AI news
Instant Data Exploration with Databricks Assistant in Unity Catalog
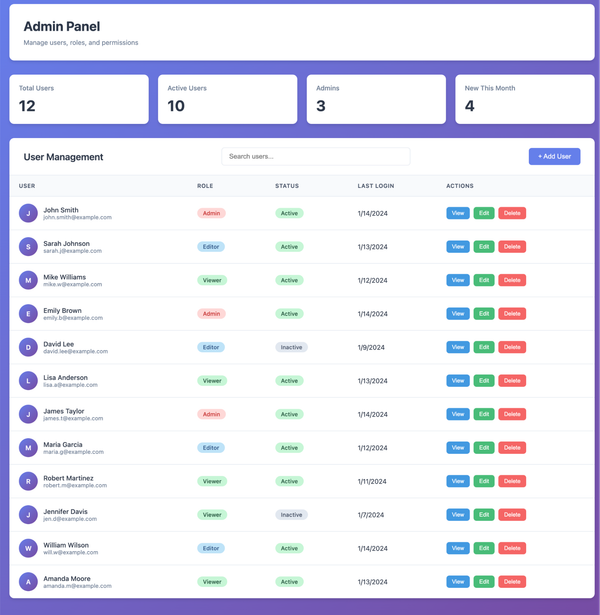
From Dataset Doubt to Instant Insight Every analyst knows the feeling: you open a dataset in your catalog, scroll through the columns, and wonder: “Is this even the data I need?” Until now, answering that meant writing exploratory SQL, checking lineage, or tracking down documentation. With the new Sample Data