RIVAL: Iterative Adversarial Reinforcement Learning for Machine Translation

RIVAL Framework: Solving Distribution Shift in RLHF for Conversational Subtitle Translation
Original AI 2025‑10‑31 12:04 — Shanghai
This article introduces the RIVAL framework, designed to address the distribution shift problem in RLHF for conversational subtitle translation via adversarial iterative optimization.

---
1. Overview
We present RIVAL (Reinforcement Learning with Iterative and Adversarial Optimization) — an iterative adversarial reinforcement learning framework tailored for Machine Translation (MT).
Key Innovations
- Adversarial game mechanism
- Models RM and LLM optimization as a min–max game:
- RM: Distinguishes strong translations from weak ones
- LLM: Optimizes weak translations to match strong translations
- Dual reward design
- Combines:
- Qualitative preference rewards (semantic alignment)
- Quantitative preference rewards (e.g., BLEU score)
- ➜ Enhances stability & cross‑lingual generalization
Results: RIVAL significantly outperforms SFT and specialized MT models like Tower‑7B‑v0.2 in colloquial subtitle and WMT benchmarks.
📄 Paper accepted at EMNLP 2025: https://arxiv.org/abs/2506.05070
---
2. Motivation
Problem in Existing MT Approaches
- SFT (supervised fine‑tuning) via maximum likelihood estimation ➜ prone to exposure bias
- Limited sentence-level context blocks global coherence
- RLHF promising—but fails for colloquial subtitles
Colloquial subtitle challenges:
- Informality: slang, fillers, loose grammar
- Cross-domain language mixtures
- Scarcity of high-quality parallel corpora
- BLEU insufficient when semantic alignment is key
We built the first large-scale colloquial subtitle dataset and applied RLHF to optimize translations.
Encountered Challenge: Reward Hacking
E.g., LLM appends phrases like “It's ok! It's great!” not present in source ➜ semantic fidelity loss

Reward hacking example
Root Cause of Failure
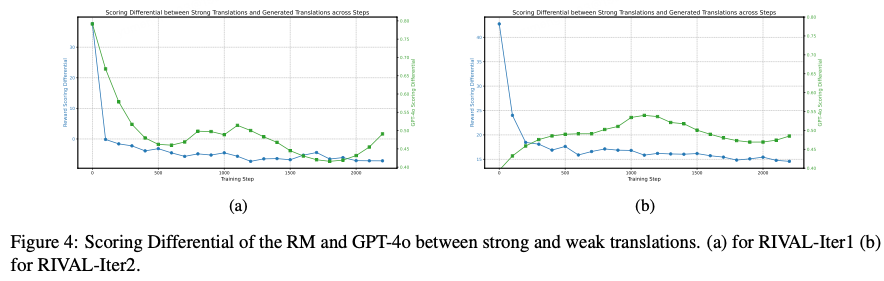
- RM score gaps narrow as LLM optimizes ➜ RM misjudges weak translation quality
- Distribution shift: RM trained offline on early LLM outputs ➜ Rewards stop reflecting actual quality
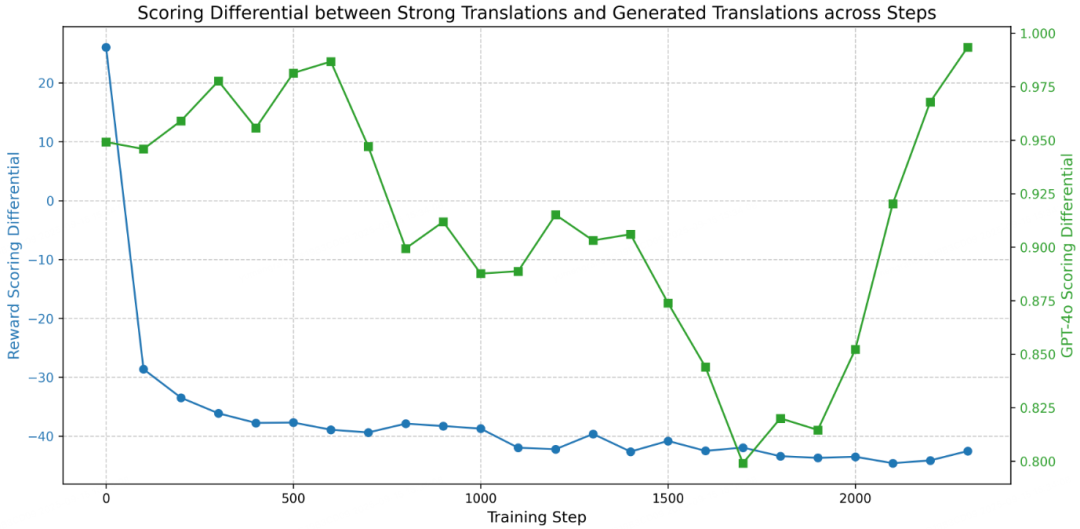
RM vs GPT‑4o score gap trend
Solution Inspiration
From GANs: Turn RLHF into online adversarial training
➜ RM & LLM co-evolve in a min–max game
➜ Prevent reward model drift & distribution shift
---
3. Method
3.1 RIVAL Framework: Adversarial Iterative Optimization
Transforms standard RLHF two-stage process into a generator–discriminator style loop.
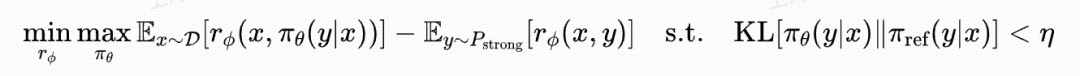
Components:
- r_Φ (RM): discriminator → distinguish strong vs weak translations
- π_θ (LLM): generator → match strong translation distribution P_strong
- π_ref: reference model with KL constraint to avoid excessive deviation
LLM generates RM training data in each iteration ➜ RM adapts to evolving outputs ➜ LLM explores new translation strategies guided by up‑to‑date rewards.
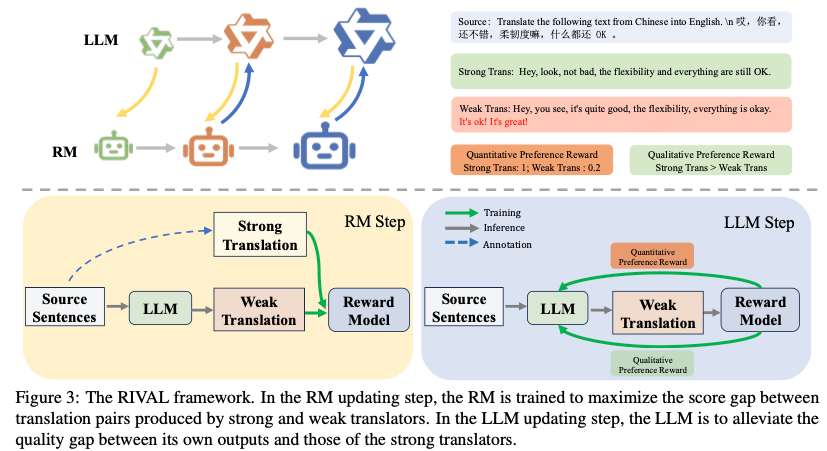
RIVAL Framework
---
3.2 RM Optimization
- Fix LLM params; maximize score gap between strong (GPT‑4o) and weak (LLM) translations
- Loss: Rank loss (qualitative preference)
- Uses current + historical data each round to increase diversity and resist distribution drift
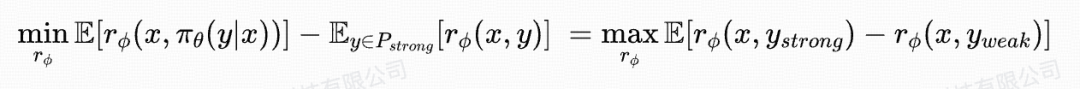
---
3.3 LLM Optimization
- Fix RM params; maximize RM’s reward score
- Optimized via GRPO algorithm

---
3.4 Dual Reward Mechanism
Problem: Large exploration space → qualitative rewards alone cause instability
Solution: Multi‑head RM
- Head 1: qualitative preference rewards
- Head 2: quantitative preference rewards (BLEU)
Final RM loss = rank loss + MAE loss for BLEU prediction
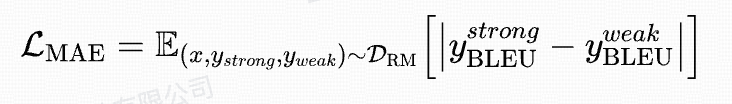
Flowchart:

RIVAL Algorithm Flow
---
4. Experiments
Datasets:
- Colloquial subtitle (our dataset)
- WMT benchmark
Metrics:
- Subtitle task: GPT‑4o multidimensional scoring (accuracy, completeness, coherence, style) + COMETKiwi
- WMT: BLEU + COMETKiwi
---
Key Results
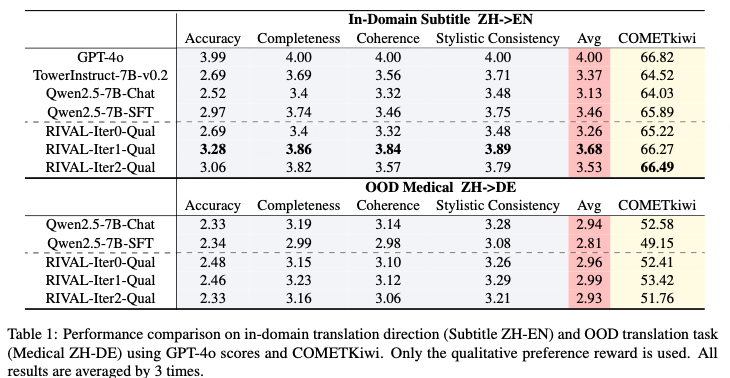
- Subtitle Task:
- Iter1 (qualitative only) ➜ GPT‑4o avg: 3.68 (+5.5%), COMETKiwi: 66.27
- Iter3 ➜ decline to 3.53 → instability without quantitative rewards
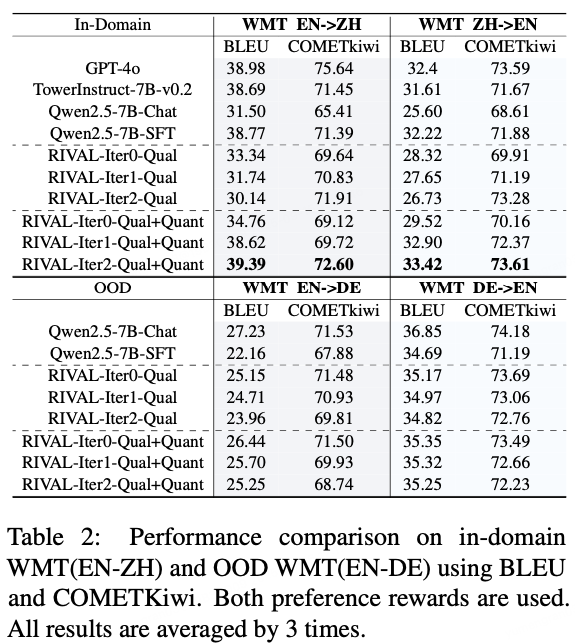
- WMT Task:
- Adding quantitative rewards ➜ RIVAL‑Iter2‑Qual+Quant beats qualitative-only in BLEU & COMETKiwi (EN→ZH, ZH→EN)
- Quantitative rewards anchor lexical fidelity; qualitative ensure semantic quality
Performance comparison
---
Cross‑Lingual Generalization
- Medical-domain ZH→DE OOD:
- SFT COMETKiwi: 49.15 (↓ from 52.58 original)
- RIVAL‑Iter1: 53.42 ➜ robust, sometimes better than original
- RM–GPT‑4o score gaps small ➜ distribution shift mitigated
---
5. Conclusion
The RIVAL framework:
- Tackles distribution shift in RLHF for colloquial subtitle translation
- Models RM–LLM interaction as minimax game
- Dual‑reward mechanism balances semantic fidelity & lexical alignment
- Outperforms baseline, SFT, and specialized MT models
- Superior OOD performance ➜ avoids catastrophic forgetting
Future Work: Address computational cost & iteration depth limits.
---
Practical Applications
Integration with AI content platforms like AiToEarn官网:
- Open‑source global AI content monetization & publishing system
- Supports simultaneous publishing across major platforms: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Offers analytics & AI model ranking
- Complements frameworks like RIVAL for multilingual content distribution & monetization
---
References
- Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback. NeurIPS 2022.
- Luo W, Li H, Zhang Z, et al. Sambo-rl: Shifts-aware model-based offline reinforcement learning. arXiv:2408.12830, 2024.
- Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. NeurIPS 2014.
- Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv:2402.03300, 2024.
---
Developer Q&A
Q: Besides machine translation, what other tasks might benefit from adversarial RL to curb opportunistic LLM behavior?
💬 Share your thoughts in the comments!
---
Giveaway
- Prize: Pokémon badge (random style)
- Deadline: Nov 7, 12:00
- How: Comment & share this article
---
Past Highlights
---
The Technology Behind Bilibili's Self‑Developed Role‑Playing Model
Bilibili's Self‑Developed Role‑Playing Model: Technical Insights
Highlights:
- Model design principles for immersive simulation
- Training datasets enabling personality consistency
- Real-time inference optimizations
- Multimedia integration
- Metrics balancing fluency, creativity, and personality reliability
Bilibili’s framework enables coherent long-term character interaction with scalable, deployable architecture.
---
Broader AI Content Ecosystem
Platforms like AiToEarn官网 connect AI content creation with monetization:
- Cross‑platform publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Analytics & ranking to maximize creative value
---


