Stanford, NVIDIA, and Berkeley Propose Embodied Test-Time Scaling Law

Authors and Affiliations
This work is led by Jacky Kwok, a PhD student at Stanford University.
Co-corresponding authors include:
- Marco Pavone – Director of Autonomous Vehicle Research at NVIDIA
- Azalia Mirhoseini – Stanford Computer Science Professor & DeepMind Scientist
- Ion Stoica – UC Berkeley Professor
---
Vision-Language-Action Models & Real-World Robustness
Vision-Language-Action (VLA) models have shown remarkable results in visuomotor control tasks.
However, maintaining robustness in real-world environments remains a challenge.
Key Finding
By implementing a generate-and-verify approach during inference—increasing test-time compute—the team achieved significant improvements in generalization and reliability.
Additionally, the paper introduces the Embodied Test-Time Scaling Law:
> Increasing sampling and verification during inference leads to predictable gains in success rates and stability.

Paper Details:
- Title: RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models
- ArXiv Link: https://arxiv.org/abs/2506.17811
- Code Repo: robomonkey-vla.github.io
- Conference: CoRL 2025
---
Embodied Test-Time Scaling Law
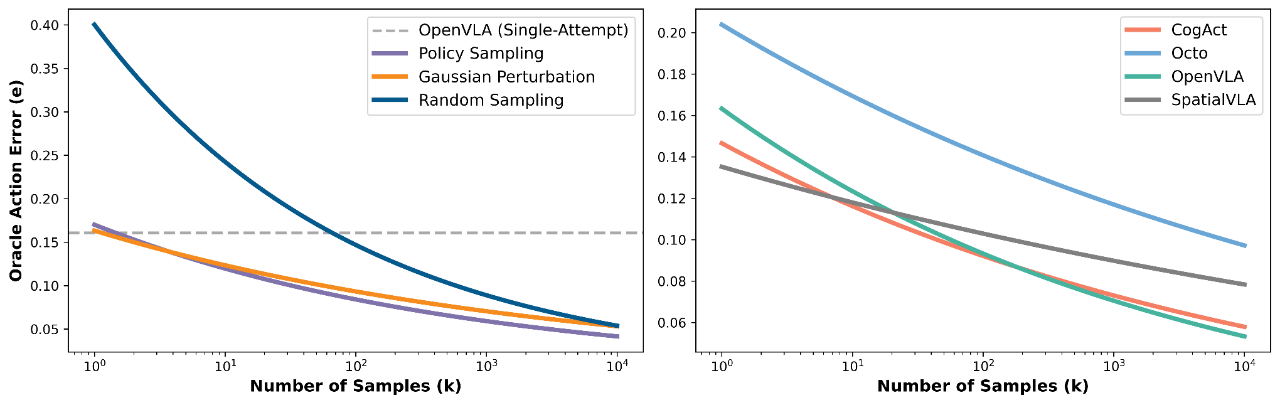
Experimental Insights
- Increasing the number of candidate actions at inference reduces error rates
- Effective methods include:
- Repeated action sampling from the policy model
- Gaussian perturbation of sampled actions
- Random sampling in a discrete action space
- All outperform a single-shot OpenVLA baseline, when paired with an oracle verifier
Power-Law Relationship
Across widely used VLA models (CogACT, Octo, OpenVLA, SpatialVLA), action errors predictably decrease as Gaussian perturbation sample counts rise.
➡ Implication: Robotic control should leverage candidate generation + verification filtering, rather than generation alone.
---
Core Research Questions
- Training Verifiers – Can learned action verifiers rival oracle verifiers in enhancing VLA stability?
- Synthetic Data Expansion – Can large-scale synthetic datasets improve verifier training and downstream performance?
- Deployment Feasibility – How can low-latency, scalable test-time scaling be deployed on physical robots?
---
Method Overview
Phase 1 – Action Verifier Training

Process:
- Use a VLA model on a robot dataset to sample N candidate actions per state
- Cluster actions into K representative actions
- Measure RMSE vs ground truth to form a synthetic action preference dataset
- Fine-tune a VLM-based action verifier to distinguish good vs poor actions
- Train using the Bradley-Terry loss + correction for preference strength
---
Phase 2 – Computation Expansion at Inference
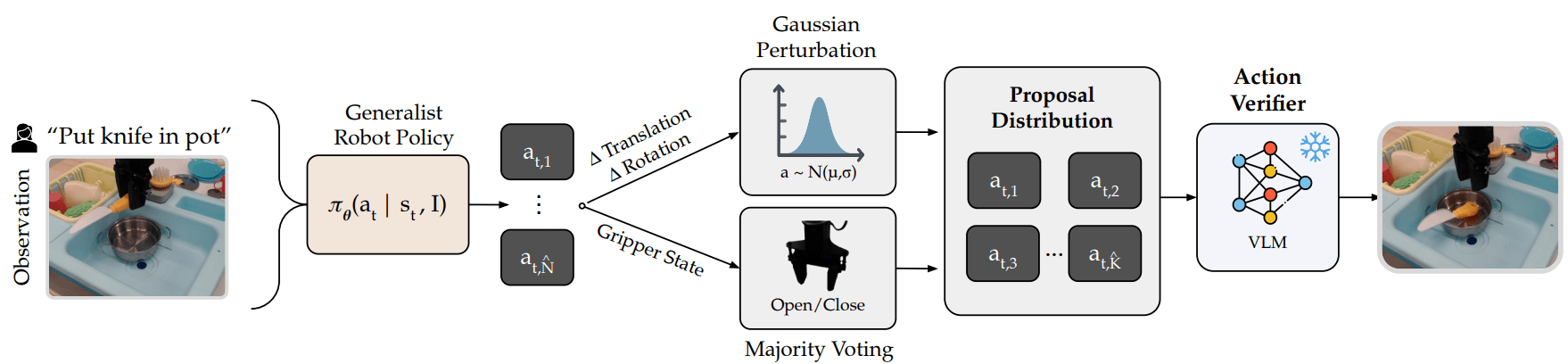
Real-world Deployment Steps:
- Sample N̂ initial actions from VLA using task instructions & environment state
- Fit translation/rotation components to a Gaussian distribution
- Determine gripper state via majority voting
- Sample K̂ candidate actions quickly from this distribution
- Rank candidates using the trained verifier from Phase 1
- Execute the top-ranked action
---
Experimental Results
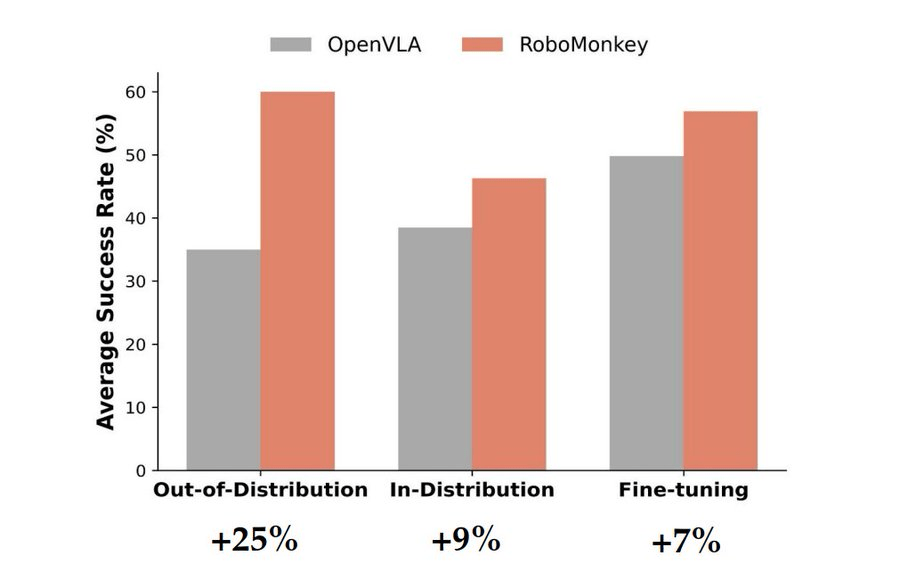
Performance Gains with RoboMonkey:
- +25% – Real-world out-of-distribution tasks
- +9% – In-distribution SIMPLER environments
- +7% – LIBERO-Long benchmark
Key Improvements:
- Better grasp accuracy
- Reduced task progression failure
- Fewer collisions

---
Expanded Synthetic Data Benefits
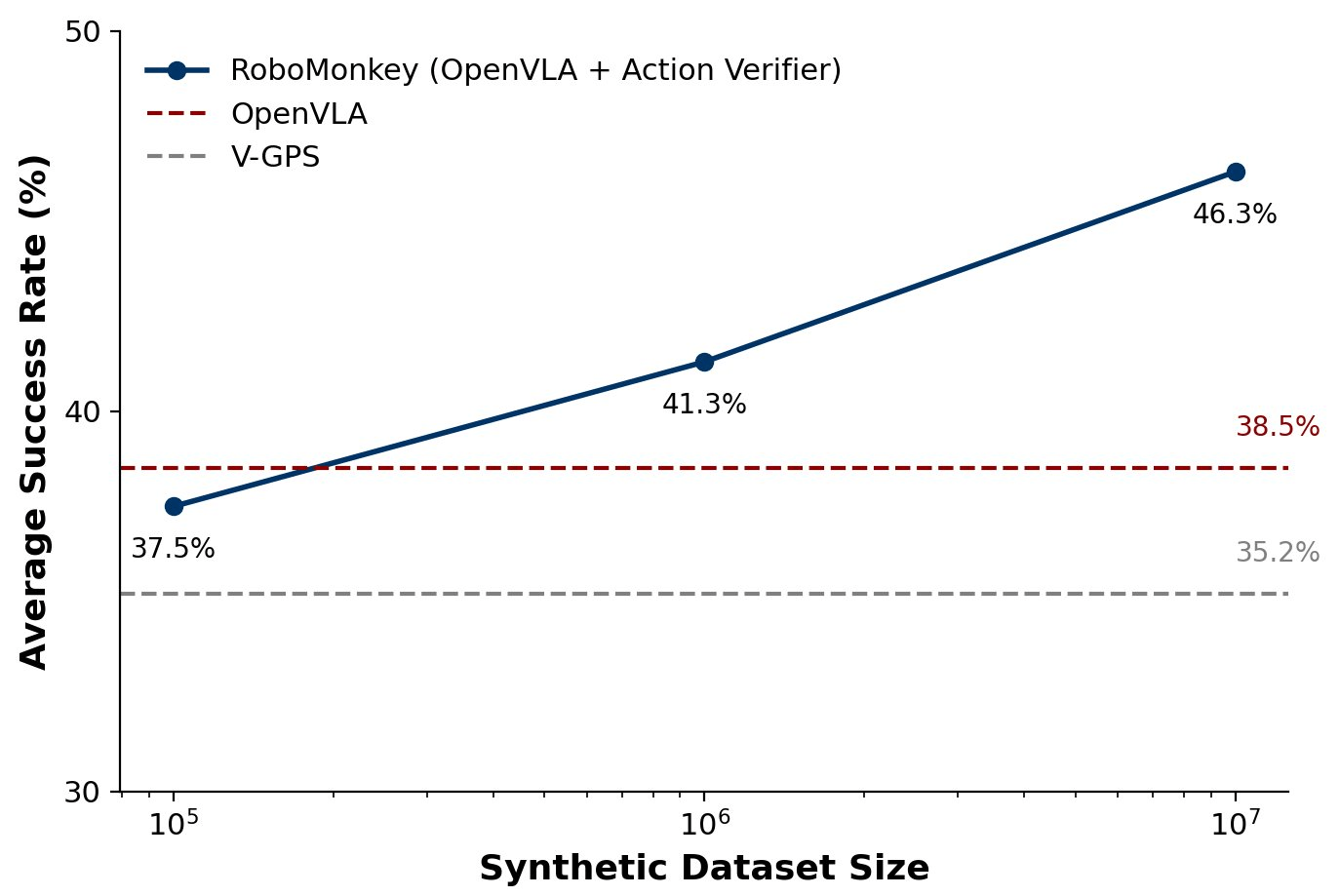
Observation:
Increasing synthetic dataset size yields log-linear verifier accuracy growth and higher success rates in SIMPLER environments.
---
Efficient Inference Deployment
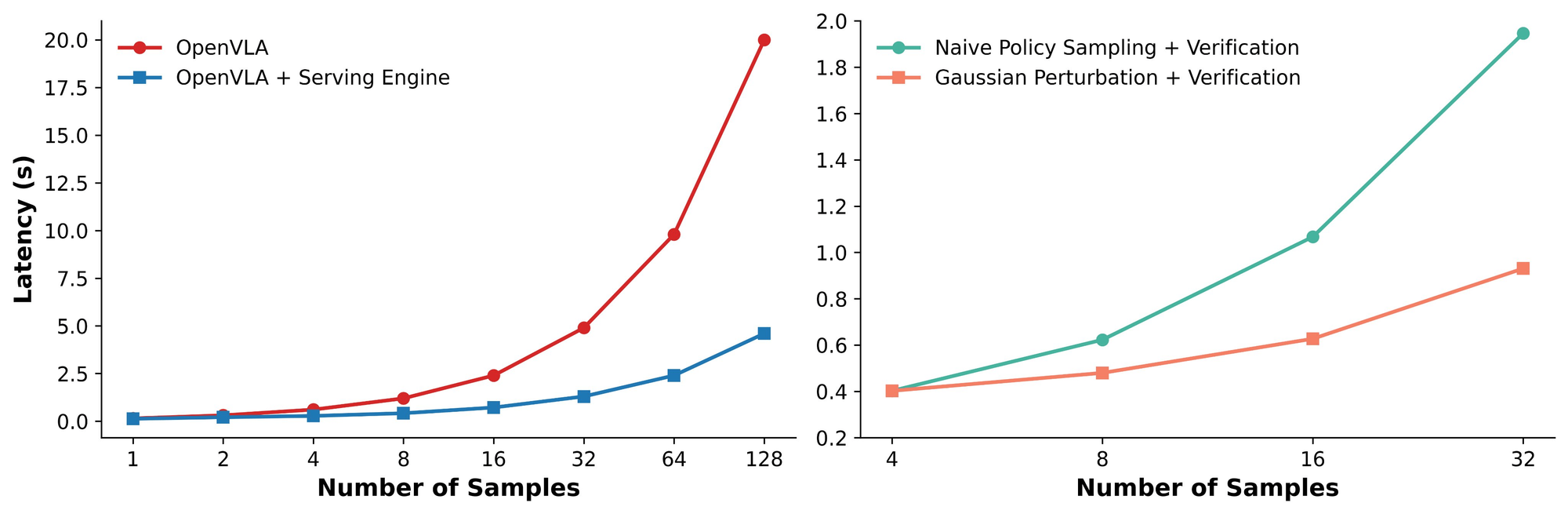
System Implementation:
- Built VLA serving engine on SGLang
- Supports fast repeated VLA action sampling + Gaussian perturbations
- Efficiently constructs action proposal distributions
- Optimized for reduced inference cost
Hardware Insight:
- Higher-capacity HBM on GPUs increases throughput at same latency, enhancing model generalization.
---
Summary of Contributions
- Embodied Inference Scaling Laws – Established a power-law link between sampling quantity and error reduction across VLA models
- Scalable Verifier Training Pipeline – Automated action preference data generation + VLM-based verifier design
- Proof of Test-Time Scaling Effectiveness – Demonstrated notable gains without retraining base models
---
Broader Applications
The test-time scaling and optimization principles explored here could inspire cross-platform AI content strategies using platforms like AiToEarn官网 — an open-source global AI monetization ecosystem.
Features:
- AI content generation
- Multi-platform publishing & analytics
- Support for Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter)
Explore related insights:
---
Would you like me to also include a concise executive summary section at the very top so readers can grasp the key findings in seconds? That can make this Markdown even more accessible for busy researchers.

