Seedream 4.0 vs. Nano Banana and GPT-4o? The Final EdiVal-Agent Image Editing Review

EdiVal-Agent: The New Standard for Multi-Turn AI Image Editing Evaluation

The next stage of AI-Generated Content (AIGC) is shifting from one-time generation to image editing as a primary benchmark for understanding, generation, and reasoning in multimodal models.
Question: How can we scientifically and fairly assess these image editing models?
Researchers from the University of Texas at Austin, UCLA, Microsoft, and others introduced EdiVal-Agent — an object-centric, automated, fine-grained, multi-turn editing evaluation framework.
EdiVal-Agent merges “Editing” and “Evaluation” while functioning as an intelligent agent capable of:
- Autonomously generating diverse editing instructions
- Evaluating across instruction adherence, content consistency, and visual quality
- Achieving higher correlation with human judgment than existing methods

Resources:
- Paper: EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing
- https://arxiv.org/abs/2509.13399
- Project Page:
- https://tianyucodings.github.io/EdiVAL-page/
---
Evaluating Image Edits: What Makes a “Good” Edit?
Current mainstream evaluation methods fall into two types:
- Reference-based Evaluation
- Requires paired reference images
- Low coverage
- Risk of inheriting biases from older models
- VLM-Based Scoring (Visual Language Models)
- Uses prompts to score images
- Common issues:
- Poor spatial understanding → wrong object positions/relationships
- Insensitivity to fine details → misses local changes
- Weak aesthetic judgment → fails to detect artifacts
Conclusion: While VLM scoring is “convenient,” it often lacks accuracy and reliability.
---
EdiVal-Agent: The “Referee” for Image Editing
EdiVal-Agent offers object-aware, automated evaluation — similar to a human who:
- Recognizes each object in the image
- Understands semantic meaning of edits
- Tracks changes across multiple editing turns
Example Scenario:
Base Image: Two horses
- Turn 1: Add “HORSES” text
- Turn 2: Change brown horse to a deer
- Turn 3: Change white horse’s coat to brown

Model Outcomes:
- GPT-Image-1: Instructions followed, but background/details degrade over turns
- Qwen-Image-Edit: Loses visual quality; overexposed by Turn 3
- FLUX.1-Kontext-dev: Preserves background but misinterprets Turn 3
---
Multi-Turn Model Differences & Nano Banana’s Performance
Nano Banana (Google Gemini 2.5 Flash) shows the most balanced performance — stable, accurate, no obvious weaknesses.
---
EdiVal-Agent Workflow
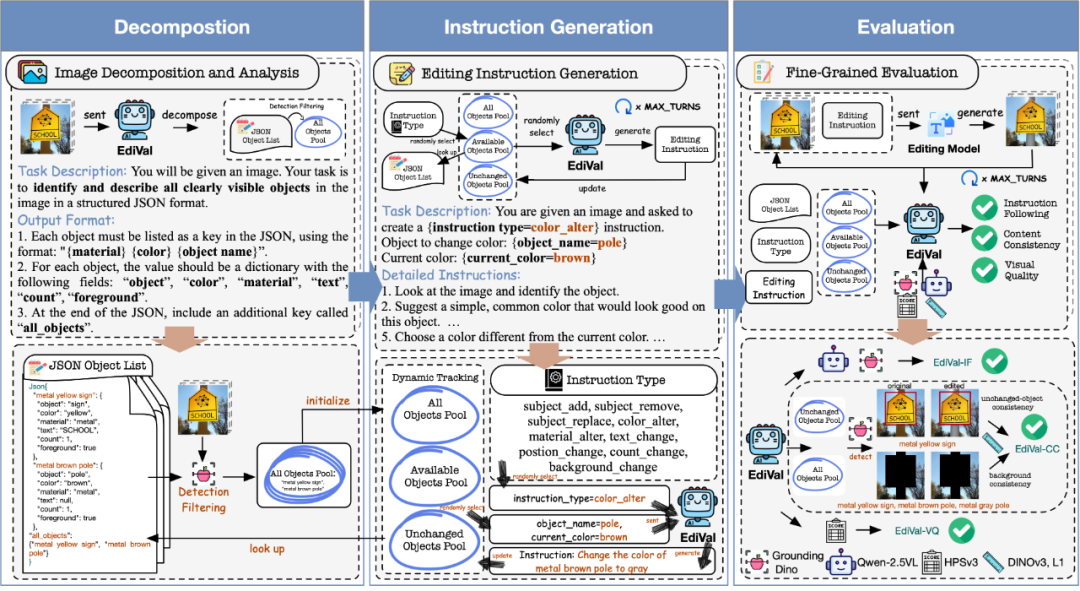
1. Image Decomposition
- Model (e.g., GPT-4o) identifies all visible objects
- Generates structured descriptions for:
- Color
- Material
- Text presence
- Count
- Foreground presence
- Builds an Object Pool, verified with object detection
---
2. Instruction Generation
- Uses scene data to create multi-round edits
- Covers 9 edit types in 6 semantic categories:
- > add, remove, replace, color change, material change, text change, position change, count change, background change
- Maintains three object pools:
- All Objects Pool
- Available Objects Pool
- Unchanged Objects Pool
- Editing process:
- Select instruction type
- Choose target object
- Generate natural language instruction
- Update pools
---
3. Automatic Evaluation
EdiVal-Agent evaluates via three dimensions:
- EdiVal-IF (Instruction Following)
- Checks execution accuracy via object detection & VLM reasoning
- Uses Grounding-DINO for geometric verification in symbolic tasks
- EdiVal-CC (Content Consistency)
- Ensures unedited parts remain unchanged
- Measures semantic similarity for background & unchanged objects
- EdiVal-VQ (Visual Quality)
- Uses Human Preference Score v3 for aesthetics/naturalness
Final Metric:
EdiVal-O = geometric mean of EdiVal-IF & EdiVal-CC
---
Why EdiVal-VQ Isn’t in the Final Score
When replacing a background:
- Some models beautify output (higher aesthetic score)
- Others preserve style (faithful change only)
- Beauty vs. preservation is subjective → excluded from composite score.

---
Human Agreement Study
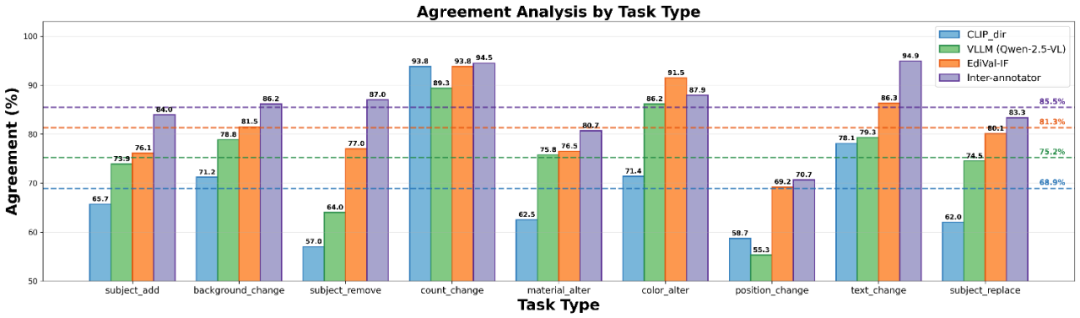
- EdiVal-IF matches human judgment 81.3%
- VLM-only: 75.2%
- CLIP-dir: 68.9%
- Human–human agreement: 85.5%
Takeaway: EdiVal-Agent approaches the upper bound of human consistency.
---
Model Benchmarking: Who Wins?
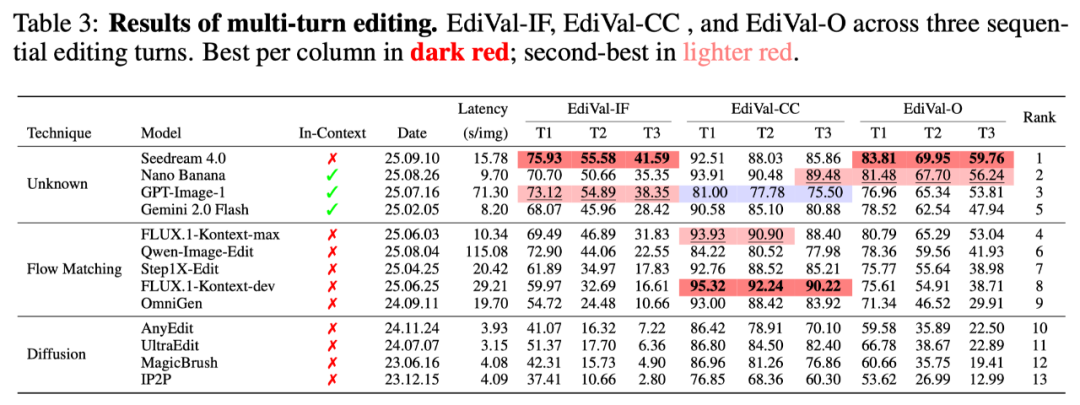
On the EdiVal-Bench:
- 🇨🇳 Seedream 4.0: #1 overall; excels at instruction following
- Nano Banana: Perfect balance of consistency & speed
- GPT-Image-1: Strong adherence but sacrifices consistency for aesthetics
- Qwen-Image-Edit: Best open-source, struggles with exposure bias
---
Connecting Evaluation to Real-World Publishing
Platforms like AiToEarn — an open-source AI monetization platform — let creators:
- Generate AI content
- Evaluate with systems like EdiVal-Agent
- Publish across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Access analytics & model rankings (AI Model Rankings)
---


---
Bottom Line:
EdiVal-Agent’s automated, object-aware, multi-turn evaluation bridges the gap between technical quality and human perception, making it a key tool for benchmarking next-gen image editing AI — and an ideal partner for AI content platforms focused on quality and global reach.