Tencent HunyuanVideo 1.5 Open Source Release

Tencent HunyuanVideo 1.5 — Lightweight HD Video Generation Model
Release Date: 2025-11-21
Location: Zhejiang
---

Overview
HunyuanVideo 1.5 is Tencent’s newly open-sourced 8.3B-parameter video generation model, designed for 5–10 seconds of HD output. Built on a Diffusion Transformer (DiT) architecture, it can run smoothly even on consumer GPUs with 14GB VRAM.
> Available now in the latest Tencent Yuanbao platform.
---

Usage Modes
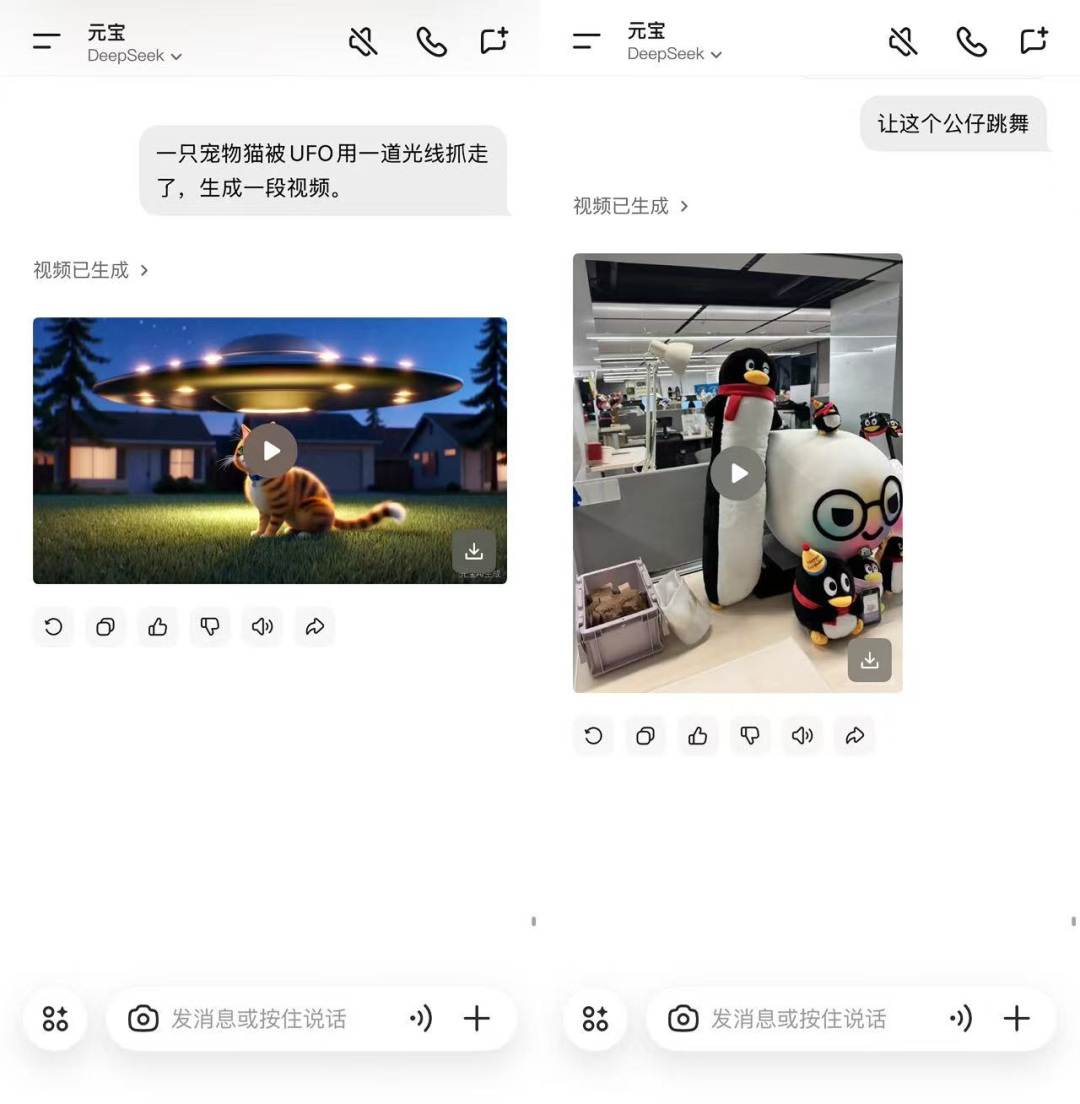
Users can create videos in two simple ways:
- Text-to-Video: Enter a prompt to directly generate a video.
- Image-to-Video: Upload a static image and add a prompt to bring it to life dynamically.
Positioning
- Mini powerhouse: Compact but high-quality.
- Low threshold: Accessible to developers and independent creators.
- Open source innovation: Industry-best results in its size.
---
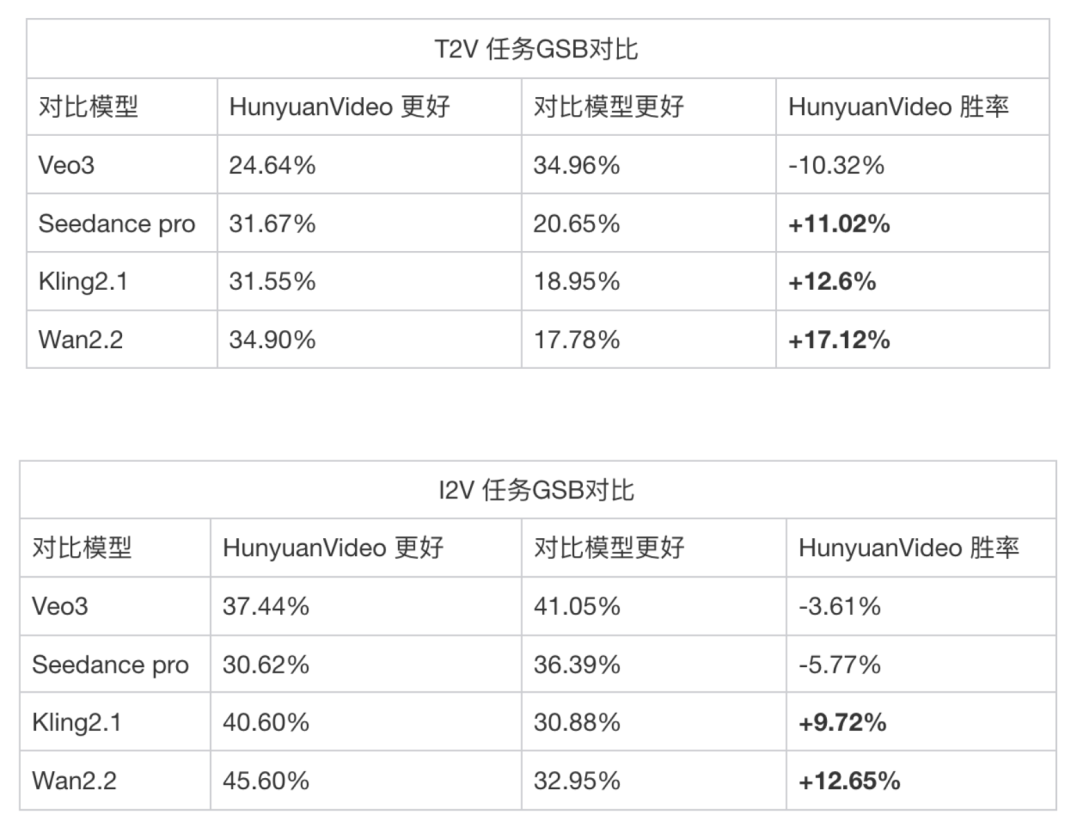
Video Generation Highlights
- Strong Prompt Understanding
- Supports Chinese and English input, interprets complex descriptions through semantic mapping (lighting, color tone, cinematography).
- Continuous Camera Motion
- Enables chained dynamic shots within a 10-second segment.
- Versatile Style Control
- Facial expressions, realistic physics, text rendering, imaginative worlds — broad creative flexibility.
- Smooth Motion Generation
- Produces fluid, realistic human movements and physical object interactions.
- Cinematic Quality Output
- 1080p at 24fps, supporting professional cinematography prompts.
- High Image-to-Video Consistency
- Preserves input image style, tone, and detail in dynamic output.
---
Key Technical Innovations
- Lightweight High-Performance Architecture
- 8.3B parameters in a DiT + 3D causal VAE setup; compression ratio: 16× spatial / 4× temporal.
- Sparse Attention Optimization
- SSTA (Selective & Sliding Tile Attention): Reduces redundant spatio-temporal blocks for faster, cheaper inference.
- Enhanced Multimodal Understanding
- Large multimodal text encoder + byT5 for superior OCR and rendering accuracy.
- Optimized Training Pipeline
- Multi-stage training + Moun optimizer improves motion coherence and user preference alignment.
- Video Super-Resolution System
- Upscales to 1080p with effective distortion correction and detail enhancement.
---
Inference Acceleration
Engineering features:
- Model Distillation
- Cache Optimization
These yield drastically improved inference speed and reduced resource consumption.
---
Hardware Impact
Previous open-source flagship models required:
- ≥20B parameters
- ≥50GB GPU memory
HunyuanVideo 1.5 delivers flagship-level quality with far lower requirements.
---
Example Scenarios
1. Emotion Capture
Prompt:
Person talks to family over the phone with cheerful voice, hiding sadness, tears in eyes. After ending the call, smile fades, sigh, and covers eyes.
---
2. Large-Scale Motion
Prompt:
Figure skater executes Biellmann spin, ice spray, dynamic camera movement, artistic athletic feel.
---
3. Cinematic Camera Control
Prompt:
Tokyo night intersection, high angle wide lens, crowds + neon, zoom into woman lost in thought, melancholic lighting.
---
4. Instruction Following — Text in Scene
Prompt:
Cyberpunk street corner with neon “Hunyuan Video 1.5” sign lighting up sequentially.
---
5. Precise Scene Generation
(Example adheres to textual description exactly.)
---
Monetization with AI Tools
Pair models like HunyuanVideo 1.5 with platforms such as AiToEarn for:
- Generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, etc.)
- Analytics
- AI Model Ranking (Rank Link)
---
Extra Example Prompts
Text-to-Video
Brown suitcase opens to reveal soil; sprouts grow into trees and flowers; miniature English garden appears inside.
---
Image-to-Video — Real/Surreal Interaction
Overhead shot of a printed tree-trunk photo:
- Pinecone placed beside trunk
- 3D squirrel emerges from photo
- Sniffs and takes pinecone back into “hole” in photo.
---
Short Motion Actions
- Puppy pulling lever (camera push-in)
- Person jumps, limbs spread
- Girl puts down book, walks into room (camera pulls back)
- Hot dog & mustard bottle dance together (waltz style)
---
Links & Resources
- Project Homepage: https://hunyuan.tencent.com/video/zh
- GitHub: https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5
- Model: https://modelscope.cn/models/Tencent-Hunyuan/HunyuanVideo-1.5
User Manual:
Demo Files:
---
If you'd like, I can also prepare a clean quick-start guide with Yuanbao integration steps and example prompt syntax for HunyuanVideo 1.5. Would you like me to draft that?


