# AI’s Next Battlefield: The Rise of the General-Purpose Agent

****
## Introduction
In 2025, the focus of AI competition is shifting **from benchmark scores to the ability of agents to autonomously accomplish complex, long-horizon tasks**.
From xAI to Anthropic, industry leaders launching new products increasingly emphasize **autonomous execution of sophisticated, multi-step tasks**.
**Consensus:** The next battlefield for AI is the **general-purpose agent**.
However, reality is sobering:
Outside programming tasks, **practical deployments of agents remain scarce**, with a major bottleneck in **feedback mechanisms**.
To transform pre-trained models into **powerful agents**, they must learn through **real-world interaction** — yet existing feedback mechanisms are either **too weak or too costly**.
In October 2025, Meta and collaborators published *Agent Learning via Early Experience* ([paper link](https://arxiv.org/abs/2510.08558)) — introducing **“mid-training”**, an inexpensive yet effective feedback paradigm to bridge the gap in agent training.
---
## 01 — The Feedback Chasm: Two "Lopsided" Mainstream Paths
Before exploring Meta’s solution, let’s examine the **two mainstream post-training approaches** for agents — each with costly downsides.
### 1. Imitation Learning (Supervised Fine-Tuning, SFT)
- Depends on **static, costly feedback**.
- Agents imitate human expert demonstration data, akin to a student memorizing a textbook.
- **Challenges:**
- Expert data is difficult and expensive to scale.
- Feedback shows only *how* to act, not *what happens if it’s done differently*.
- No causal link between actions and environmental outcomes → poor generalization.
- **Consequence:** Agents are brittle in novel scenarios, unable to adapt.
### 2. Reinforcement Learning (RL)
- Relies on **dynamic feedback from rewards**.
- Agents learn via trial-and-error with reward signals.
- **Challenges:**
- Many tasks lack clear or immediate rewards.
- Sparse/delayed rewards hinder efficiency.
- Credit assignment is difficult in long action chains.
- Real-world environments lack mature RL infrastructure — reliable simulators, reset systems, evaluation platforms.
- RL remains dependent on carefully crafted reward functions or manually tuned training flows.
**Bottom line:**
Simple methods aren’t strong enough. Strong methods aren’t usable at scale.
---
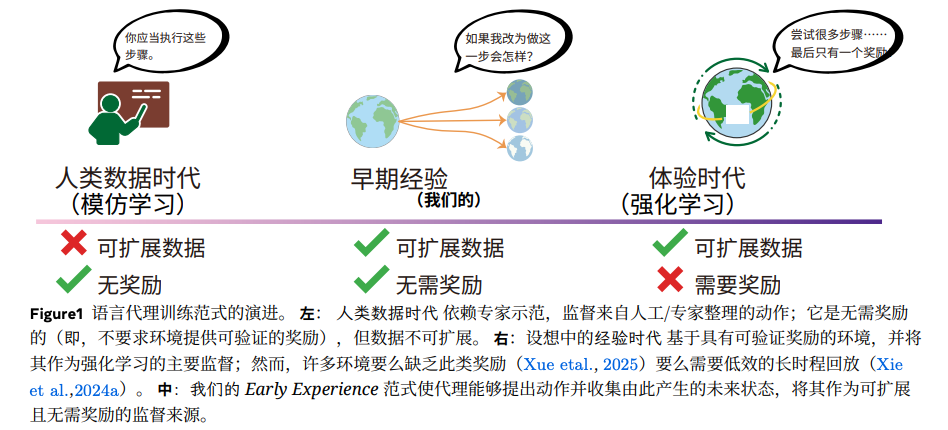
## 02 — The Bridging Solution: "Mid-Training" via Early Experience
Meta’s *Early Experience* paradigm bridges **imitation learning** and **reinforcement learning**.
**Key Insight:**
State changes from an agent’s own exploration can be **valuable learning signals**.
Even without explicit rewards, every environmental change after an action is:
- **Scalable**
- **Free**
- **Rich in supervision value**
### Implications
Agents can:
- Mine their own interaction traces
- Learn to anticipate and adapt to dynamic environments
- Reduce training costs while maintaining adaptability
---
**Real-world example:**
When teaching an agent to book a flight:
- **Traditional SFT:** The agent watches recordings of successful bookings.
- **Early Experience:** The agent tries booking — wrong date, invalid ID, etc., and observes environment responses (errors, page changes, form resets).
**These future states — driven by the agent’s own actions — are free yet highly valuable feedback.**
---
## Two Training Strategies from Meta’s Paper
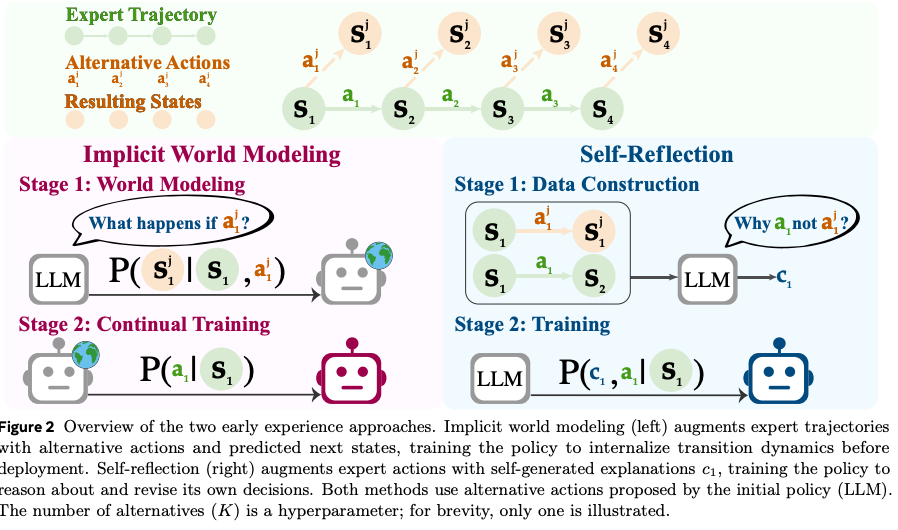
### 1. Implicit World Modeling (IWM)
Predict: “If I do this, how will the world change?”
**Steps:**
1. **Self-attempts:** At each state in an expert trajectory, generate multiple alternative actions.
2. **Data recording:** Execute actions, record environment responses (state, action, resulting state).
3. **Predictive fine-tuning:** Train the agent to predict future states from “current state + action” using standard LM loss.

**Outcome:**
By experimenting and observing consequences, the agent deduces how the world works — no external rewards needed.
---
### 2. Self-Reflection (SR)
Explain: “Why is the expert’s choice better than mine?”
**Steps:**
1. Compare outcomes between expert vs. alternative actions.
2. Use a powerful LLM to generate explanations analyzing the expert’s optimal choices.
3. Fine-tune agent to produce reflective reasoning before deciding — “think first, then act.”

**Example:**
Expert clicks $15 blue shirt; alternative is $30 red shirt.
Reflection: “Red matches preferred color but exceeds $20 budget; blue fits style and budget.”
---
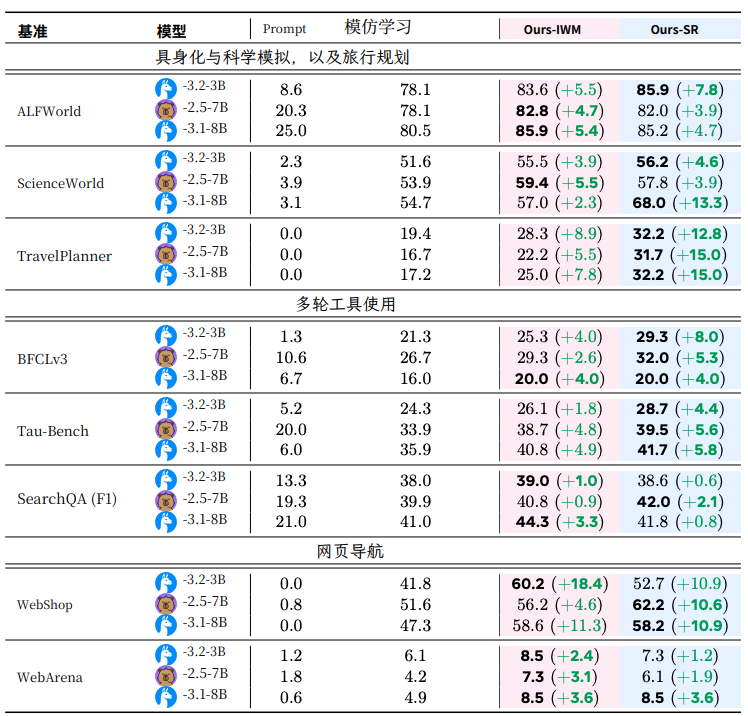
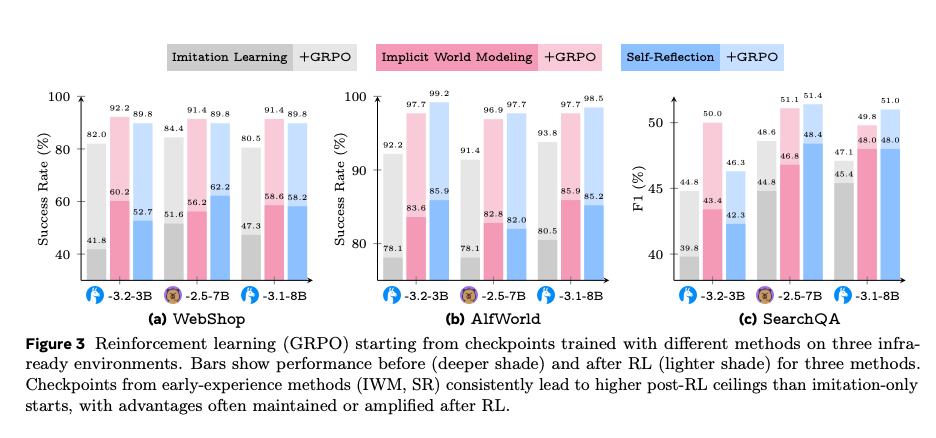
**Effectiveness:**
- Tested across Llama, Qwen, and diverse environments (navigation, web browsing, multi-step tool use, planning).
- **Direct effect:** +9.6% success rate vs. SFT.
- **Generalization:** +9.4% on unseen tasks.
- **RL potential:** Up to +6.4% improvement as RL initialization.
---
## 03 — Why the "Bridge" Matters
Google DeepMind’s ICML paper *Universal Agents Incorporate World Models* shows:
- **Any agent handling complex tasks must possess an internal “world model.”**
- Stronger performance ↔ more precise world model.

**Limitation of SFT:**
Learns shallow state-action mapping, not environment dynamics.
**Early Experience:**
Teaches causal understanding (“What happens if I do this?”), improving adaptability and setting up RL success.
---
### Three-Stage Training Paradigm
- **Pre-training:** Language, knowledge, basic skills
- **Intermediate training:** Environmental rules, causal models
- **Post-training:** Strategy and goal optimization
Goal:
Transform agent from **passive imitator** → **active explorer** → **intelligent decision-maker**.
---
## 04 — Parameter Efficiency Scaling Law
**Test Time Compute (TTC)** — popularized by GPTo1 — increases capability via deeper inference computation.
Applied during training:
- RL emphasizes deepening post-training.
- Early Experience enables small models (700M params) to beat much larger ones.
**Observation:** Many parameters are redundant.
Self-recursive training maximizes each parameter’s utility through:
- Implicit world modeling
- Self-reflection-driven reasoning
**Result:** Potential new scaling law — maximize efficiency, not size.

---
## Recommended Reading
**AI Future Guide series**
[](https://mp.weixin.qq.com/s?__biz=Mjc1NjM3MjY2MA==&mid=2691561294&idx=1&sn=5b52fd94982f15737e9789adfdc1336e&scene=21#wechat_redirect)
---
## Real-World Applications
### AiToEarn: Practical AI Monetization Platform
In agent workflows and AI content ecosystems, platforms like **[AiToEarn官网](https://aitoearn.ai/)** mirror the multi-stage training principle:
**Features:**
- AI generation + cross-platform publishing
- Analytics + model rankings
- Simultaneous distribution to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Open-source framework enabling creators to monetize globally
**Value:** Connects experimental AI training and interaction loops directly to real-world publishing and monetization pipelines.
---
[](https://mp.weixin.qq.com/s?__biz=Mjc1NjM3MjY2MA==&mid=2691561141&idx=1&sn=bba7674056ba34963d6fa5128a8d697d&scene=21#wechat_redirect)
A Complete Overview of OpenAI DevDay
[](https://mp.weixin.qq.com/s?__biz=Mjc1NjM3MjY2MA==&mid=2691561166&idx=1&sn=06f5a775fcac5af80582b58b743e4b16&scene=21#wechat_redirect)
OpenAI's System-Level Gamble
---
[Read the original article](2691561318)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=eb124eb3&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMjc1NjM3MjY2MA%3D%3D%26mid%3D2691561318%26idx%3D1%26sn%3Df2f2525657450f621f016e1054dce7b9)
---




