Revealing the Core Technology of Hunyuan OCR: Unified Framework & True End-to-End

Tencent HunyuanOCR Model — Official Release & Open Source
The Tencent Hunyuan Large Model team has officially released and open-sourced the HunyuanOCR model — a commercial-grade, lightweight (1B parameters) OCR-specific vision-language model built with an original ViT and a compact LLM architecture.

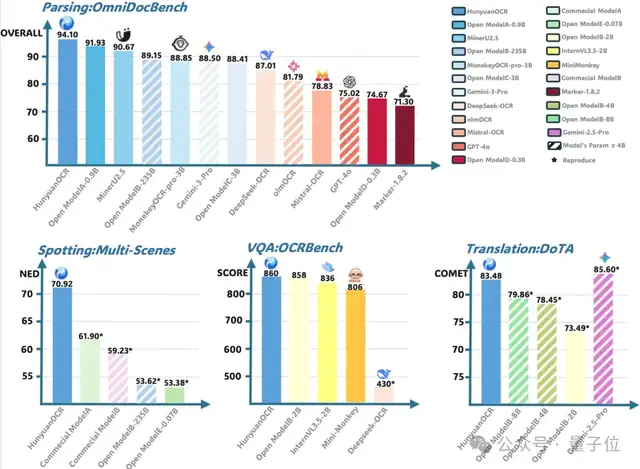
Performance Highlights
- Perception: Text detection & recognition, complex document parsing — outperforms all publicly available solutions.
- Semantic: Information extraction, text-image translation — industry-leading results.
- Achievements:
- 1st place in ICDAR 2025 DIMT Challenge (Small Model Track)
- SOTA score among sub-3B models on OCRBench
- Top 4 on Hugging Face trending
- 700+ GitHub stars
- Integrated into vLLM by day 0
---
Three Key Breakthroughs
- Unified Versatility & Efficiency
- Handles detection, recognition, parsing, info extraction, VQA, and translation in a lightweight framework — solving limits of traditional single-function expert models.
- Minimalist End-to-End Architecture
- No dependency on layout analysis or preprocessing — eliminates error accumulation, simplifies deployment.
- Data-Driven & RL Innovations
- Validates high-quality data value and shows reinforcement learning can boost multi-task OCR performance dramatically.
Weights Available On: Hugging Face | ModelScope
Deployment: High-performance vLLM-based scheme for research & industrial use.
---
Architecture Overview
HunyuanOCR adopts a pure end-to-end train-and-infer paradigm — every task completes in a single inference.
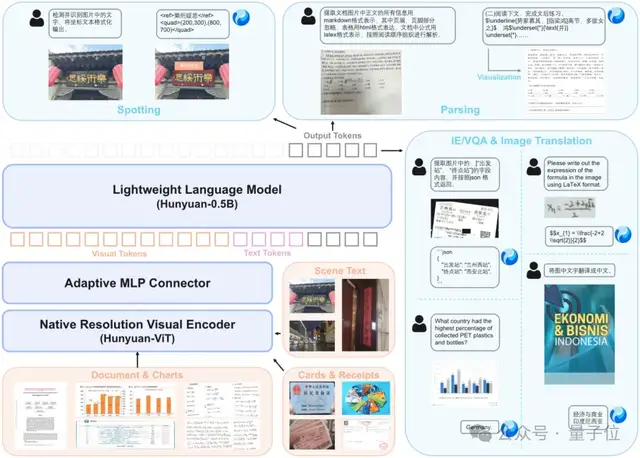
Components
- Vision Side: Based on SigLIP-v2-400M + Adaptive Patching — supports arbitrary input resolutions, avoids distortion for extreme layouts (e.g., long docs).
- Connector: Learnable pooling bridges vision & language — optimally compresses high-resolution features while preserving semantics.
- Language Side: Hunyuan-0.5B + XD-RoPE — decouples/aligned text (1D), layout (2D), spatiotemporal (3D) info for robust multi-layout reasoning.
Design Benefits:
- Eliminates multi-model cascades & heavy post-processing
- Maps images directly to text
- Robust in mixed-layout/document comprehension
- Stable under complex content scenarios
---
Multilingual & Multi-Scenario Data
To maximize performance across languages/layouts, Tencent built a 200M image-text pair corpus covering:
9 real-world scenarios:
Documents, street view, ads, handwriting, screenshots, tickets & IDs, game UIs, video frames, artistic fonts.
130+ languages supported.
Data sources: Public benchmarks, web-scraped real data, proprietary synthetic generation.

(Image shows pretraining data synthesis and simulation augmentation)
---
Data Synthesis & Simulation
SynthDog Framework Extensions
- Paragraph-level doc rendering in 130+ languages
- Bidirectional text (LTR/RTL) support
- Fine-grained font/color/layout control
- Handwriting style simulation
Warping Deformation Pipeline
- Simulates folding, perspective distortion
- Imaging degradations: blur, noise
- Complex lighting interference
Impact: Stronger robustness for text localization & document parsing in natural scenes.
---
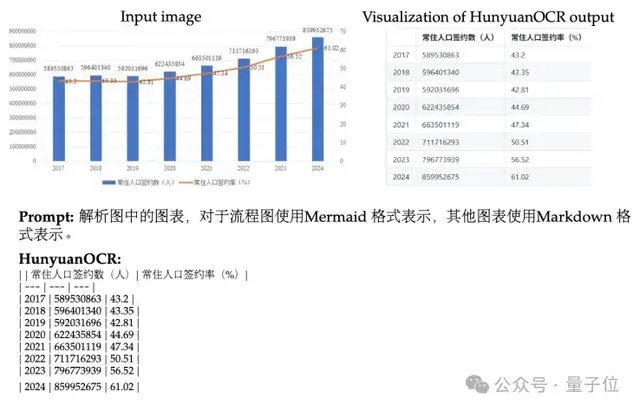
Semantic Understanding Pipeline
Process
- Mine hard cases (low clarity, complex charts)
- Generate diverse Q&A via high-performance VLMs
- Multi-model cross-validation for QA quality
“One Source, Multiple Uses”
Unified annotations enable:
- Text localization
- Structured parsing (Markdown/JSON)
- Multi-dimensional reasoning QA
Benefit: Solves high-quality data shortage for complex VLM tasks, improves efficiency.
---
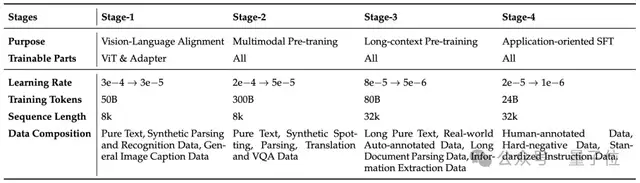
Four-Stage Pretraining Strategy
Stage 1 — Warm-up
- Freeze LLM, train ViT & MLP adapters
- Align vision and text features
- Strengthen perception & structural understanding
Stage 2 — End-to-End Learning
- Unfreeze all params
- Train on 300B tokens
- Enhance document/table/formula/chart comprehension
---
Stage 3 — Long-Window Training
- Context window up to 32k tokens
- For long-document parsing & reasoning
Stage 4 — Application-Oriented Annealing
- Combine curated GT data + high-quality synthetic
- Unified instruction templates / standardized outputs
- Robustness boost for complex scenarios
- Lays groundwork for RL fine-tuning
---
Reinforcement Learning Innovations
RL, successful in large reasoning LMs, applied here to lightweight OCR models.
Hybrid Strategy:
- Closed-form tasks (detection, parsing): Verifiable reward-based RL
- Open-ended tasks (translation, VQA): LLM-as-a-judge rewards
Outcome: Significant boost in lightweight model performance — enabling edge/mobile deployment.
---
Key Considerations for RL Training
- Rigorous Data Filtering
- Maintain quality/diversity/difficulty balance
- LLM filters out low-quality or trivial data
- Adaptive Reward Design
- Detection/Recognition: IoU + edit distance
- Document Parsing: Structural + content accuracy
- VQA: Binary semantic match reward
- Translation: De-biased, normalized soft scores (0–5 range with expanded mid-granularity)
- GRPO Algorithm & Format Constraints
- Group Relative Policy Optimization core
- Strict length & schema constraints
- Invalid outputs get zero reward
- Trains model to generate standardized, verifiable outputs
---
Official Links
- Project Homepage: https://hunyuan.tencent.com/vision/zh?tabIndex=0
- Hugging Face Repo: https://huggingface.co/tencent/HunyuanOCR
- Research Paper: https://arxiv.org/abs/2511.19575
---
Integrating with AiToEarn for Content Publishing
In modern AI workflows, publishing & monetizing cross-platform is essential.
AiToEarn provides:
- AI content generation
- Publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Analytics & model rankings: AI模型排名
Learn more:
---
Summary:
HunyuanOCR sets a new mark for lightweight, end-to-end, multilingual OCR — with state-of-the-art perception and semantic capabilities. Combined with publishing ecosystems like AiToEarn, it opens strong possibilities for real-world AI deployments in both technical and creative industries.


