reinforcement learning
Tencent Youtu Introduces Training-Free GRPO: Reinforcement Learning for DeepSeek-V3.2 for Just $8
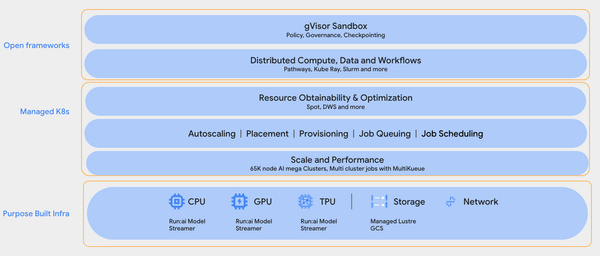
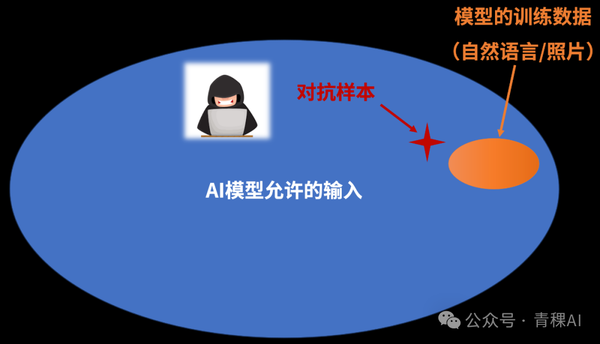
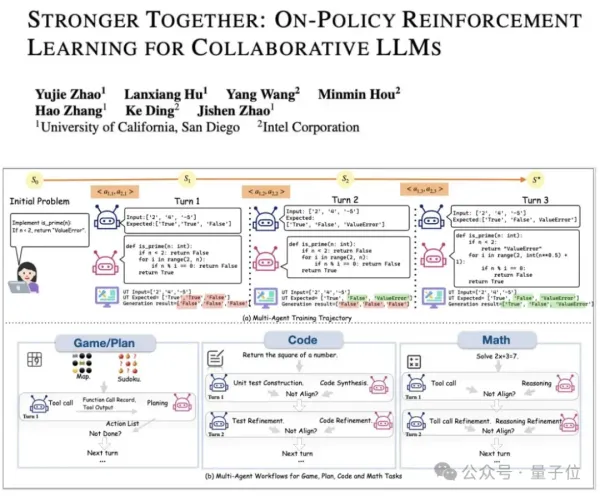
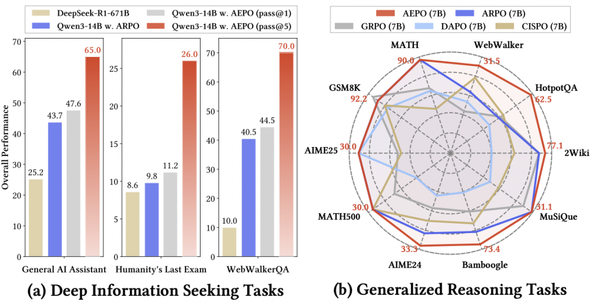
Reinforcement Learning for Ultra-Large Models — at a Fraction of the Cost Richard Sutton — known as the “Father of Reinforcement Learning” and a Turing Award winner — predicts that the next generation of intelligent agents will achieve superhuman capabilities primarily by learning from experience, rather than relying solely on supervised learning with