# Advancing Diffusion-Based Large Language Models (LLMs)
Diffusion-based LLMs have progressed rapidly.
- **February 2025** — *Mercury* (Inception Labs) became the first *commercial-scale* diffusion LLM.
- **Renmin University** launched *LLaDA*, the first **open-source 8B parameter diffusion LLM**, followed by *Gemini Diffusion* in May.
These innovations signal that **diffusion LLMs could rival autoregressive models** as the next foundational paradigm for large language models. However, *decoding strategies* and *reinforcement learning* methods for diffusion LLMs remain underdeveloped.
---
## Recent Breakthrough
A research team from **Fudan University**, **Shanghai AI Laboratory**, and **Shanghai Jiao Tong University** published:
> **Taming Masked Diffusion Language Models via Consistency Trajectory Reinforcement Learning with Fewer Decoding Steps**
**Key achievement**:
They introduced an efficient decoding method with reinforcement learning for **Masked Diffusion Large Language Models (MDLMs)**, drastically **boosting reasoning accuracy and speed**.

- **Code Repository:** [https://github.com/yjyddq/EOSER-ASS-RL](https://github.com/yjyddq/EOSER-ASS-RL)
- **Paper:** [https://arxiv.org/pdf/2509.23924](https://arxiv.org/pdf/2509.23924)
---
## Challenge: Why Full Diffusion Decoding Falls Short
Masked Diffusion LLMs (e.g., *LLaDA*) match autoregressive models in capability, while offering:
- **Parallel decoding**
- **Flexible generation order**
- **Potentially fewer reasoning steps**
Yet, **full diffusion-style decoding** underperforms compared to *block-wise decoding*, which has become the standard.
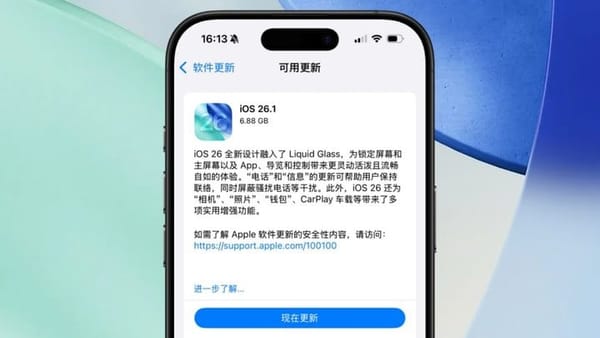
### Key Observations
1. **Token confidence evolution** — slow increase at first, then sharp rise later.
2. **Persistent `` token dominance** — `` confidence stays higher than non-EOS tokens across decoding steps.
3. **Premature `` generation** — leading to early termination in full diffusion decoding.
Block-wise decoding avoids this via segmentation.
---
## Reinforcement Learning Mismatch Problem
Applying RL methods from **autoregressive LLMs** to MDLMs introduces **trajectory mismatches**:
- **In AR models** — causal masking means token probabilities remain consistent between rollout and optimization.
- **In MDLMs** — bidirectional attention changes these probabilities, breaking consistency.
**Current imperfect strategies**:
1. **Prompt masking** — single-step optimization approximation
2. **Full mask denoising** — one-step prediction from blank response
Both cause optimization errors due to mismatch.
---
## Core Problems Identified
### 1. Decoding Trap
- Excessive `` generation early → truncation of output
### 2. Static Step Scheduling Issues
- Confidence is low early & high later
- Using evenly spaced steps wastes early opportunities and misses late-stage efficiency gains
---
## The Proposed Solution Set
The team developed **three integrated techniques**:
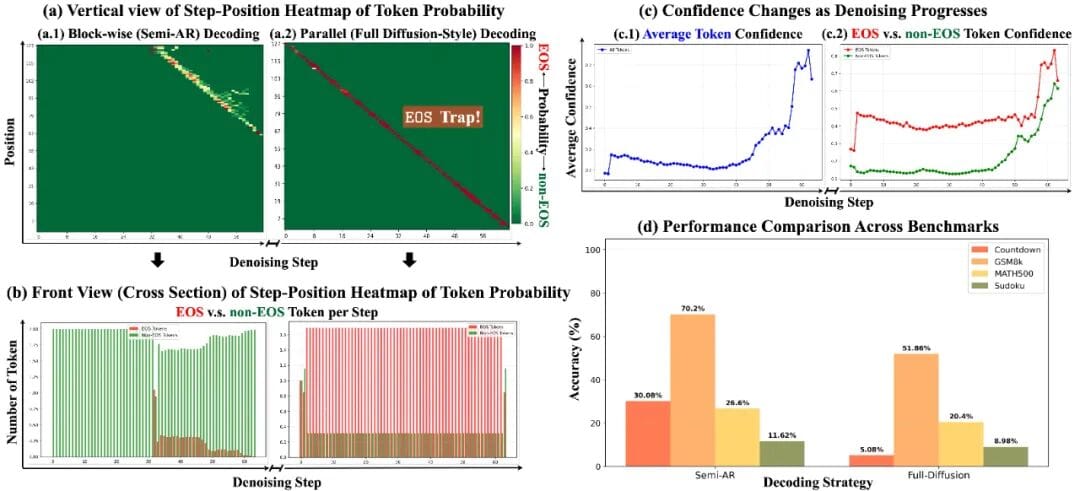
### 1. EOS Early Rejection (EOSER)
- Suppresses `` confidence in early steps
- Gradually restores it later to ensure proper sentence completion
- Improves full diffusion decoding, sometimes beating semi-autoregressive methods
---
### 2. Adaptive Step Scheduler (ASS)
- Uses **exponentially increasing step intervals**
- Small cautious steps when confidence is low → larger steps when high
- Cuts inference complexity from **O(L)** to **O(log L)**

---
### 3. Consistency Trajectory Grouped Optimization (CJ-GRPO)
- Stores intermediate rollout states per decoding step
- Optimizes state transitions step-by-step to reduce mismatch errors
- Combined with ASS to **reduce storage costs** while keeping trajectories consistent
---
## Unified Approach: Synergistic Gains
**EOSER + ASS + CJ-GRPO** yields:
- Smaller training footprint via reduced intermediate state storage
- Comparable (or better) performance with fewer decoding steps
- **Full speed advantage** of diffusion models unlocked
**Training & inference complexity:**
From **O(L)** → **O(log L)**, without performance loss, even with only log L steps.
---
## Experimental Results
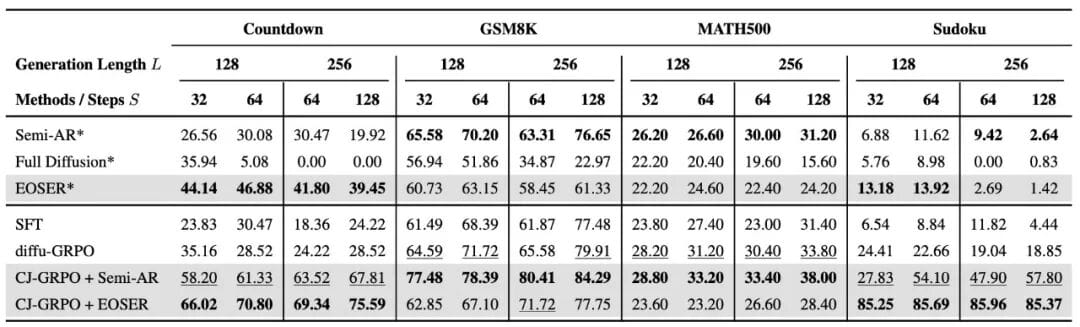
**Benchmarks:**
- **Math reasoning:** GSM8K, MATH500
- **Planning tasks:** Countdown, Sudoku
- Model: **LLaDA-8B-Instruct**
**Highlights:**
- CJ-GRPO exceeded baselines in all tasks
- CJ-GRPO + Semi-AR excelled in math
- CJ-GRPO + EOSER + ASS stood out in planning (2–4× improvement)
- Planning tasks benefited from **parallel inference**; math favored **sequential inference**
---
### Under Log(L) Step Constraint
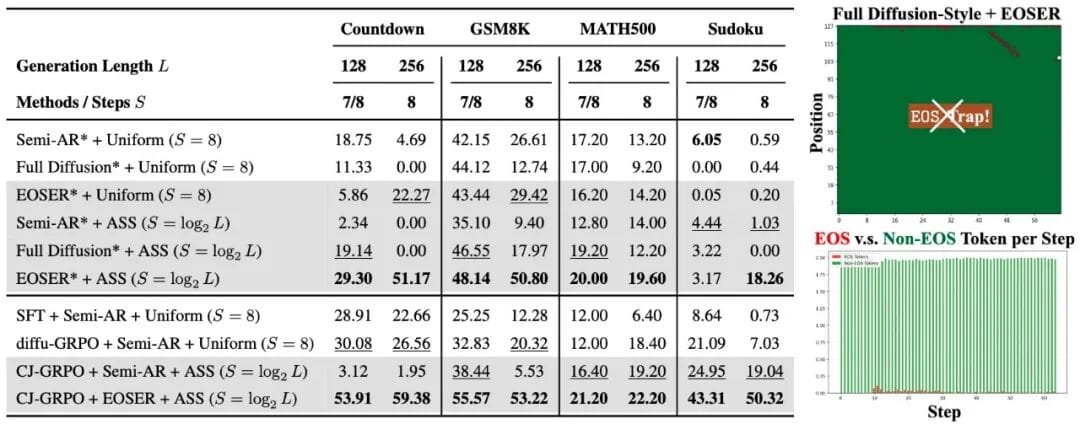
- **EOSER + ASS** outperformed both chunked and full diffusive decoding
- Achieved **“fast and good”** inference — strong results with minimal steps
---
## Significance & Future Outlook
This research pushes forward:
- **Fully diffusive decoding**
- **Low-step decoding efficiency**
- **RL algorithms for MDLMs**
**Task-specific inference insight:**
- **Parallel decoding** → best for **planning tasks**
- **Semi-autoregressive** or **chunked decoding** → best for **math tasks**
**Next step**: Hybrid modes blending diffusion & autoregression to fit different task profiles.
---
## Real-World Impact
Platforms like [AiToEarn官网](https://aitoearn.ai/) can accelerate deployment:
- Open-source AI content monetization
- Multi-platform distribution (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Integrates analytics and model ranking
Coupling **cutting-edge AI methods** (EOSER, ASS, CJ-GRPO) with scalable publishing tools will help bridge research and production — enabling **wide adoption** of advanced diffusion decoding strategies.
---