# Large Model Intelligence|Sharing
## Real-Time VLA Models: How Fast Can They Go?
**VLA (Visual-Language-Action)** models are often thought of as slow, with inference times in the tens or hundreds of milliseconds.
However, in their paper *RT-VLA (Real-time VLA)*, researchers from embodied intelligence company **Dexmal** (co-founded by Haoqiang Fan and others) reveal a surprising fact: **they can be *very* fast**.
For example, a typical **Pi0-level model** (3 billion parameters), running on a single consumer-grade **RTX 4090** GPU, can achieve **up to 30 fps**.
This challenges the stereotype of high-latency inference.
---
## Key Findings
- **High Speed on Consumer Hardware:** From >100 ms latency down to **27 ms** (dual-view).
- **Massive Optimization Gains:** Exceeds *openpi* auto-optimization with JAX.
- **Future Frameworks:** Designed for **480 Hz closed-loop control**.
- **Open Source:** Single-file release with only **torch** and **triton** dependencies — **plug-and-play** ready.
This work builds on Dexmal’s earlier release of the [Dexbotic one-stop VLA toolkit](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650996999&idx=1&sn=676c663e7e7d184e4c7f4dd82f72bb03&scene=21#wechat_redirect).

- **Paper:** *Running VLAs at Real-time Speed*
- **arXiv:** [https://arxiv.org/abs/2510.26742](https://arxiv.org/abs/2510.26742)
- **Code:** [https://github.com/Dexmal/realtime-vla](https://github.com/Dexmal/realtime-vla)
---
## 01 — What Pain Point Does This Solve?
Modern robotic VLA models:
- Have **billions of parameters** and strong generalization.
- Still suffer from **high latency** (often 100 ms+).
- Struggle with real-time control.
If execution reaches **camera-level frame rates** (25–50 fps), systems can process visual data without drops — enabling **true real-time VLA operation**.
---
## 02 — How Was This Achieved?
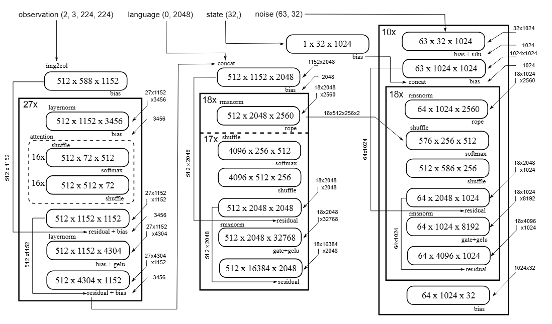
**Pi0 model pipeline:**
1. **Visual encoder**
2. **Single encoder**
3. **Single decoder**
Each can be broken down into **matrix multiplications and scalar ops**.
**Challenges:**
- Transformer-based designs process input as long chains of small matrix operations.
- Pi0’s *flow matching* requires **~10 iterations × dozens of layers** → hundreds of layers & thousands of ops.
**Solutions:**
- Merge and parallelize computational steps.
- Remove bottlenecks.
- Apply additional targeted optimizations.
**Result:** A **“high-performance AI brain tuning manual”** — transforming a large, sluggish model into a **real-time ‘Flash’**.
---
## 03 — Performance Demonstration
Details of benchmarks and demonstrations are available in the [paper](https://arxiv.org/abs/2510.26742) and the [GitHub repo](https://github.com/Dexmal/realtime-vla).
---
## Real-Time in Action: Pen Catching
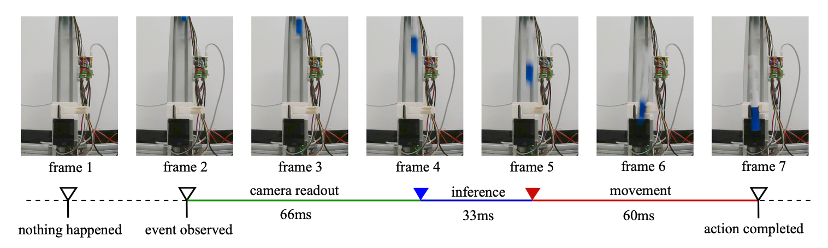
**Task:** Catch a pen in free fall — extremely time-sensitive.
**Requirements:** From detection of motion to actuation within ~200 ms.
This corresponds to the pen falling ~30 cm before grasp.
Performance is **comparable to human reaction times**.
---
## 04 — Next Steps: Multi-Speed Robotic Control
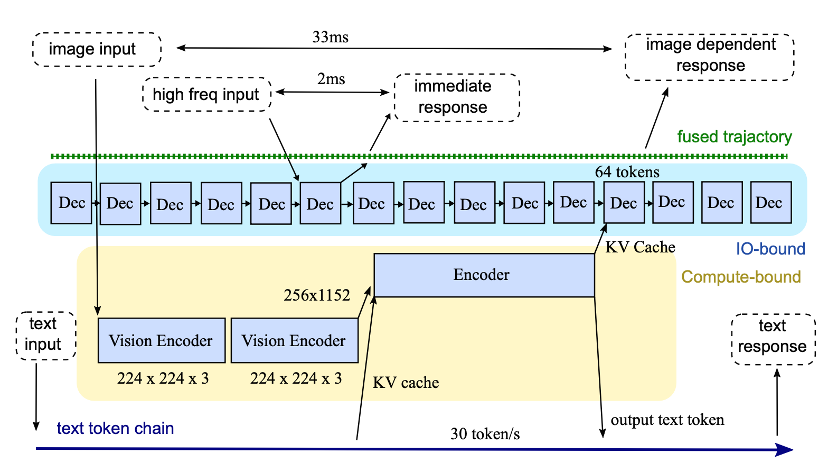
Researchers designed a **GPU-based robotic control framework** with **three reaction pathways**:
1. **Ultra-fast (480 Hz)**
- From force sensors via model *decoder*.
- Like a reflex — up to **480 control commands/sec**.
2. **Visual (30 Hz)**
- From cameras via model *encoder*.
- Tracks motion, predicts trajectories.
3. **Intelligent Reasoning (<1 Hz)**
- For language understanding, planning.
- Enables high-level strategy.
**Goal:** Achieve **480 Hz** control signal generation — approaching the limits of force-feedback control.
---
## 05 — Future Outlook
**Open Questions:**
- **Visual Speed:** Can we reach 60–120 fps and unlock new capabilities?
- **Model Size:** Can we scale from 3B to 7B, 13B+ while keeping real-time performance?
- **Reaction Limits:** Could sub-ms or microsecond-level feedback loops be possible?
**Big Picture:** This marks the start of VLA systems participating in *real* real-time control.
---
## Broader Context: Cross-Platform AI Deployment
As robotic intelligence and AI-driven content creation converge, platforms like [AiToEarn官网](https://aitoearn.ai/) offer:
- AI content generation
- Multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics & AI model ranking
- Monetization tools
Such platforms could accelerate **research dissemination** and **global collaboration** in real-time VLA and robotics.
---