Shanghai AI Lab Releases Hybrid Diffusion Language Model SDAR: First Open-Source Diffusion Language Model to Surpass 6,600 TGS

Large Model Inference Speed & Cost Bottlenecks
SDAR Paradigm as a Breakthrough
Large model inference has become slow and costly, creating a core bottleneck that limits broader adoption. The main culprit is the autoregressive (AR) “word-by-word” serial generation paradigm.
---
Introduction to SDAR
Shanghai Artificial Intelligence Laboratory recently proposed SDAR (Synergistic Diffusion-AutoRegression) — a new paradigm that decouples training and inference.
SDAR blends the high performance of AR models with the parallel decoding advantage of diffusion models, allowing any AR model to be transformed into a parallel decoding system with minimal overhead.

Resources:
- Paper: SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation
- Code: https://github.com/JetAstra/SDAR
- Inference Engine: https://github.com/InternLM/lmdeploy
- Model Collection: https://huggingface.co/collections/JetLM/sdar
---
Highlights from Experiments
- Comparable or superior results to original AR models across multiple benchmarks.
- Multi-fold acceleration in real-world inference.
- Exceptional gains in scientific reasoning tasks.
Example Gains (ChemBench & GPQA-diamond benchmarks):
- ChemBench (chemistry): +12.3 points (60.5 → 72.8)
- GPQA-diamond (science Q&A): +5.5 points (61.2 → 66.7)
The local bidirectional attention mechanism in SDAR is key for interpreting structured knowledge, such as chemical formulas.
Open-source releases include:
- SDAR models from 1.7B → 30B
- Efficient inference engine
- SDAR-30B-A3B-Sci — a powerful open-source diffusion-style reasoning model
---
The “Speed Dilemma” in AR Models
Why AR Dominated
Since GPT, AR has been the dominant paradigm because it naturally aligns with the sequential structure of language generation.
However:
Challenges:
- Inference Latency — AR must wait for each token to finish before generating the next.
- Higher Costs — Fully serial execution increases compute use; the problem worsens with model size.
---
Dual Drawbacks of AR
- Local View Limitation — Reduced ability to interpret global structured knowledge (e.g., formulas).
- Irreversible Generation — One wrong token can cause cascading errors.
In contrast, diffusion models allow global correction through iterative refinement — promising advantages for complex reasoning.
---
Turning to Diffusion Models
Researchers explore Masked Diffusion Language Models (MDLM), which:
- Generate sequences in parallel via iterative denoising
- Potentially remove AR's speed bottleneck
But MDLM has issues:
- Lower Training Efficiency — ELBO optimization converges slower than NLL.
- Higher Inference Costs — No KV cache; must process the entire sequence at each step.
---
Hybrid Approaches: Limited Success
Parallel generation within blocks + AR between blocks sounds promising, but:
- Relies on complex attention masks
- Training cost nearly doubles
---
SDAR: Training–Inference Decoupling
Key idea: Solve training and inference issues separately.
Training Phase:
- Use standard AR training for efficiency & performance.
Inference Phase:
- Add a lightweight adaptation stage that enables parallel, block-based generation (diffusion style).
Benefits:
- Maintains AR advantages (KV caching, variable-length generation)
- Gains diffusion’s parallel decoding for speed
- Low conversion cost
---
Experimental Validation
Questions tested:
- How does SDAR compare to AR in accuracy?
- What speed gains are possible?
- How costly is conversion?
Findings:
- Low-cost conversion, equal or better performance
- Larger models = greater parallel speedup
- Better capability = faster decoding
---
Broad AI Implications
Architectures like SDAR show efficiency and quality can co-exist.
For AI-driven content generation, the same principle applies — platforms like AiToEarn官网 integrate AI generation, cross-platform publishing, analytics, and monetization.
---
Model Comparison: SDAR-Chat vs AR-Chat
Researchers adapted Qwen3 series AR models (1.7B → 30B) to SDAR via “CPT + SFT”.
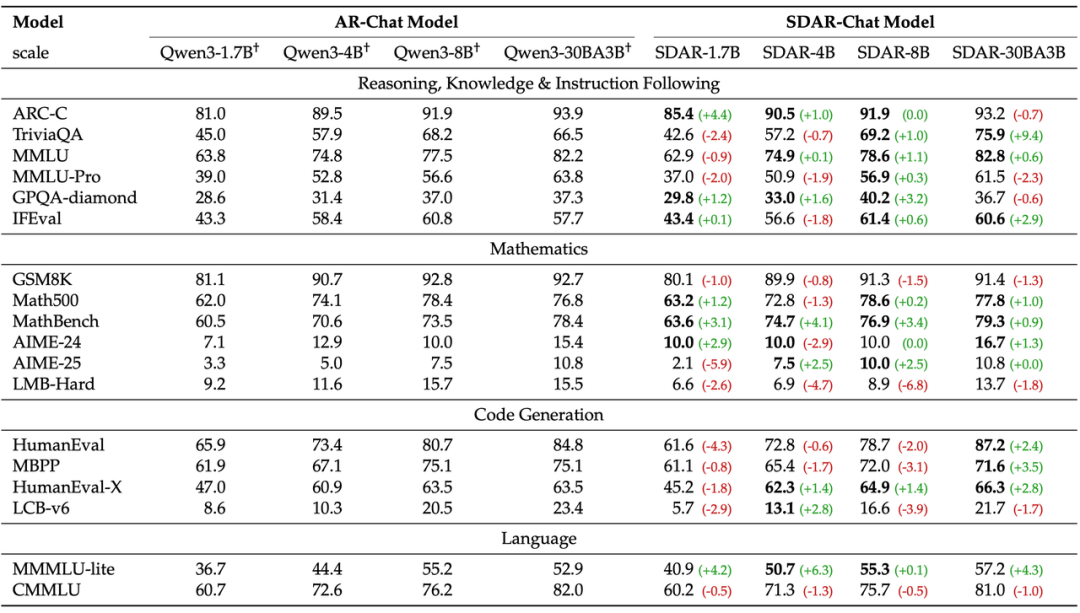
Strict comparison of SDAR-Chat and AR-Chat
Result: At 30B, SDAR matched or exceeded AR in 11/18 benchmarks.
---
Low-Cost Conversion
- Dream requires 580B tokens to train
- SDAR matched AR with only 50B tokens CPT
- Confirms decoupling efficiency
---
Acceleration Results
Theoretical acceleration measured via Tokens Per Forward (TPF):
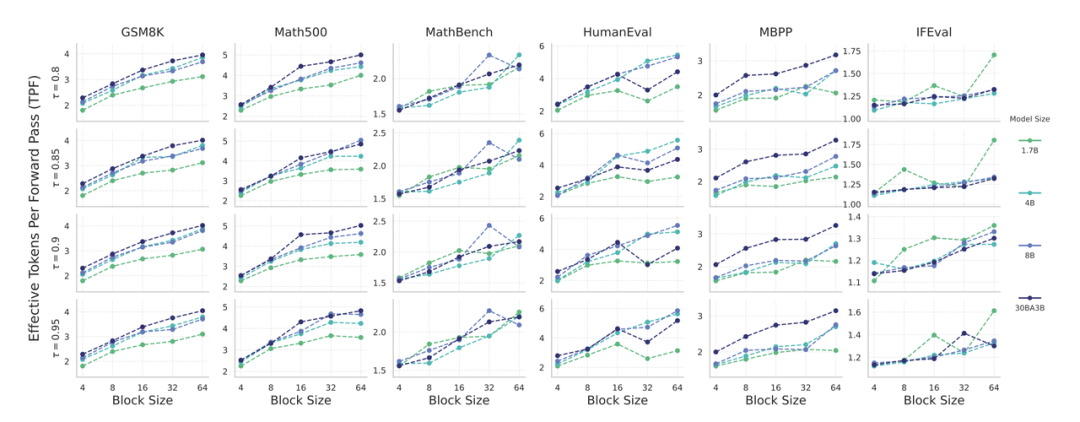
TPF scaling: larger blocks & larger models → greater speed
Real-world on LMDeploy:
- SDAR-8B-chat: 2.3× faster
- Peak: 6,599 tokens/sec on H200 GPU
---
Frontier Science: SDAR-30B-A3B-Sci
Focused on scientific reasoning, SDAR preserved AR’s chain-of-thought and excelled:
Score improvements:
- GPQA-diamond: +5.5 points
- ChemBench: +12.3 points
Test-time Scaling Potential
Multi-round sampling + majority vote:
- AIME-2025: +19.3%
- LMB-hard: +15.7%
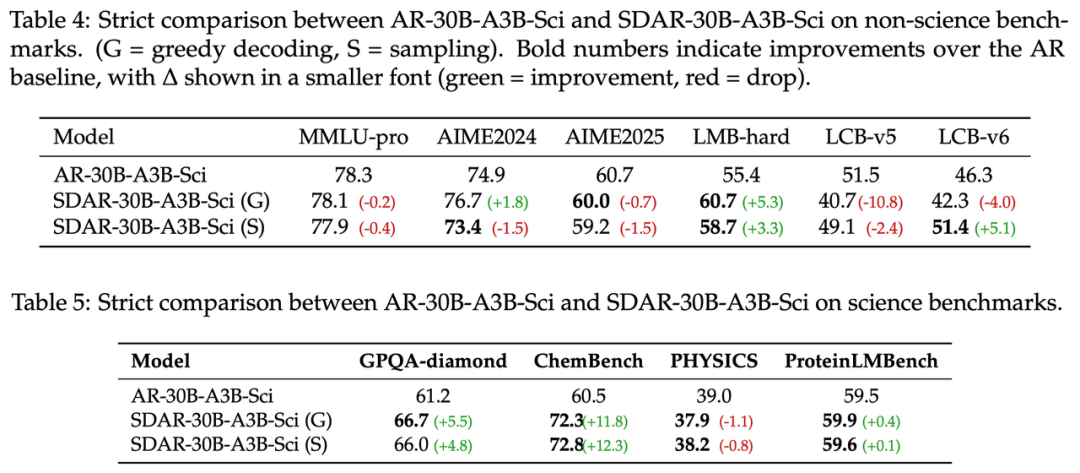
AR vs SDAR Sci model
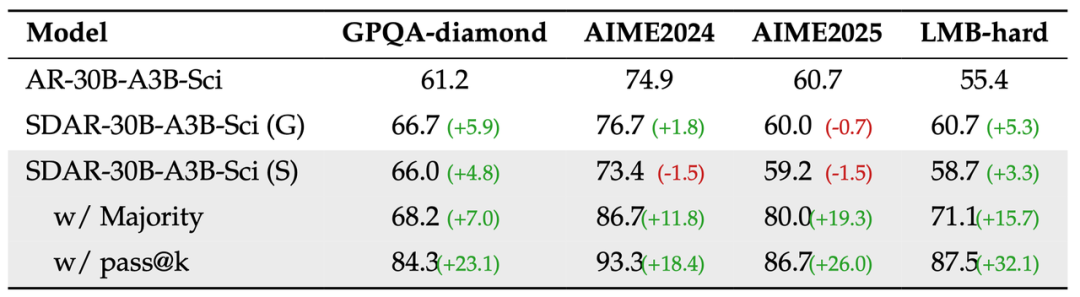
Test-time scaling
---
Summary & Outlook
SDAR’s Contributions:
- First fair comparison of AR vs MDLM training efficiency
- Introduced training–inference decoupling for AR + diffusion benefits
- Universal adaptation framework for dense & MoE models
- Scaling laws for model size, block size, performance, speed
- Full open-source release (models, engines)
Impact:
SDAR lowers application costs, boosts speed, and retains — even enhances — performance.
---
Integration with AI Content Platforms:
SDAR’s strengths can power platforms like AiToEarn — enabling ultra-fast, high-quality content generation, publishing, and monetization across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
See AiToEarn文档 and AI模型排名 for full ecosystem tools.
---
Would you like me to provide a comparative table summarizing AR, MDLM, Hybrid, and SDAR paradigms? This would make key differences in speed, cost, and performance clearer at a glance.