Sniping Gemini 3: OpenAI Releases GPT-5.1-Codex-Max

Gemini 3 Outperformed the Field — OpenAI Responds
OpenAI has unveiled GPT‑5.1‑Codex‑Max, a major upgrade to its Codex model.
Key highlights include:
- No contextual window limit — continuous operation across millions of tokens for tasks lasting 24+ hours
- Higher efficiency in complex task execution
- Improved reasoning and reduced token usage

---
Performance in Simulations
OpenAI compared the GPT‑5.1‑Codex‑Max to the previous GPT‑5.1‑Codex, using a solar system gravity sandbox with additional “suns” added to view gravitational behavior:

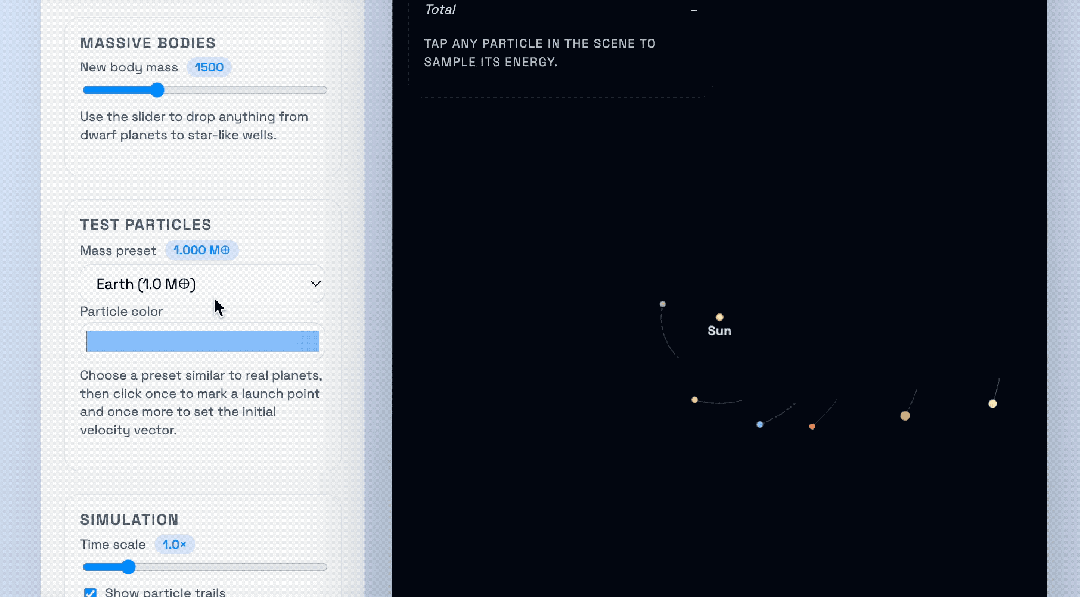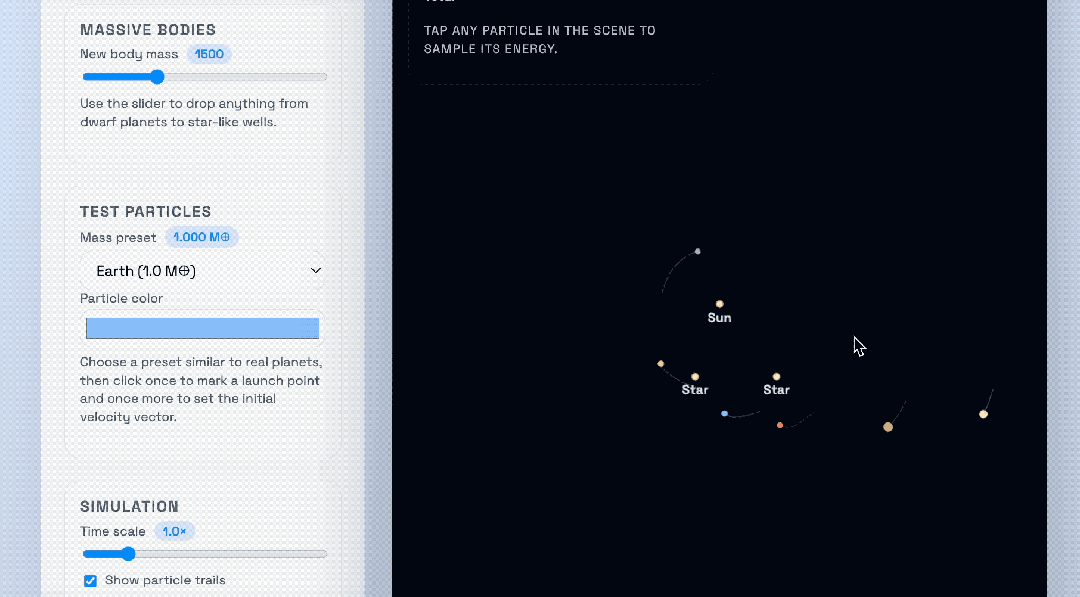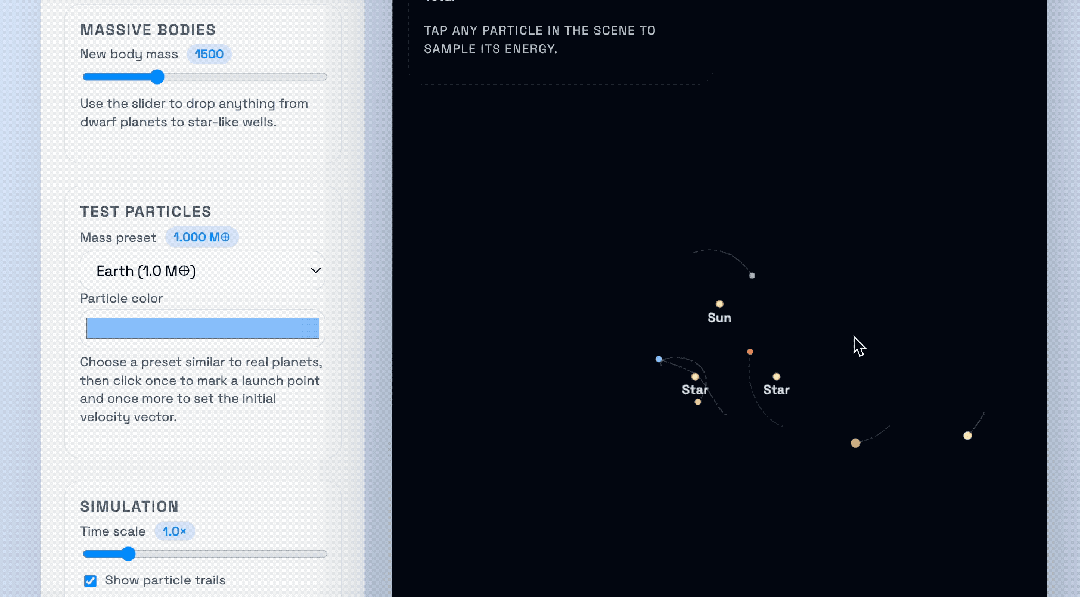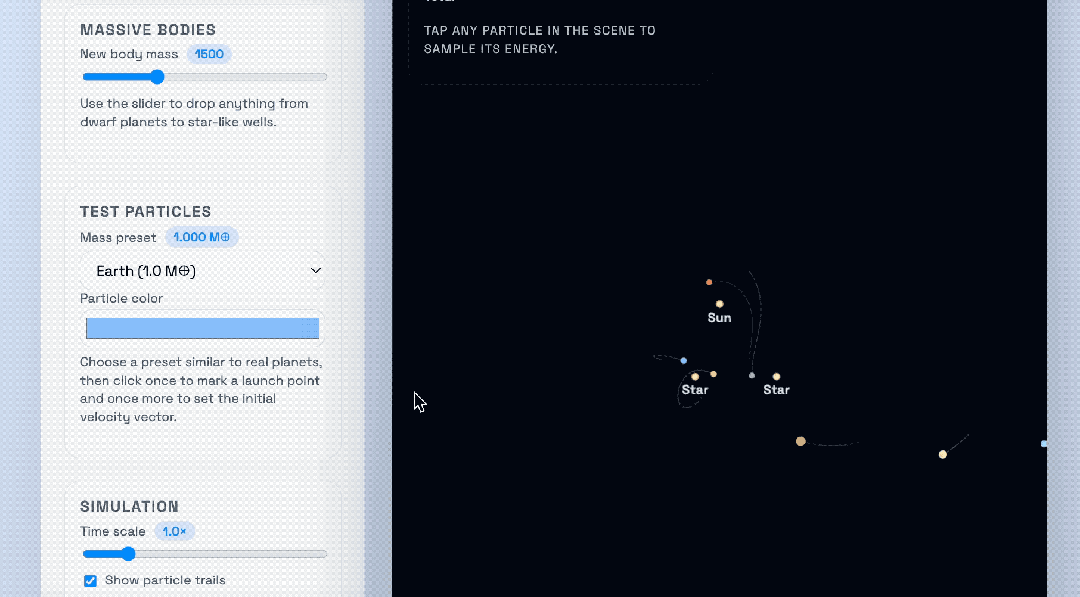
Top: GPT‑5.1‑Codex‑Max
Bottom: GPT‑5.1‑Codex
Resource usage comparison:

---
Altman’s Swift Response to Gemini 3
Just one day after praising Gemini 3, Sam Altman introduced GPT‑5.1‑Codex‑Max — showing OpenAI’s rapid release pace.
---
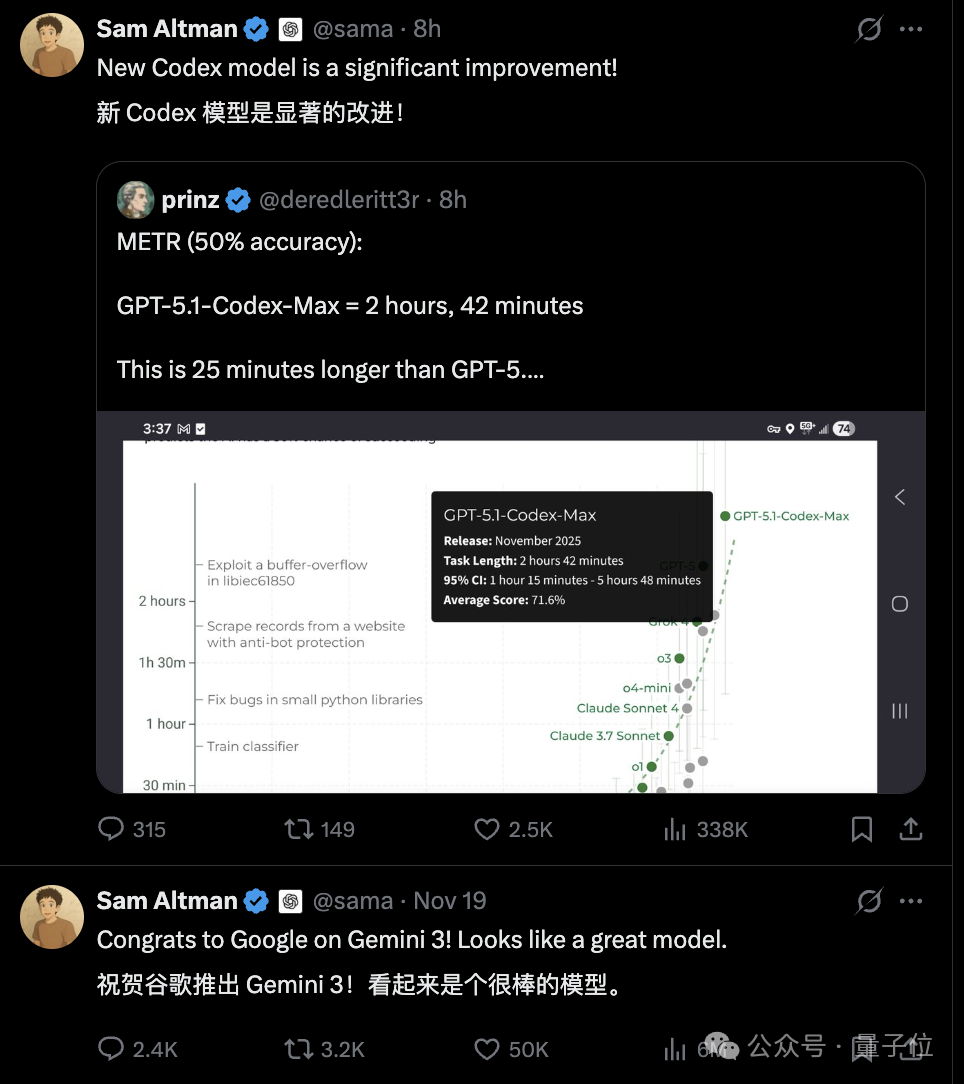
Industry Benchmark: METR and SOTA Achievement
GPT‑5.1‑Codex‑Max set a new state‑of‑the‑art result on the METR benchmark.
What METR Measures:
- AI performance vs. human work hours
- Probability of completing a task within typical human effort
Example:
- GPT‑5.1‑Codex‑Max has a 50% chance of solving a software engineering task that takes a human 2h 42m — 25 minutes longer than GPT‑5’s result.
🔑 Why It Matters:
In AI programming, deep reasoning, endurance, and stability are the capabilities that define competitiveness.
---
Key Upgrades in GPT‑5.1‑Codex‑Max
Training Focus:
- Real‑world software engineering tasks (PR creation, code review)
- Faster, more accurate reasoning
- First OpenAI model running natively on Windows
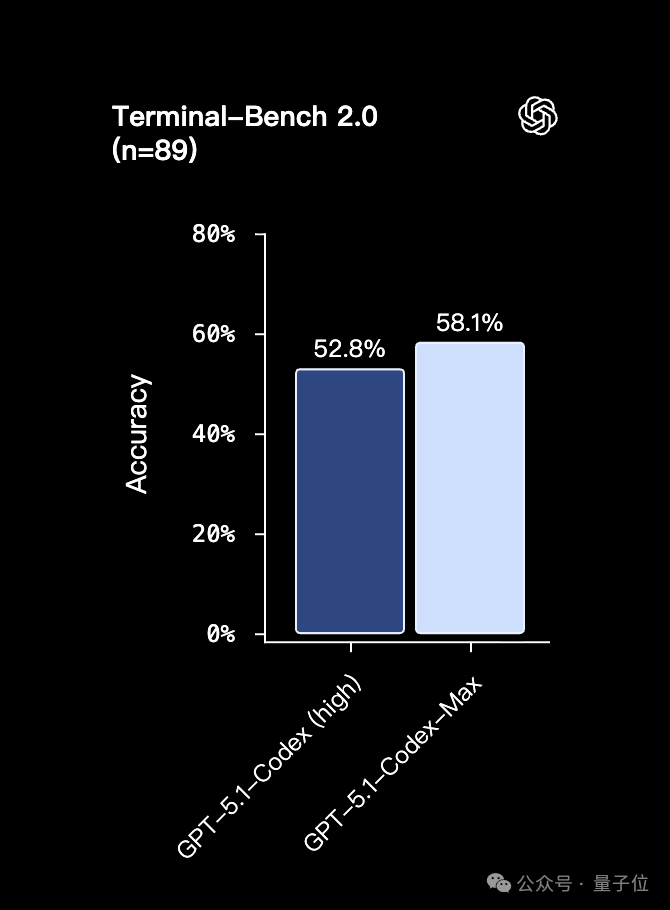
Benchmark Gains:
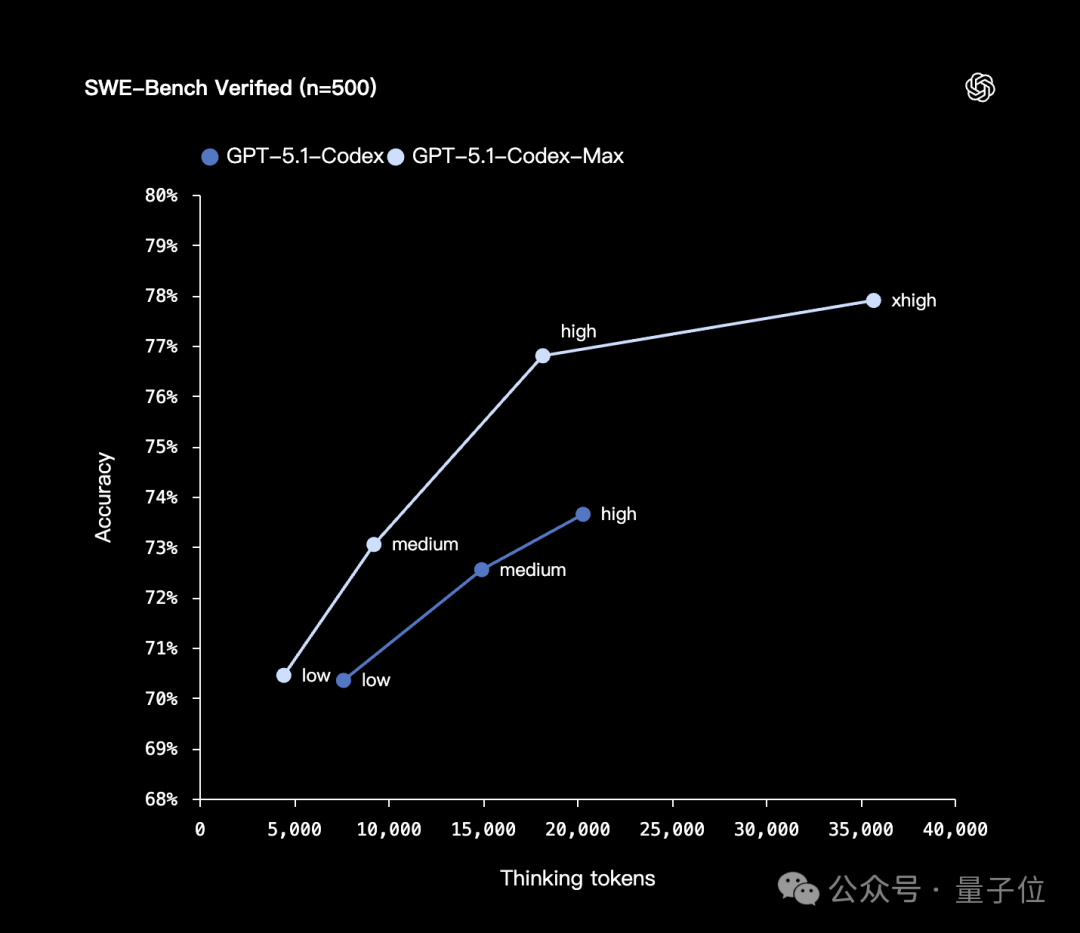
- Superior performance at medium reasoning on SWE‑bench Verified
- 30% lower reasoning token usage
New Mode:
- xhigh reasoning — longer thinking time, better answers for non‑latency‑sensitive tasks
---
Long‑Duration Operation & Context Compression
Breakthrough Feature: Native context compression removes the traditional limit.
How it works:
- Model nears context window limit
- Automatically compresses conversation
- Frees new window and continues without loss
- Sustains task until completion
Benefits:
- 24+ hours continuous runtime
- Processes millions of tokens
- Ideal for large book/document analysis without splitting
- Maintains coherence across extended cycles
Noam Brown notes the model has not yet reached its bottleneck.

---
Integration & Competitive Landscape
Available Now:
- Codex for CLI
- IDE extensions
- Cloud services
- Code review tools
Coming Soon: API access
Competing comparison:
> Claude Code runs faster,
> but GPT‑5.1‑Codex‑Max uses fewer tokens.

---
Multi‑Platform Publishing Synergy
For developers and creators, endurance and efficiency matter in AI coding tools — but publishing is the next frontier.
AiToEarn官网 enables multi‑platform AI content distribution, supporting:
- Douyin
- Kwai
- Bilibili
- Xiaohongshu
- Facebook, Instagram
- LinkedIn, Threads
- YouTube, Pinterest, X (Twitter)
It also offers analytics and AI model rankings.

> The combination of Claude and Codex could be even more powerful.

---
Rapid‑Fire Releases: Silicon Valley 3‑4‑5
Within 24 hours:
- Gemini 3
- Grok 4.1 Fast
- GPT‑5.1‑Codex‑Max
Dubbed the “Silicon Valley 3‑4‑5” moment.

---
Quiet Launch: GPT‑5.1 Pro
OpenAI also released GPT‑5.1 Pro — with little official detail.
Third‑party reviews highlight:
- Better instruction adherence
- Potentially strong IDE integration benefits
- Still trails Gemini 3 in some areas


---
References
- https://x.com/polynoamial
- https://openai.com/index/gpt-5-1-codex-max/
- https://x.com/sama/status/1991258606168338444
- https://x.com/OpenAI/status/1991266192905179613
- https://news.ycombinator.com/item?id=45982649
- https://x.com/mattshumer_/status/1991263717820948651
---
Final Thoughts
OpenAI’s fast iteration reflects the rapidly evolving AI ecosystem.
For creators, platforms like AiToEarn官网 bridge the gap between AI tools and multi‑platform publishing, making it easier to turn output from coding models like Codex‑Max into monetizable content — without losing context or quality.


