# RL Environments and the Hierarchy of Agentic Capabilities
2025 is shaping up to be **the year of the Agent** — AI has stepped out of the chat box and begun to enter the real world.
But the big questions remain:
- **Are we truly close to general-purpose agents?**
- **Or is that still a decade away?**
- **How much economically valuable work can AI agents actually accomplish?**
---
## RL Environments: The New Testing Ground
Training and evaluation methods have shifted from judging single responses to testing **multi-step tool usage** and **complex task execution**.
For those working on training loops and testing, 2025 is undisputedly **the year of RL environments**—virtual worlds where models act, experiment, and learn by completing realistic multi-step tasks.
> **RL** = *Reinforcement Learning*, a training method where AI learns via trial and error, receiving **rewards** for successful outcomes.
---
**Our Experiment:** We tasked nine AI models with 150 real-world-inspired tasks inside an RL environment. The results?
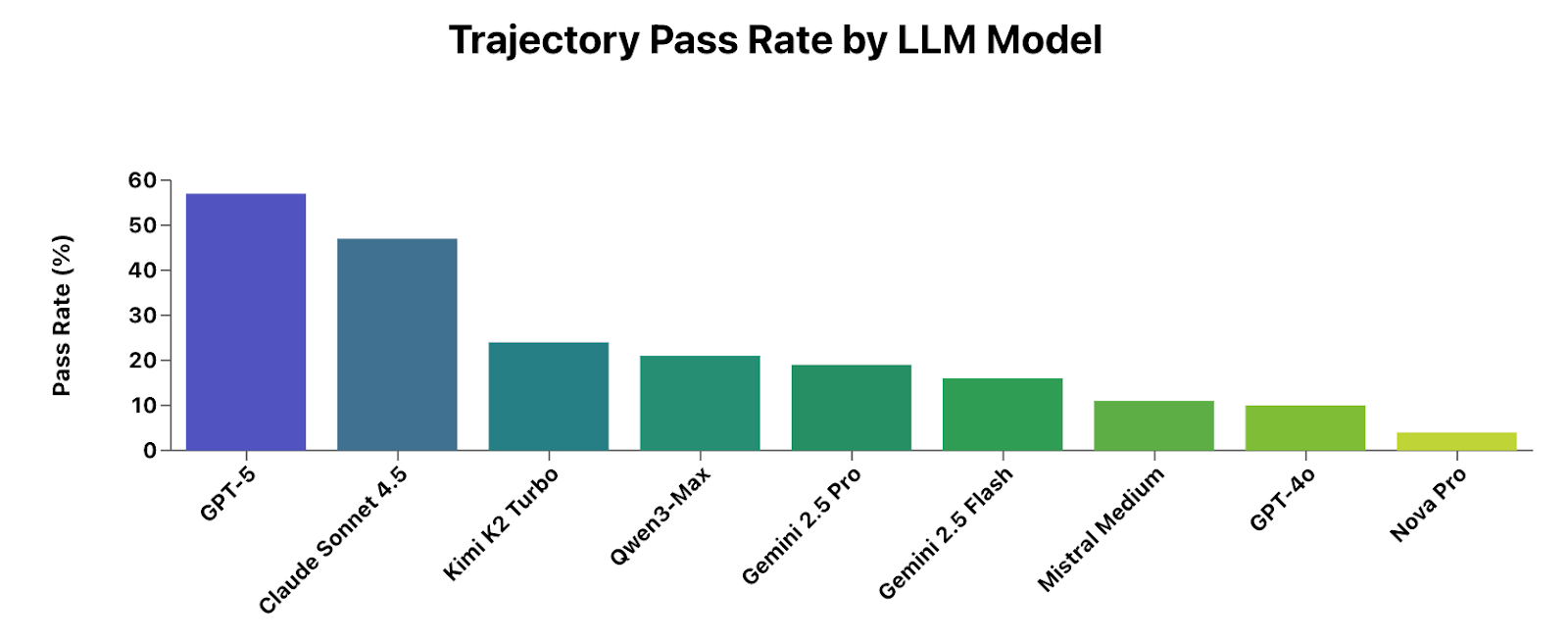
*Even GPT‑5 and Claude Sonnet 4.5 failed over 40% of agent tasks.*
---
### Key Takeaways
1. **GPT‑5** and **Claude Sonnet 4.5** are far ahead in capability — in a class of their own.
2. Both still have **failure rates above 40%**.
Raw scores tell us *who* is winning — but not *why*, nor *how to improve*.
To answer this, we must explore how realistic RL environments are **built**—or rather, **cultivated**.
---
## The Three Essentials of an RL Environment
Every RL environment needs:
1. **A coherent world model** — The overarching framework defining the environment’s context.
2. **Entities** — Objects and their relationships.
3. **A tool system** — Interfaces for agent interaction.
For realistic training, RL environments should be rooted in **authentic work experience**, not abstract simulations. Real-world complexity often **emerges** rather than being designed top-down—exactly what RL environments model.
Our environments grow through contributions from **domain experts**—our “Surgers”—who add realistic entities and tasks based on actual work experiences.
---
## Case Study: Corecraft Inc.
One RL world is **Corecraft Inc.**, an online retailer specializing in high-performance PC components and custom-built computers.
### Entities
- Customers
- Orders
- Support tickets
- Operational records
### Agent Role
Acting as **Customer Service Representatives**, agents handled tasks ranging from quick information lookups to multi-step troubleshooting requiring cross-system reasoning.
**Examples:**
- *Simple:* “How many refunds were issued in July 2025?”
- *Complex:* Compatibility troubleshooting for a gaming PC order combining a ZentriCore Storm 6600X CPU, SkyForge B550M Micro motherboard, and HyperVolt DDR5-5600 memory.
---
## Insights: Performance Still Has Room to Grow
Top-tier models outperform others, yet falter in realistic, multi-step contexts.
**Community-driven RL environments** grounded in human workflows are likely the key to evolving more capable, reliable agents.
Platforms like [AiToEarn官网](https://aitoearn.ai/) provide open-source solutions that:
- Generate and publish AI content across major platforms (Douyin, Bilibili, YouTube, LinkedIn, etc.).
- Track analytics and [AI模型排名](https://rank.aitoearn.ai).
This integration supports **RL-style experimentation** *and* cross-platform output—both crucial for pushing agent capabilities toward monetizable, real-world applications.
---
## Why Customer Service Is a Perfect Testbed
While flashy AI demos often target R&D, **economic value may lie in everyday work**.
Customer service tasks cover:
- **Varied difficulty levels**
- **Different task types**
- **Multiple systems interaction**
Perfect for identifying foundational capabilities agents need to handle **real-world complexity**.
---
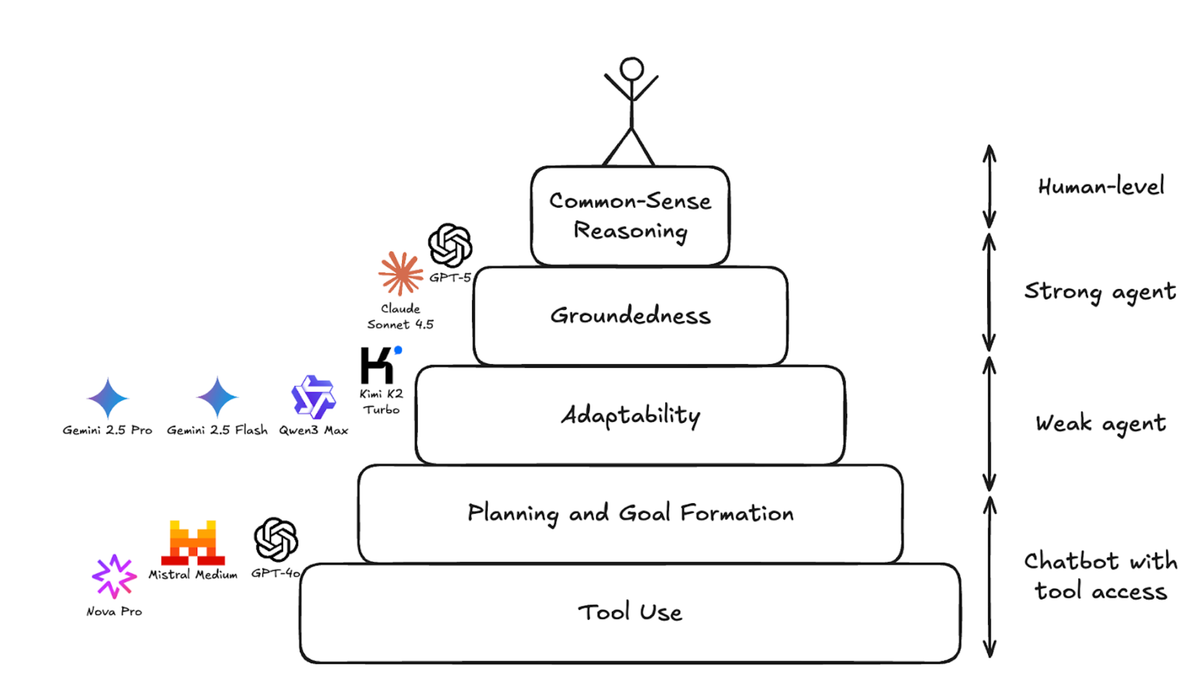
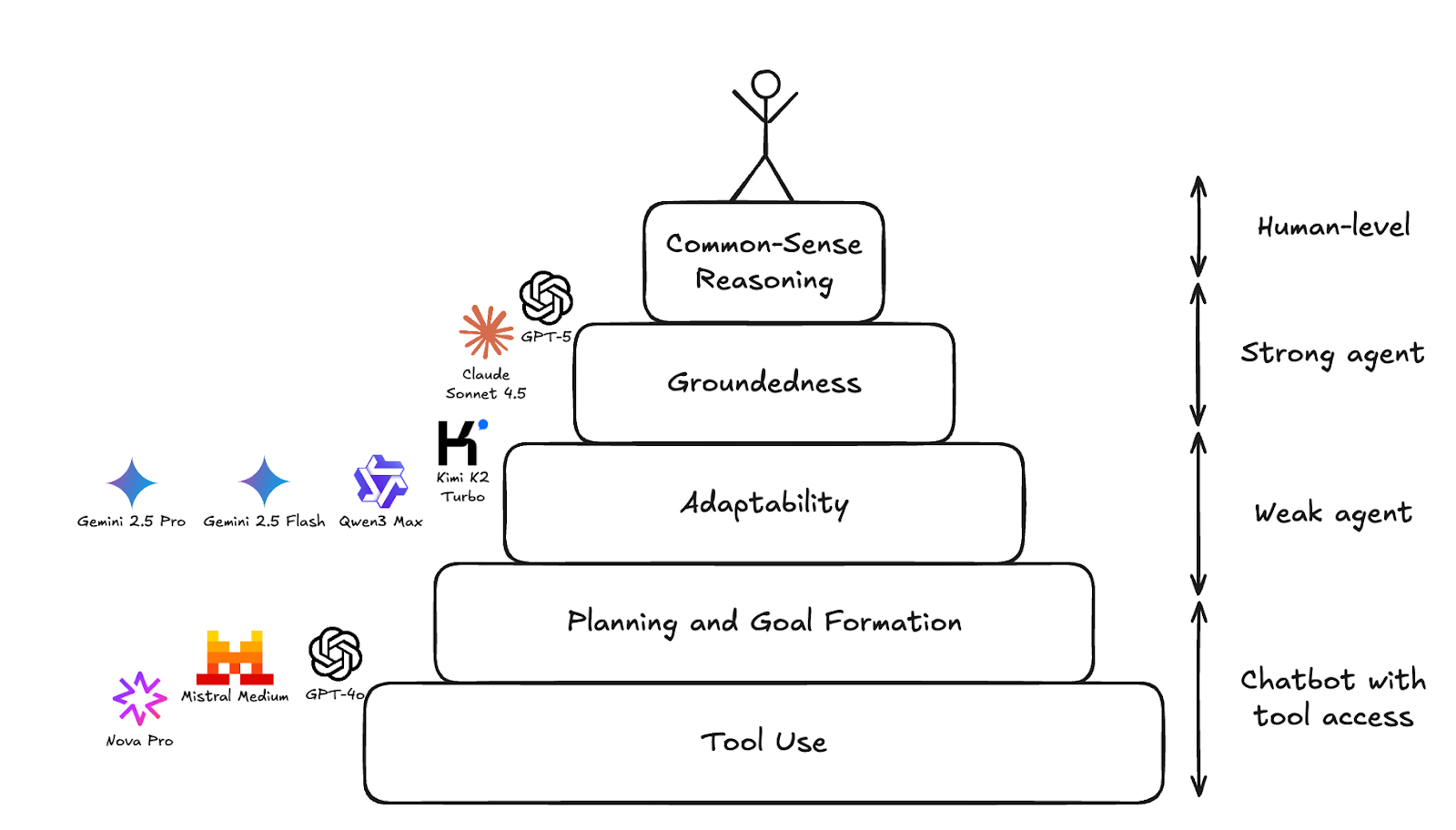
## The Agentic Capabilities Pyramid
Analysis of model failures revealed **patterns tied to specific capability levels**.
We mapped these into a hierarchy: models must master lower layers before reliably operating in open environments.
---
### Pyramid Layers
1. **Foundational:** Tool usage, goal setting, basic planning
2. **Higher-level:** Adaptability, groundedness
3. **Top:** Common-sense reasoning
Capabilities influence each other and evolve in parallel. Even top models sometimes fail basic tasks—like a pro golfer missing an easy putt.
The goal is **diagnosis**: Identify strong levels and pinpoint weaknesses.
---
## Layer 1: Tool Usage, Planning & Goal Setting
A true agent must:
- Break complex tasks into **sub-goals**.
- Map each sub-goal to the optimal tool.
- Correctly populate tool parameters with available data.
- Execute plans without deviation.
**Observation:** GPT-4o, Mistral Medium, and Nova Pro remain stuck at this foundational tier.
Common errors:
- Mis-mapping prompt info to tool parameters.
- Violating technical invocation formats (MCP schema).
- Skipping essential steps.
---
**Example Task:**
Find all “Gold” or “Platinum” loyalty customers with unresolved, high-priority tickets.
Nova Pro’s attempt:

*"gold" is not a customer ID!*
---
**Example Planning Failure:**
Retrieve customers whose orders for SkyForge X670E Pro (recalled) in August 2025 are “fulfilled,” “paid,” or “pending.”
Correct workflow:
1. `searchProducts` → product ID
2. `searchOrders` → orders with product ID & statuses
3. Return customer list
Nova Pro, Mistral Medium: Skipped step 1, misused parameters.
GPT‑4o: Retrieved product ID but ignored 2 of 3 statuses.
---
Until models consistently clear this tier, higher capability evaluation is moot.
---
## Layer 2: Adaptability
Even good plans meet reality’s surprises:
- Incomplete data
- Parameter mismatches
- Missing tool outputs
**Adaptability = Mid-task adjustments**
Gemini 2.5 and Qwen3 follow correct sequences but freeze on error.
**Example:**
Searching products with brand “Vortex Labs” yields no results, because DB stores “VortexLabs”.
Claude Sonnet 4.5 adapted quickly by testing alternative parameters; weaker models did not.
---
## Layer 3: Groundedness
Staying “in-context” means:
- No hallucinated IDs or facts
- Consistency with timeline and task state
**Example:**
Kimi K2 Turbo mismatched years mid-task (2024 vs. 2025).
Claude sometimes drifted contextually but self-corrected.
---
Loss of grounding can cause:
- Silent inaccuracies
- Customer misinformation
- Inconsistent reasoning
Maintaining consistency is essential for **trust and reliability**.
---
## Layer 4: Common-Sense Reasoning
Final barrier before approaching human-level capability.
Traits:
- Connecting multiple clues logically
- Inferring implicit meanings
- Handling completely novel situations
GPT‑5 fails here more often than at lower tiers.
**Example:**
Reclassify "other" tickets as “returns” — missed inference that a delivered package refund = return.
**Example:**
Misinterpreted “My name under my account should be Sarah Kim” as a command to change account name, not identification of the customer.
---
### Why This Matters
Mastering foundational tiers ≠ Human level.
Common-sense reasoning is:
- Undefined
- Possibly emergent from large-scale real-world training
- A critical frontier for AGI
---
## Conclusion
**2025** is the year agents become coherent enough to test for **common-sense reasoning**.
However:
- We’re not at general AI yet.
- Foundational layers must be solid before reasoning abilities can be meaningfully assessed.
Platforms like [AiToEarn官网](https://aitoearn.ai/) can help integrate capability testing with real-world publishing and monetization — ensuring AI advancements translate into economic impact.
---
# Why RL Environments Struggle to Match Reality
While RL shines in simulations (Go, StarCraft, robotics), there’s a persistent **sim-to-real gap**.
---
## 1. Simulators vs. Reality
Simulators are:
- Controlled
- Reproducible
- Simplified
Reality is:
- **Noisy** — sensors fail, data incomplete
- **Hard to model perfectly**
- **Constrained** — safety, cost, ethics
---
## 2. Data & Feedback Limitations
- Simulation: Billions of safe episodes
- Reality: Expensive, slow, risky
- Sparse rewards
- Costly resets after failure
Solutions: Prior knowledge, model-based RL, offline datasets.
---
## 3. Real-World Task Complexity
Real goals:
- Multi-objective trade-offs (safety, efficiency, satisfaction)
- Changing environments
- Hidden states
- External influences (weather, human behavior)
---
## 4. Robustness & Generalization
Overfitting to specific scenarios kills real-world performance.
Approaches:
- Domain randomization
- Uncertainty estimation
- Adaptive strategies
---
## 5. Closing the Gap
Promising directions:
- **Better simulators** with real-world variability
- **Sim-to-real transfer** — domain adaptation, fine-tuning
- **Hybrid methods** — model-based + data-driven
- **Safety-aware RL**
---
## Connecting RL & Deployment
Sharing RL insights widely accelerates progress.
Platforms like [AiToEarn官网](https://aitoearn.ai/):
- AI content generation
- Multi-platform publishing (Douyin, Bilibili, Facebook, Instagram, YouTube, Twitter/X, etc.)
- Analytics & [AI模型排名](https://rank.aitoearn.ai)
Enable RL research to reach and impact a global audience efficiently.
---
**Bottom Line:**
Bridging simulation and reality in RL remains challenging — but with robust environments, diagnostic frameworks like the Agentic Capabilities Pyramid, and integrated publishing ecosystems, we can steadily move toward practical, reliable AI agents.