linear attention
Linear Attention Regression! Kimi's New Model Explodes, While MiniMax Quietly Switches Back to Traditional Architecture
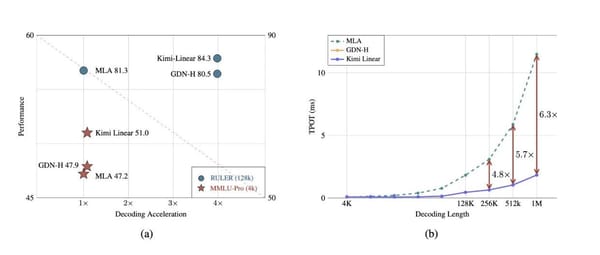
2025‑11‑01 23:49 — Jiangsu --- Overview In the LLM (Large Language Model) domain, linear attention mechanisms are making a notable comeback. This resurgence is largely led by domestic models, driven not only by limited computational resources, but also by a long‑term target—making AI agents more reliable