Segmentation Isn’t Enough — Now Comes SAM 3D for Full 3D Reconstruction

Silent, Then a Burst? Meta Unveils SAM 3D and SAM 3
Late at night, Meta dropped a major update, launching:
- SAM 3D — next-generation 3D image understanding
- SAM 3 — advanced Segment Anything Model
---
Overview of SAM 3D
SAM 3D brings an intuitive 3D interpretation of static images. It consists of two specialized models:
- SAM 3D Objects: Supports object and scene reconstruction
- SAM 3D Body: Focuses on human shape and pose estimation
Both models deliver state‑of‑the‑art performance, converting 2D images into detailed, controllable 3D reconstructions.


---
Overview of SAM 3
SAM 3 extends segmentation to tracking objects in both images and videos, using prompts based on:
- Text descriptions
- Example images
- Visual inputs
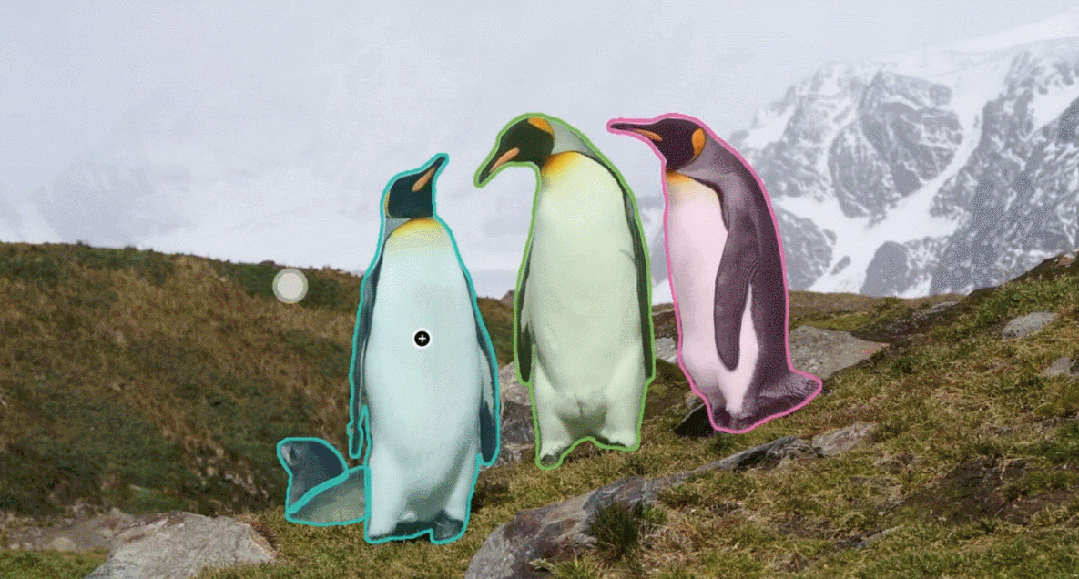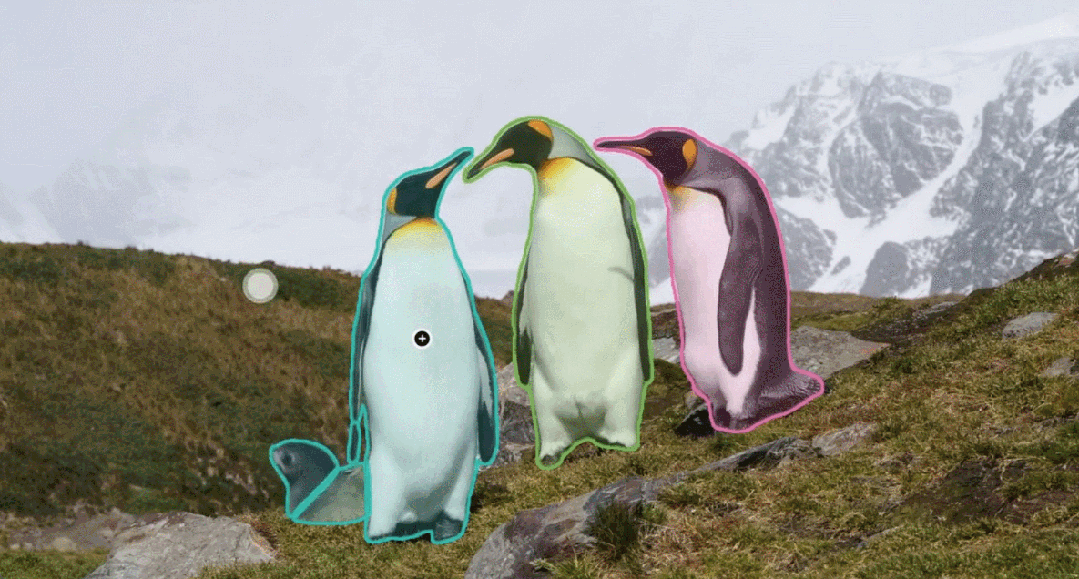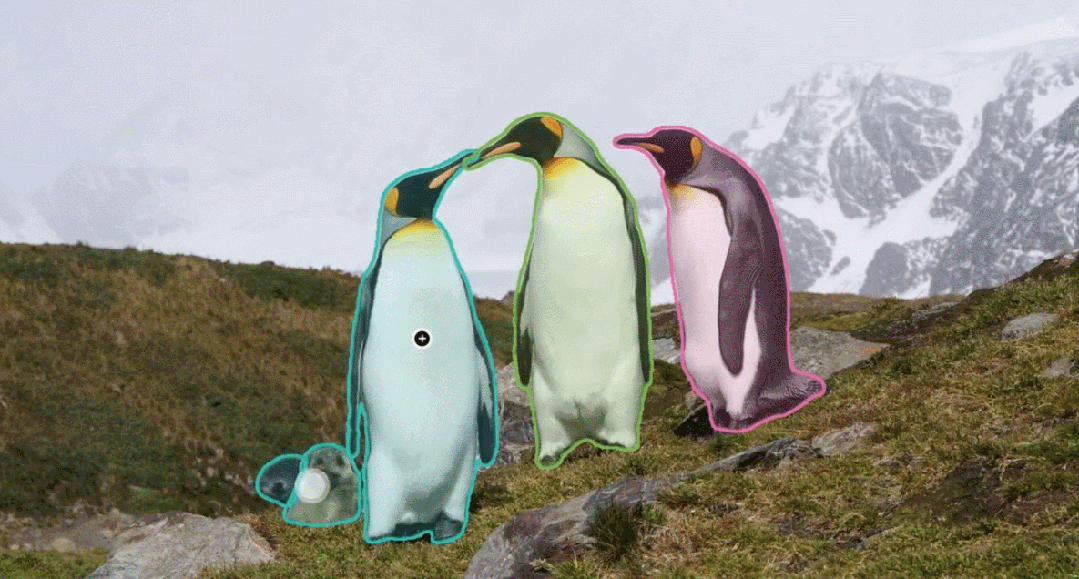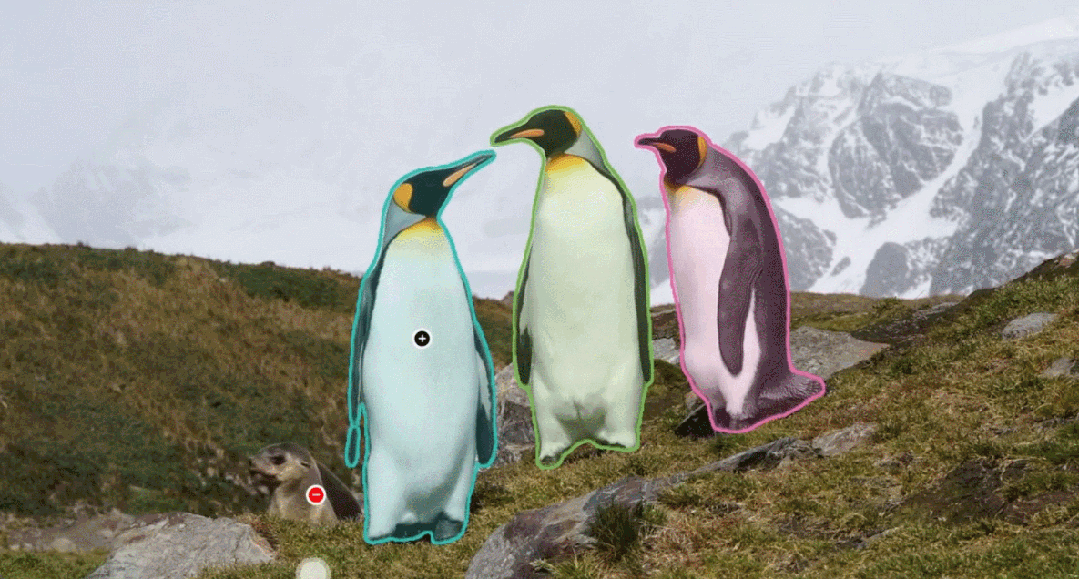
---
Open Source & Playground
Meta has open-sourced the model weights and inference code for SAM 3D and SAM 3.
Alongside, they introduced the Segment Anything Playground — a platform to try these capabilities interactively.
---
SAM 3D Objects
From Static Photos to Controllable 3D Scenes
SAM 3D Objects introduces robust, realistic 3D reconstruction from a single natural image, capable of recreating:
- 3D shape
- Texture
- Scene layout
Challenges in natural images:
- Small objects & occlusions
- Side angles
- Limited pixel data
SAM 3D Objects uses recognition intelligence and context cues to fill visual gaps.
---
Traditional Limitations vs. SAM 3D
Before SAM 3D:
- Single object, high resolution, simple background
- Controlled lighting & poses
- Synthetic environments
These constrained training approaches fail in complex, real-world scenarios.
---
Core Innovations in SAM 3D Objects
- Data annotation engine — breaks bottleneck in large-scale 3D data collection.
- Multi‑stage 3D training pipeline — integrated tightly with this data engine.
How it works:
- Annotators rank candidate 3D outputs instead of building from scratch.
- Professionals refine the hardest cases.
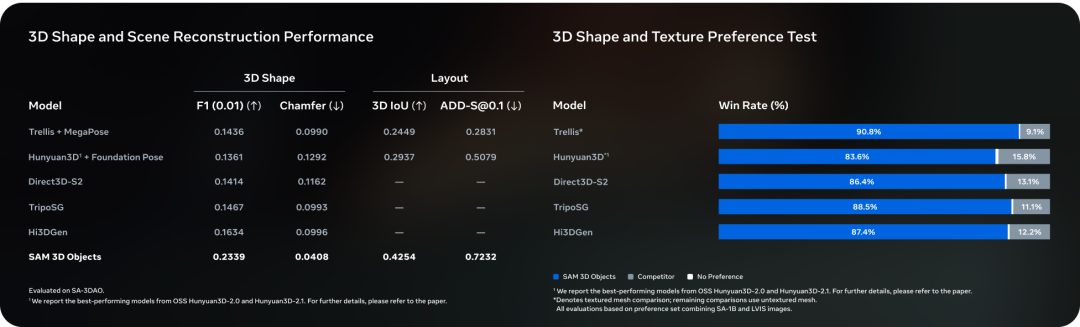
- Nearly 1M real-world images labeled, producing ~3.14M 3D meshes — first large-scale dataset from real photos.


Training Strategy:
- Synthetic data used in a 3D pretraining phase
- Post-training alignment bridges simulated and real worlds.
- Positive feedback loop — better models generate better data → better training outcomes.
Special Dataset:
SAM 3D Artist Objects (SA‑3DAO) — created with professional artist collaboration, outperforming existing methods.
---
SAM 3D Body
Robust Human Shape & Pose Estimation
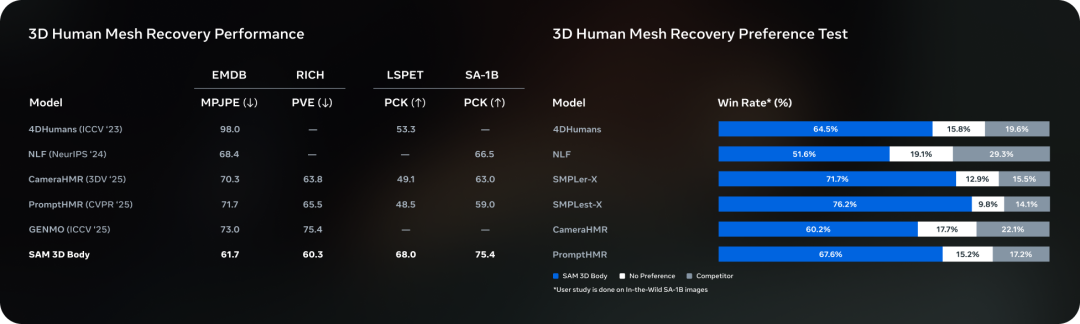
SAM 3D Body reconstructs accurate 3D human poses from a single image, even under:
- Unusual postures
- Occlusions
- Multiple people in frame
Promptable inputs:
- Segmentation masks
- 2D keypoints
Architecture:
- Meta Momentum Human Rig (MHR) — separates skeletal & soft tissue structures
- Transformer encoder-decoder
- Image encoder for high-res body details
- Mesh decoder for prompt-based prediction
Training Scale:
~8M high-quality images — handles occlusions, rare poses, varied garments — surpassing prior state‑of‑the‑art benchmarks.
---
SAM 3
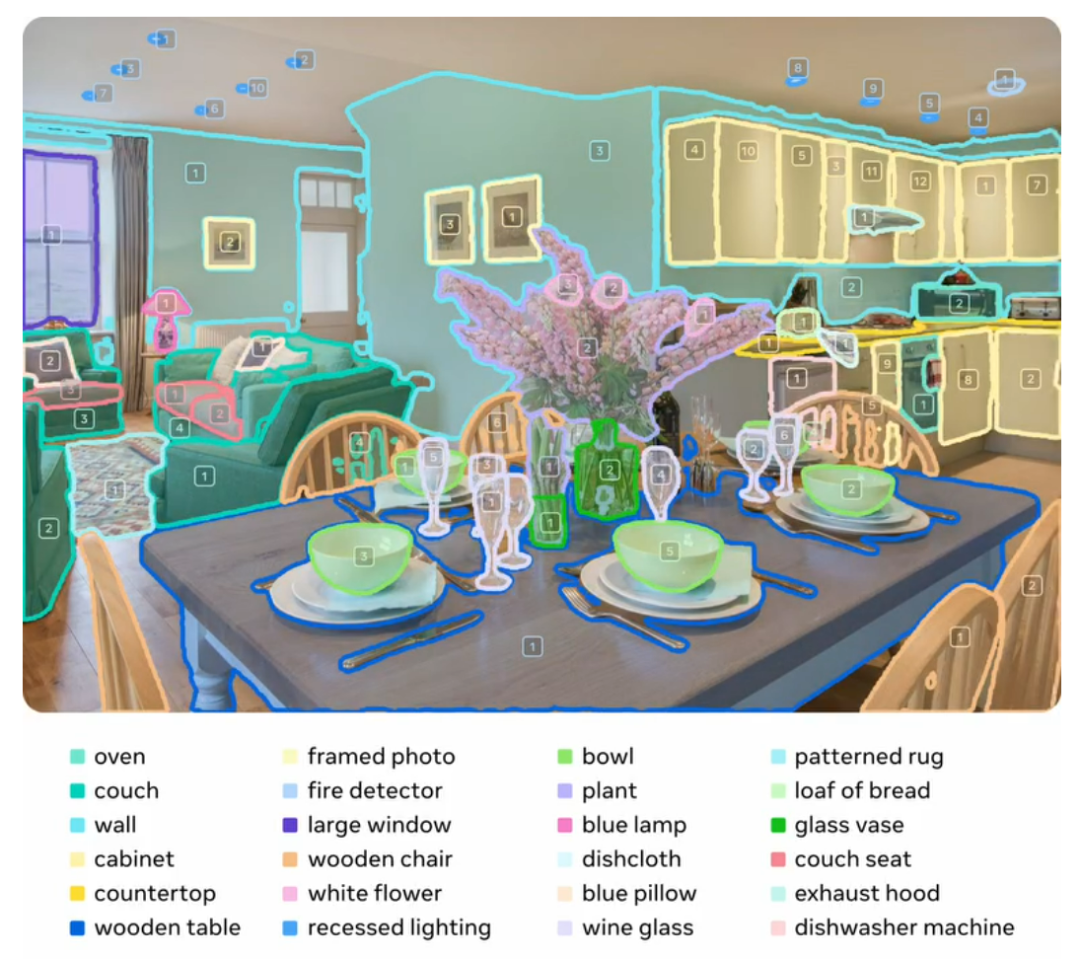
Promptable Concept Segmentation
SAM 3 aims for high-vocabulary, fine-grained segmentation:
- Text prompt: `"that red-striped umbrella"`
- Example image prompt
Benchmark:
SA‑Co (Segment Anything with Concepts) — large vocabulary for more challenging tests.
---
Model Architecture
SAM 3 builds on:
- Meta Perception Encoder — advanced text & image encoding
- Supports image recognition & object detection with performance gains over earlier encoders.
---
Detection Module
- Based on DETR — first transformer-based object detection model
- Memory bank & memory encoder from SAM 2 feed into tracking module in SAM 3
- Multiple open-source datasets & benchmarks integrated
---
Performance Results
- Concept segmentation performance doubled (cgF1 score) over previous models
- Beats Gemini 2.5 Pro and specialist GLEE
- Speed: ~30ms per image (>100 targets) on H200 GPU
- Video: near real-time inference for ~5 concurrent targets

---
AI Monetization Context
Emerging models like SAM 3D require publishing tools.
AiToEarn: an open-source global platform for publishing AI content to:
Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
Capabilities:
- AI content generation
- Cross-platform publishing
- Advanced analytics
- Model ranking
Learn more:
---


