Save 20+ Person-Months! Huolala’s Offline Big Data Cross-Cloud Migration Final Review

1. Preface
At the end of 2023, our company officially launched the Freight Offline Big Data Migration Project. After five months of intensive, cross-department collaboration, the project was successfully completed in May 2024, achieving a full-scale cross-cloud migration of offline pipelines — covering tasks, data, services, and infrastructure. Over ten departments were deeply involved in this complex initiative.
Even after a year, the journey — full of challenges — remains fresh in our minds. Every difficulty was addressed through multi-party collaboration, laying a solid foundation for the stable operation of subsequent pipelines.
While cloud or cross-cloud migration is a common topic, detailed big data scenario implementation experiences are rare. This documentation aims to share our complete migration process to provide valuable references for others in similar situations. We begin by introducing the migration plan design and full implementation process from a holistic perspective.
---
2. Background Overview
2.1 Big Data Cross-Cloud Architecture
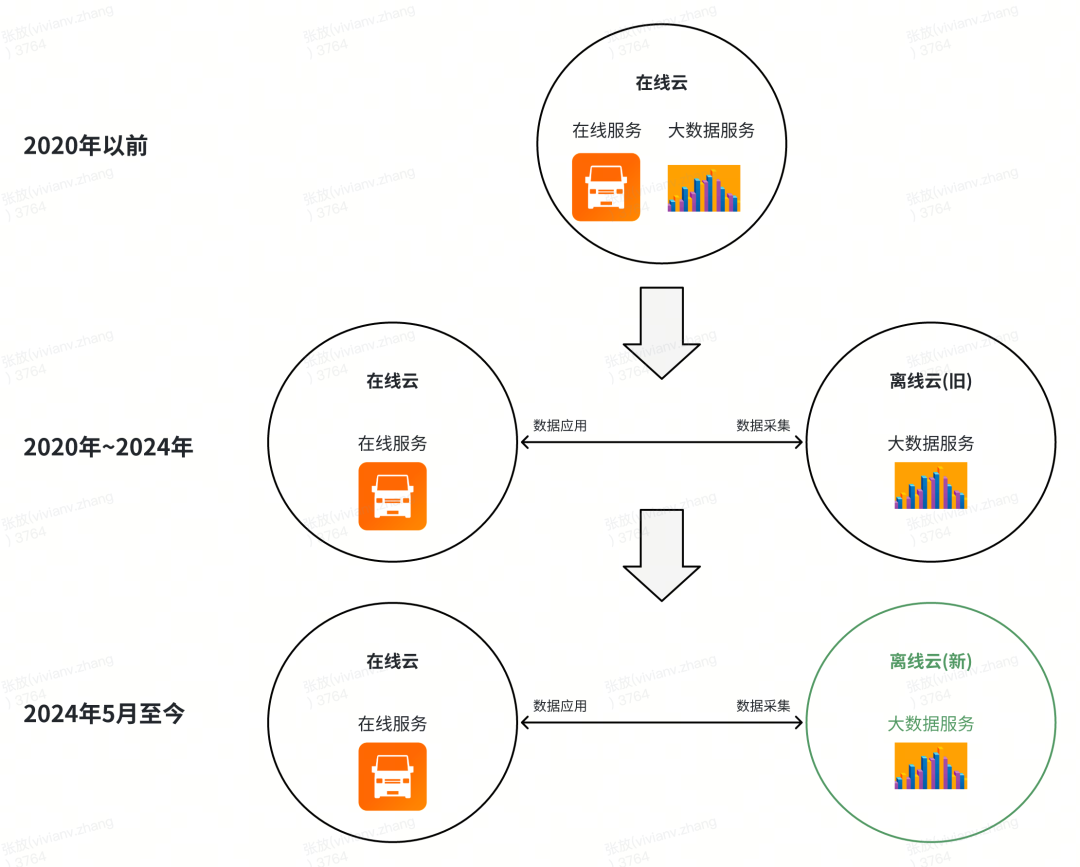
Huolala’s big data IT architecture follows a “multi-cloud + cloud-based self-build” model:
- Pre-2020: Online and offline (big data) services deployed on the same cloud.
- Post-2020: Offline big data services migrated to a dedicated offline cloud — embracing a multi-cloud stage, which improved bargaining power with vendors and allowed leveraging the technical strengths of different clouds.
- After May 2024: Offline big data services migrated again — from the existing offline cloud to a new cloud provider.
---
2.2 Scale of the Offline Big Data
Offline Storage:
The migration covered 40 PB of data accumulated over 10 years of freight operations and 40,000+ computation tasks — placing us among the largest data scales in the freight industry.
| Business Line | Data Volume | Number of Files | Task Count | Departments Involved |
|---------------|-------------|-----------------|------------|----------------------|
| HLL | 40 PB | — | — | — |
Key takeaway: Migrating massive offline big data across clouds requires meticulous planning, scalable architecture, robust monitoring, and rehearsed cutover strategies.
---
3. Migration Plan Design
The solution aimed to ensure:
- Accurate & timely data before and after migration
- Minimal downtime
- No business impact
- Rollback readiness
Core features:
Verifiable
- Performance Verification
- Conduct full storage and computing performance tests early (POC stage)
- Run as many tasks as possible in the new environment to track pipeline performance
- Data Verification
- Compare large tables and files between old and new environments
Rollback Capable
- Implement primary/backup dual-run so that rollback to the previous environment is possible if needed
---
Overall Migration Steps:
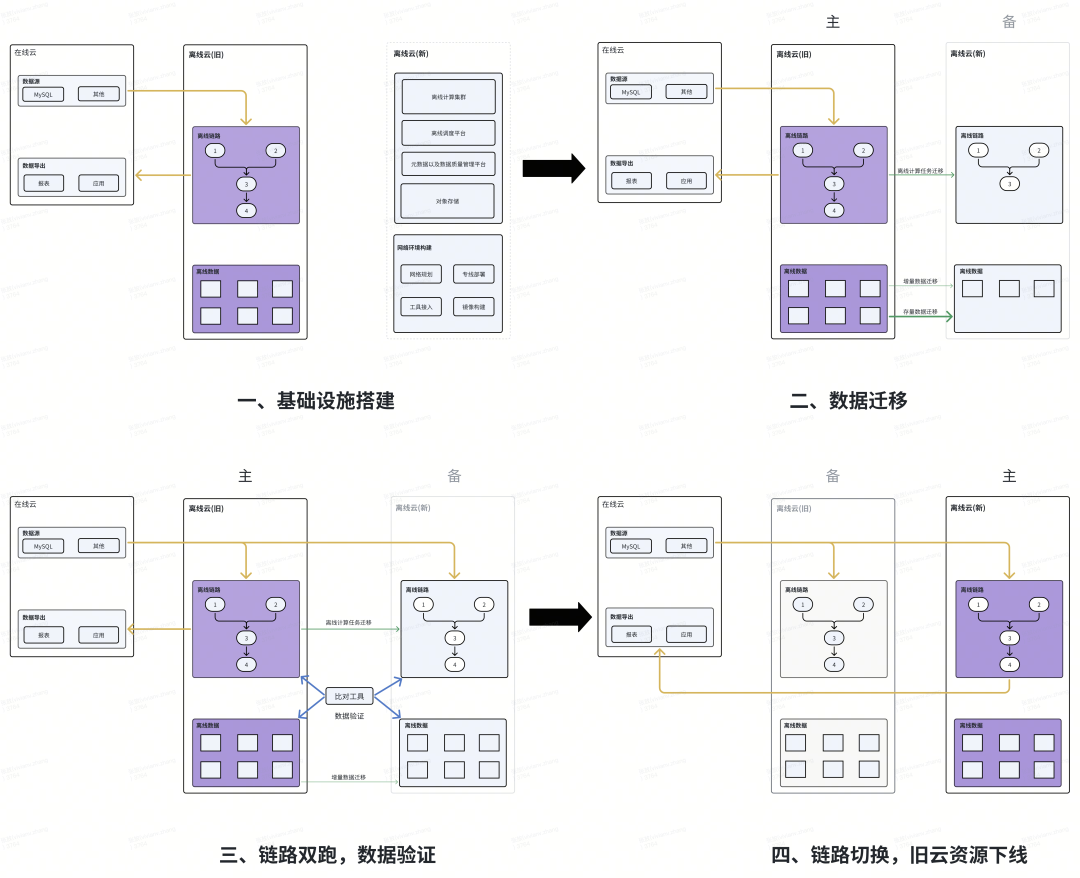
- Infrastructure Setup: Build networks, adapt core components, deliver clusters
- Data Migration: Migrate stored data, metadata, and offline pipeline tasks
- Dual-Run & Verification: Enable pipelines in the new cloud, verify outputs daily
- Primary Switch & Decommission: Switch production to new cloud, keep old as backup until history checks pass; then decommission old resources
---
4. Migration Implementation
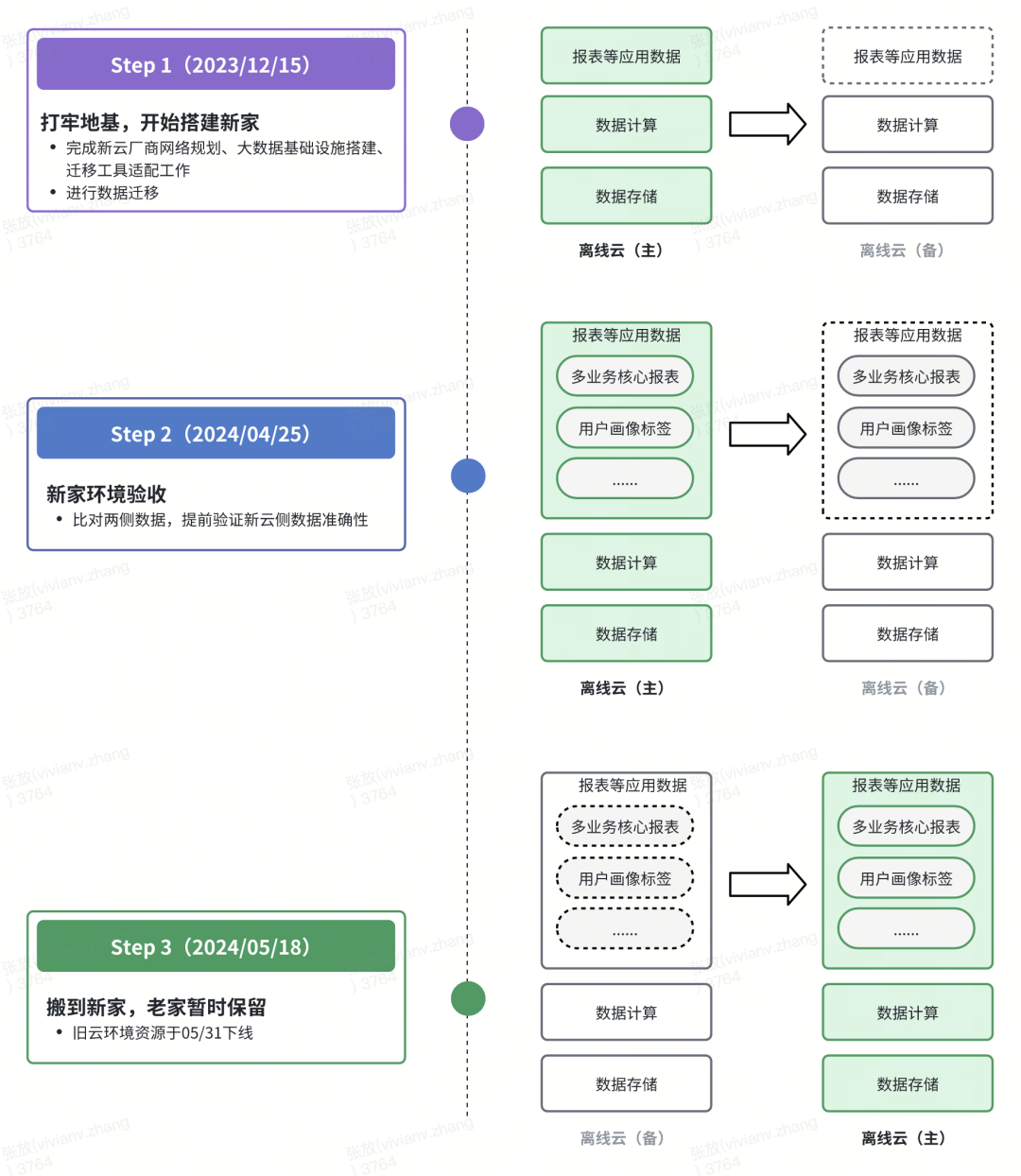
The migration began December 2023 and faced multiple technical challenges. Key focus areas:
---
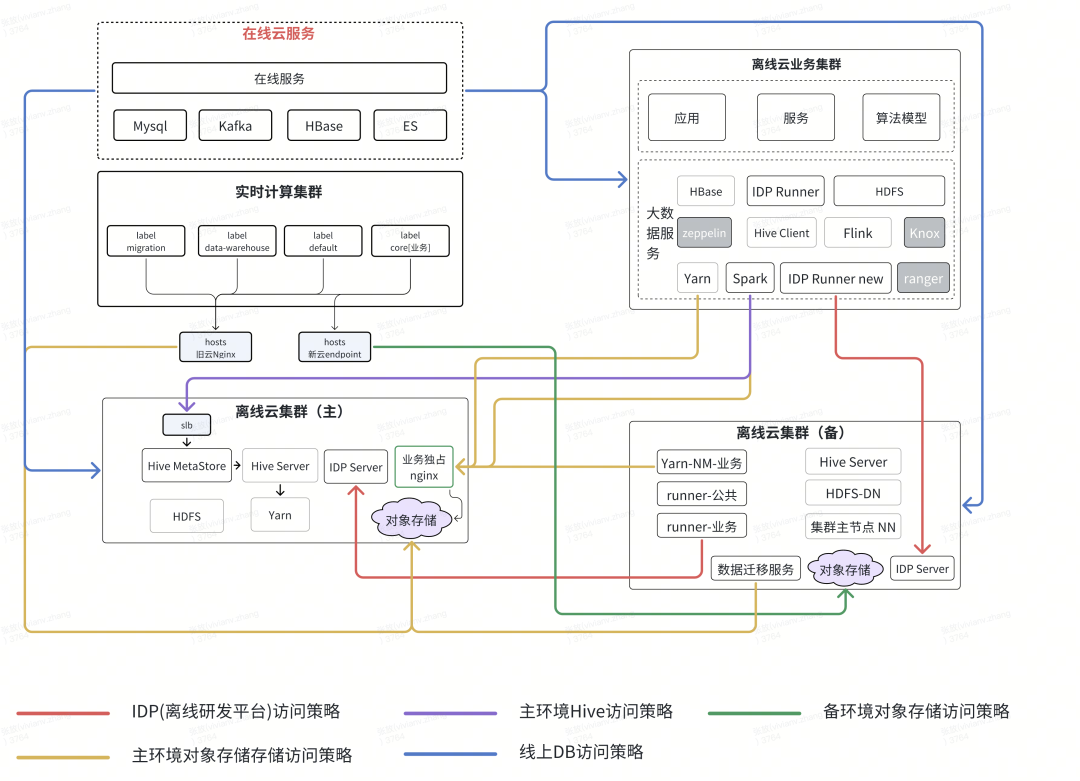
4.1 Network Isolation
Architecture: “Offline Cloud (Old) — Offline Cloud (New) — Online Cloud”
Challenges:
Implementing component-port-level network isolation without affecting active business traffic.
Solutions:
- Topology Mapping: Detailed mapping of clusters, components, and services
- Primary–Backup Link Isolation: Whitelists to control synchronization traffic
- Backup–Online Isolation: Blacklists to ensure new cloud pipelines don’t affect online services during dual-run
- Pre-Switch Validation: Temporarily activate isolations to test non-dual-run tasks
- Post-Switch Configs: Adjust isolation between old/new/online clouds as needed
---
4.2 Migrating Massive Data (40 PB)
Key considerations:
- Daily-changing incremental data
- Data quality and consistency
Measures:
1. Build a High-Throughput Migration Tool
- Custom tool supporting:
- Hive table/partition/file-level data compare
- Hive metadata compare/sync
- Performance:
- Fully saturates 100Gbps bandwidth
- Reduces metadata compare from 5h → 1.5h
- Reduces 25M partitions compare from 18 days → 2 days
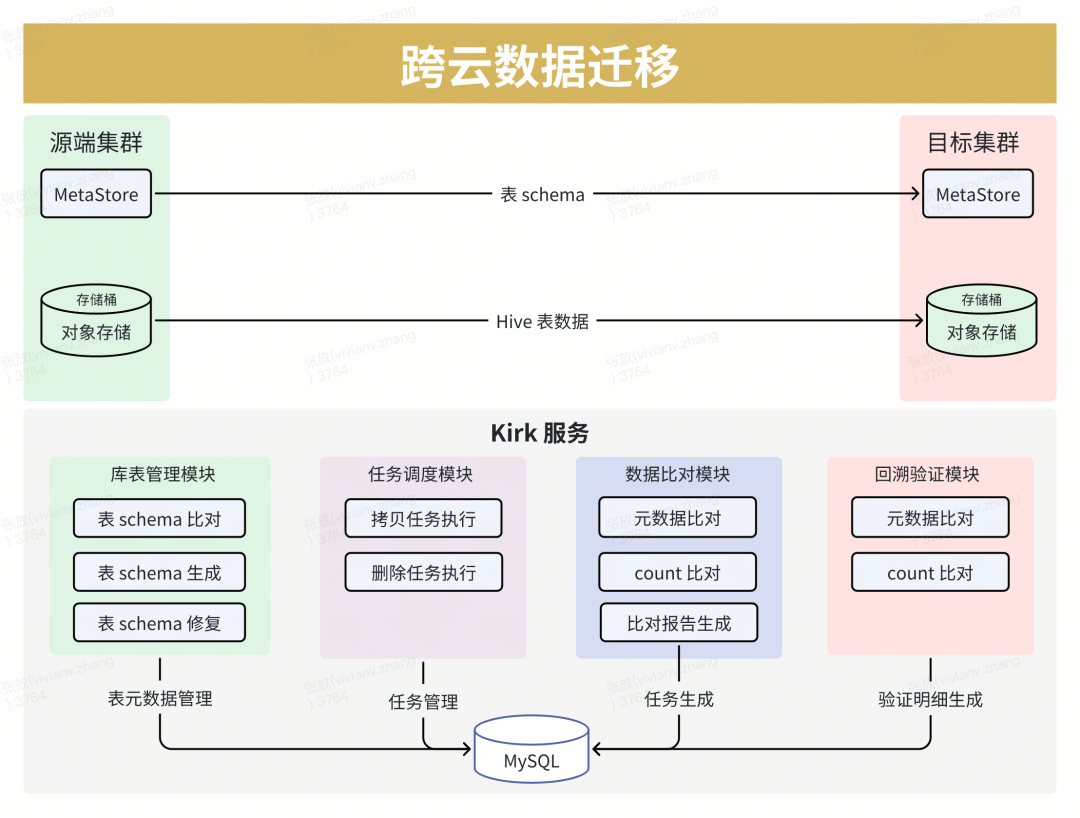
2. Ensure Consistency
- Daily sync >500TB
- Schema diff detection + auto-DDL generation
- Automated code sync across environments
---
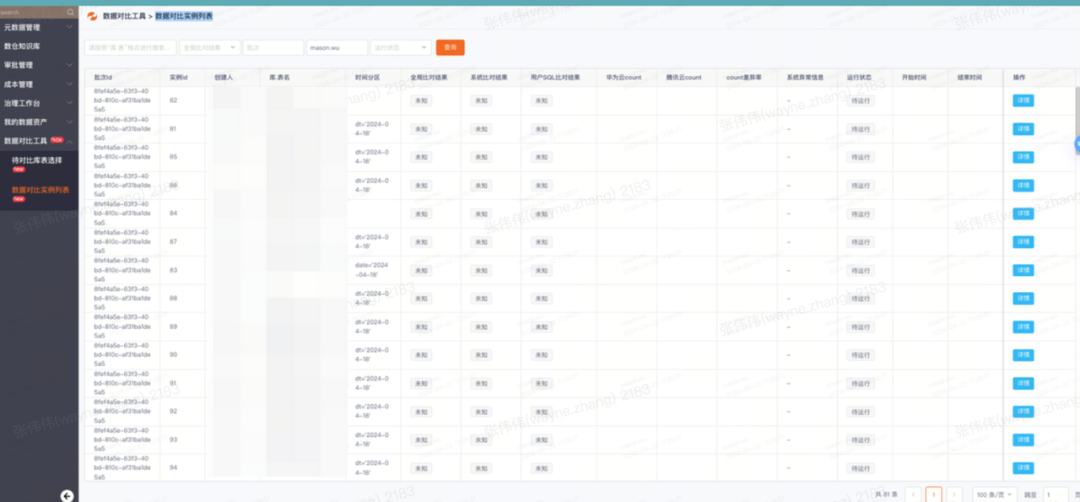
4.3 Data Validation
Dual-run phase = outputs generated daily in both environments.
Tools & Strategy:
- Automated comparison platform reduced manual check time by >90%
- Coarse check: Row count compare per partition/table
- Fine check: Field-level compare with tolerances for minor timing differences

---
4.4 Switching Pipelines
Final phase: switch from backup → primary.
- SOP execution by a dedicated task force
- Dual-run allowed immediate rollback if needed

---
5. Reflections & Summary
Success factors:
- Iterative Plan Refinement: Cover all risk points; adapt continuously
- Automation is Key:
- Migration tools for speed & efficiency
- Automated resource delivery for fast cluster setup
- Automated verification tools saving 20+ person-months
- Cloud Tech Selection: Mature cost estimation, performance testing, stability assurance processes
---
Acknowledgments:
This project was a collective achievement involving Huolala Technology Center and 10+ business units, plus strong support from the cloud provider’s expert team.
---


---
6. Broader Insight: Leveraging Integrated Platforms
In large-scale migrations, integrating automation, analytics, and publishing tools can enhance communication and knowledge sharing.
Example:
AiToEarn官网 — an open-source global AI content monetization platform — allows teams to:
- Generate & publish content across Douyin, Kwai, WeChat, Bilibili, Facebook, LinkedIn, X (Twitter), etc.
- Track analytics & model rankings (AI模型排名)
- Seamlessly integrate AI workflows into technical documentation and reporting
Open source: AiToEarn GitHub
Such platforms can extend migration learnings to wider audiences — internal and external — ensuring knowledge retention and visibility.
---


