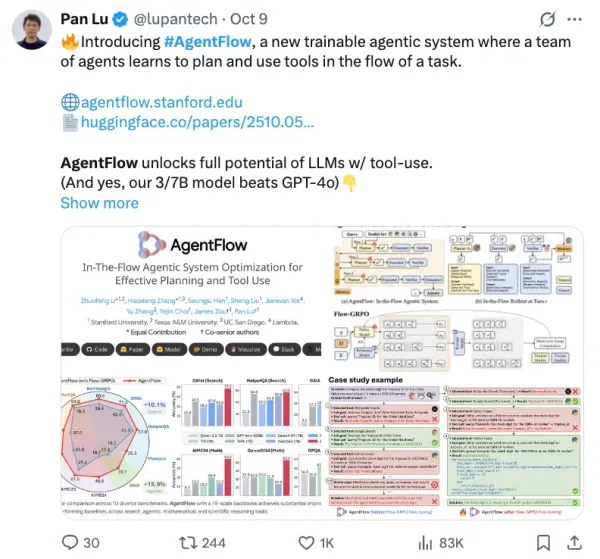
AgentFlow
AI Online Reinforcement Learning “Learn While Doing”: Stanford Team Boosts 7B Model to Surpass GPT-4o
AgentFlow: A New Framework for Adaptive, Multi‑Agent Reasoning Overview Stanford and collaborators have introduced AgentFlow, a paradigm leveraging online reinforcement learning to help agentic systems "achieve more with less" — in some cases surpassing models like GPT‑4o. Core Concept: AgentFlow continuously enhances agents’ reasoning capabilities when tackling