Surpassing Gemini 3 and GPT 5.1, Alibaba Qwen Tops Global Spatial Reasoning Rankings
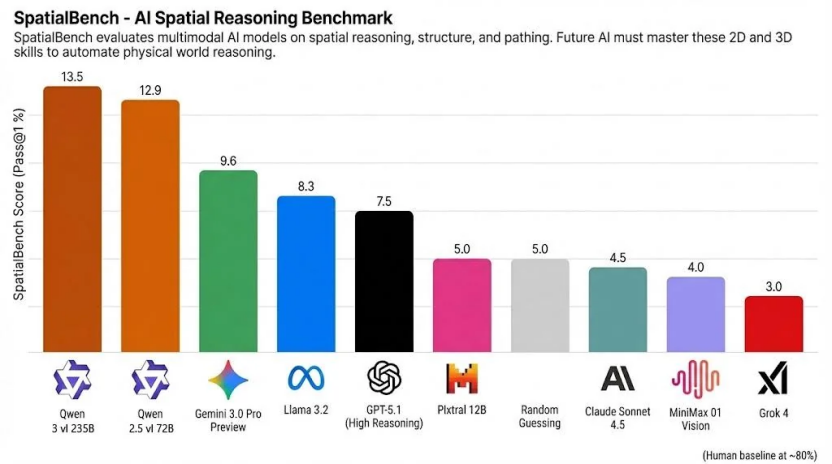
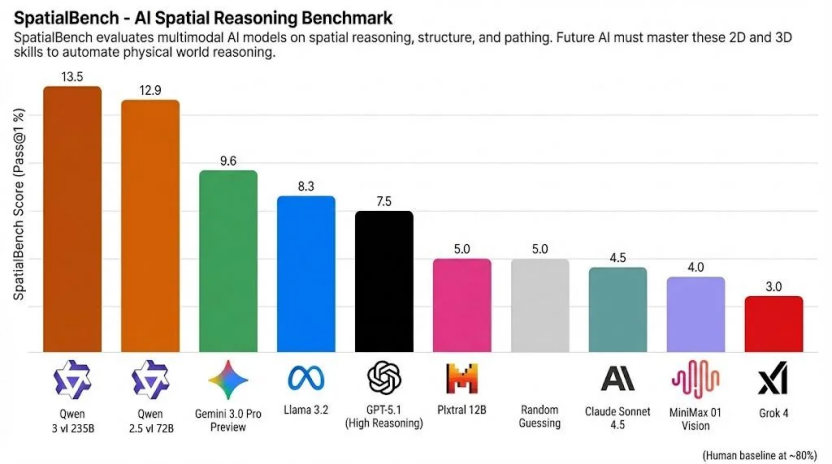
SpatialBench Rankings – November 26 Update
On November 26, the Spatial Reasoning Benchmark (SpatialBench) released its latest rankings, placing Alibaba’s Qwen3-VL and Qwen2.5-VL visual understanding models at the top two spots.
These models outperformed major global competitors such as Gemini 3, GPT-5.1, and Claude Sonnet 4.5.
---
What is SpatialBench?
SpatialBench is a relatively new third-party benchmark focusing on multimodal models’ spatial, structural, and path-related reasoning abilities.
It is recognized within the AI community as an emerging standard for measuring progress in embodied intelligence.
Key Differences from Traditional Evaluations
Unlike tests that mainly measure knowledge recall, SpatialBench evaluates a model’s ability to:
- Perceive spatial relationships
- Manipulate abstract concepts in 2D and 3D space
- Apply reasoning essential for real-world embodied AI applications
---
Ranking Highlights
Top Performers:
- Qwen3-VL-235B — 13.5 points
- Qwen2.5-VL-72B — 12.9 points
Compared to International Leaders:
- Gemini 3.0 Pro Preview — 9.6 points
- GPT-5.1 — 7.5 points
- Claude Sonnet 4.5 — lower than above scores
> 📌 Note: Humans average ~80 points in spatial reasoning tasks, which supports complex professional work such as circuit design, CAD engineering, and molecular biology — areas where large AI models still cannot fully automate expertise.
---
Qwen Model Development Timeline
- 2024 — Qwen2.5-VL was open-sourced
- 2025 — Qwen3-VL launched as Alibaba’s next-generation visual understanding model
---
Qwen3-VL Capabilities
Breakthroughs in Visual Perception and Multimodal Reasoning
- Outperforms Gemini 2.5-Pro and GPT-5 in 32 core capability evaluations
- Integrates tools for image cutout and image-assisted reasoning
- Enables visual programming directly from a design sketch or gameplay video
Enhanced 3D Detection for Robotics
- Accurate spatial perception, including:
- Determining object positions
- Handling viewpoint changes
- Understanding occlusion
- Facilitates precise object retrieval in real-world robotics (e.g., picking distant objects like an apple)

---
Availability & Versions
Qwen3-VL is open-sourced in multiple variants:
Dense Models:
- 2B, 4B, 8B, 32B parameters
MoE Models:
- 30B-A3B
- 235B-A22B
Type Options:
- Instruction-tuned versions
- Reasoning-focused versions
🔹 Widely adopted by enterprises and developers in the open-source visual understanding space.
🔹 Also available for free public use in the Qianwen App.
Benchmark Link:
https://spicylemonade.github.io/spatialbench/
---
AI Content Monetization for Creators
With rapid advancements in models like Qwen3-VL, creators need effective ways to distribute and monetize multimodal AI content.
AiToEarn Platform
AiToEarn官网 offers:
- Open-source, global monetization framework for AI-generated content
- Multi-platform simultaneous publishing, including:
- Douyin, Kwai, WeChat, Bilibili, Xiaohongshu
- Facebook, Instagram, YouTube, Pinterest, LinkedIn, Threads, X/Twitter
- Analytics & Model Rankings: via AI模型排名
This infrastructure ensures innovations in visual reasoning are matched with efficient global distribution and sustainable revenue opportunities for creators.
---
If you’d like, I can create a table comparing Qwen models vs. global leaders based on the ranking scores, which would make the differences clearer. Would you like me to add that?


