
A core API filters product tags at a city dimension — logic is complex:
- Multiple conditions with nested AND/OR.
- Multi‑level tree expressions.
- Context‑dependent rules that must run at request time.
Because this cannot be handled efficiently with built‑in search operators or scripting, we load all product‑tag data in memory and filter in the application layer.
Design at the time:
- `cityID` → set of product tags.
- Local 3‑minute TTL cache for reuse between requests.
⚠️ Without caching, each request would rebuild the structure, creating huge memory peaks.
---
Original Object Design
public class RecallPlatformTagsResp extends BasePageResponse {
private static final long serialVersionUID = 8030307250681300454L;
// key: product ID, value: set of tag strings for product
private Map> resultMap;
}Sample:
[
{1: ["2246", "2288", "3388", "1022"]},
{2: ["12246", "12288"]}
]---
Observation:
All tags are positive integers <5000 — a dense small‑integer domain.
Yet tags were stored as String (e.g., `"12345"`), trading memory efficiency for future flexibility.
Impact:
A single `BasePageResponse` could consume 3.13 GB in a high‑concurrency cache.
---
3. Data Analysis & Optimization Potential
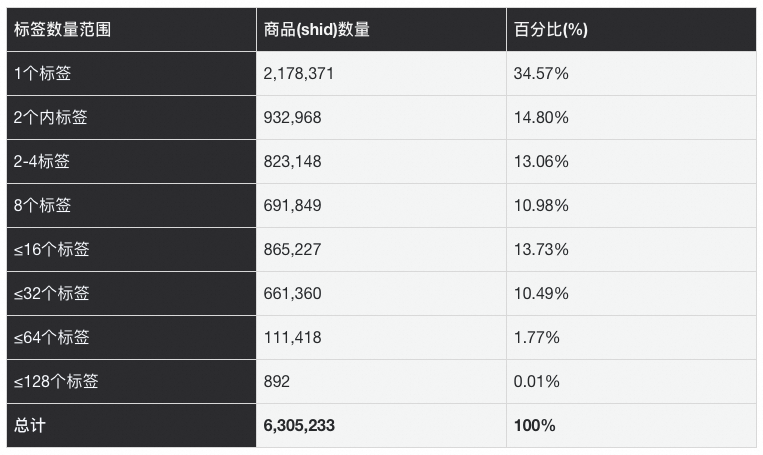
We analysed a sample of ~1M products.
Metric: products with k tags:
- 80% ≤ 16 tags
- 90% ≤ 32 tags
- 99% ≤ 64 tags
- Max < 128 tags
Implications:
- Highly right‑skewed; no heavy long tail.
- Clear upper bound: 128 tags/product.
Design Direction:
- No need for dynamically expandable sets — arrays suffice.
- Data is immutable → sort + binary search viable for lookups.
- Integers → `int[]` preferred over `String` + `HashSet`.
---
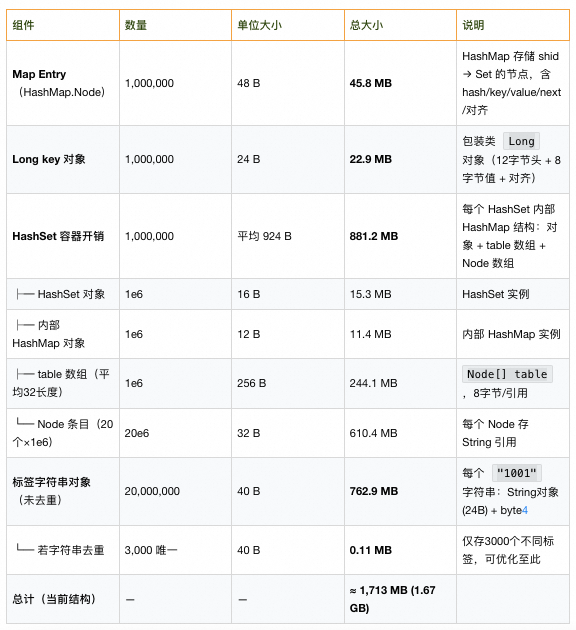
String deduplication via interning could help, but the old structure did not utilize it.
---
4. Candidate Designs & Choice
Problem:
At scale, `HashMap` & `HashSet` become hidden GB‑level memory drains.
Alternatives tested:
- `Long2ObjectOpenHashMap` (FastUtil) → avoid boxing.
- `int[]` with binary search → avoid `HashSet` overhead.
- `RoaringBitmap` for integer IDs.
- Custom object pools.
---
After comparing memory footprint, lookup speed, init cost, and complexity:
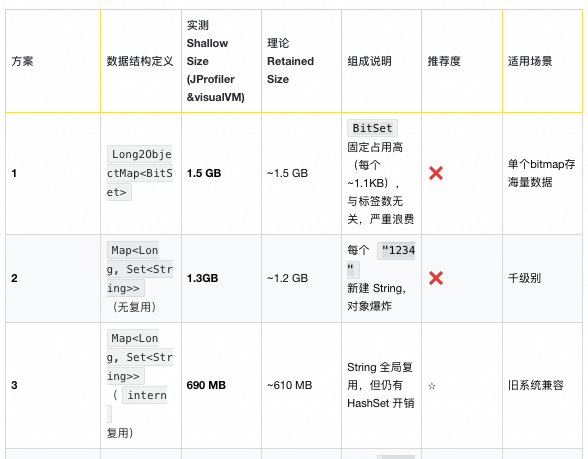
Final choice:
`Long2ObjectOpenHashMap` — FastUtil primitive map + plain int arrays.
---
Test Results:
- Change value type only → 1.3 GB → 64 MB.
- Also change key map → 25 MB.
---
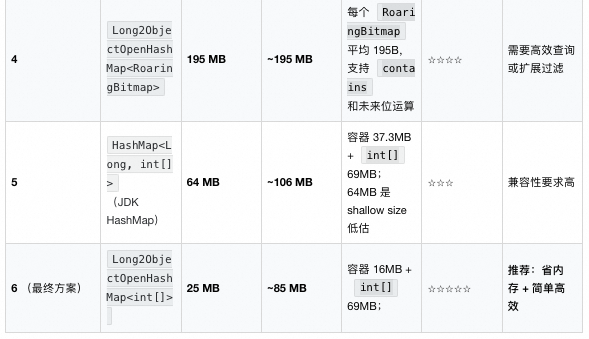
5. Why `int[]` Beats `HashSet`
Original reasons for `HashSet`:
- Deduplication → already ensured upstream.
- O(1) `contains()` → but with high memory overhead.
`int[]` + binary search:
- Stable O(log k) (max 7 comparisons @ k=128).
- Minimal space overhead.
- Cache‑friendly, contiguous layout.
90% of lookups need ≤ 5–6 comparisons — effectively O(1) with 94%+ memory savings.
---
JProfiler Test
Code (abridged) uses:
- `Map>`
- `int[]`
- FastUtil primitive map
- `BitSet`
- `RoaringBitmap`
---
6. Final Optimized Class
public class RecallPlatformTagsResp extends BasePageResponse {
private static final long serialVersionUID = 8030307250681300454L;
// Old structure kept for phase comparison
private Map> resultMap;
// New structure: primitive long key, int array tags
private Long2ObjectOpenHashMap itemTags = new Long2ObjectOpenHashMap<>(1_600_000);
}---
7. Long2ObjectOpenHashMap Deep Dive
Reliability
- Mature, maintained FastUtil project.
- Widely used in Apache Spark, Elasticsearch, Neo4j, etc.
- Pure Java, no dependencies.
Key Advantages
- No boxing for `long` keys.
- Open addressing for collisions — better cache locality.
- Compact arrays for storage.
---
Core Layout:
long[] key;
Object[] value;- Index: `(hash(key) ^ (key >>> 32)) & mask`
- Mask: `capacity-1` when capacity=power of two.
---
Collision Handling:
Linear probing → next slot search until empty.
Deletion:
- Uses backward shift to preserve probe chain.
---
Performance Caveat:
- Load factor >0.7 → sharp speed drop.
Collision Mitigation:
- Pre‑size capacity: `new Long2ObjectOpenHashMap<>(expectedSize)`
- Avoid clustered keys (e.g., all multiples of capacity divisor).
---
8. Usage Scenarios
✅ Best for:
- High‑frequency long→object lookups.
- Memory and GC sensitive environments.
❌ Avoid:
- Concurrent writes w/o external locking.
- Highly skewed key distributions.
---
9. Summary & Lessons
Refactored:
HashMap>
→ Long2ObjectOpenHashMapResult: ~94% memory reduction (3.13 GB → 200 MB).
Takeaways:
- Beware hidden overhead in nested generic collections.
- Optimize with actual data distribution statistics.
- Treat memory sensitivity as a design‑time principle.
---
In large-scale projects, combining such optimizations with modern tools can multiply impact — whether in backend data handling or in generating and distributing technical content efficiently.
Platforms like AiToEarn官网 illustrate this — offering AI‑powered content creation, multi‑platform publishing, analytics, and model ranking so engineering insights reach the right audiences across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).


