Tencent Releases Ultra-Low-Cost AI Training Method: $17 Beats $9,700 Fine-Tuning方案

Training-Free GRPO: A Cost-Effective Breakthrough in LLM Optimization
Only 120 RMB — outperforming fine-tuning that costs 70,000 RMB!
Tencent has introduced a new method for upgrading large-model agents: Training-Free Group Relative Policy Optimization (Training-Free GRPO).
Key idea:
No parameter adjustment required — the method leverages brief experiential learning within prompts to achieve highly cost-effective performance gains.

Experimental highlights:
On mathematical reasoning and web search tasks, the DeepSeek-V3.1-Terminus model with Training-Free GRPO showed remarkable cross-domain performance improvements.
Compared with fine-tuning a 32B model, this approach:
- Requires less training data
- Is far cheaper when applied to a 671B LLM
> Comment from netizens:
> So worth it!
---
Background: Limitations of Parameter-Space Optimization
LLMs have evolved into general agents that excel at:
- Complex reasoning
- Web research
- Generalized problem solving
However, in specialized scenarios that require:
- External tools (calculator, APIs, etc.)
- Specialized prompting strategies
…they often underperform due to unfamiliarity with domain-specific requirements.
Challenges with GRPO-based Parameter Tuning
Traditional GRPO applies reinforcement learning to task-specific optimization by updating model parameters.
While effective, this approach struggles with:
- High computational cost
- Poor cross-domain generalization
- Limited training data availability
- Diminishing returns
This raises a key question:
> Can LLM agents be improved non-parametrically, reducing data and computational cost?
---
The Proposed Solution: Training-Free GRPO
Tencent Youtu Lab’s Training-Free GRPO:
- Keeps model parameters frozen
- Uses a lightweight token experience base in context
- Optimizes performance without parameter updates
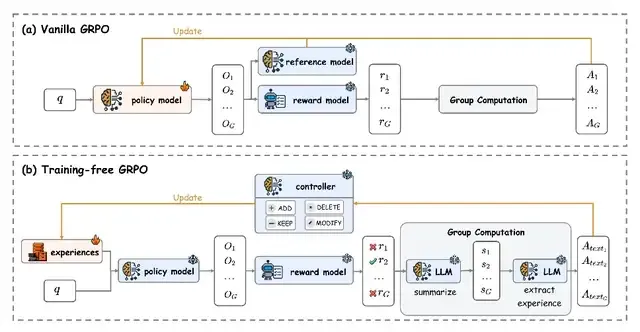
Core concept:
Reuses the relative group evaluation logic of classic GRPO, but shifts it entirely to the inference stage.
---
How It Works
- Frozen Parameters:
- Model parameters (θ) remain fixed — no gradient updates.
- Experience Knowledge Base:
- Starts empty; updated dynamically based on semantic advantages.
- Natural-Language Advantages:
- Generates group-relative performance feedback in plain text.
---
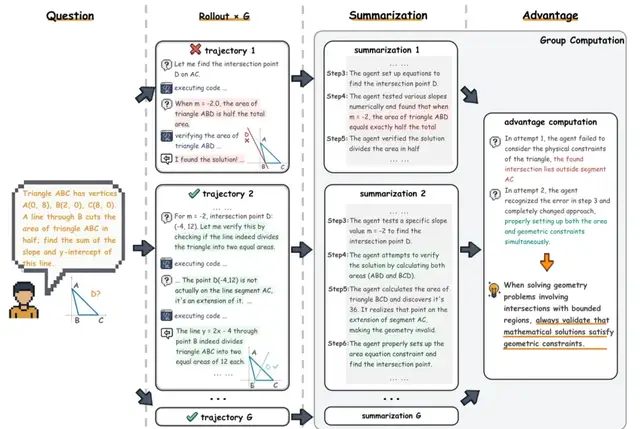
Step-by-Step Process
- Generate Analysis Summary
- For each output, LLM M creates an analysis summary.
- Explain Success/Failure
- Using summaries + current experience, M explains reasons for relative success/failure, then extracts concise experiential knowledge.
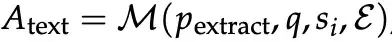
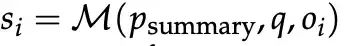
---
Updating the Experience Base
Instead of parameter updates (as in standard GRPO’s gradient ascent), Training-Free GRPO:
- Add: Append experience from `A_text`
- Delete: Remove low-quality experience
- Modify: Improve existing entries
- Keep: Leave base unchanged
This updates the conditional policy by changing the context, not the parameters — guiding the model toward high-reward outputs.
Advantages:
- Natural language acts as optimization signals
- The frozen base model ensures output stability (like KL-divergence in GRPO)
---
Applications Beyond Research
Platforms such as AiToEarn官网 integrate non-parametric optimization methods like Training-Free GRPO into creator ecosystems:
- Multi-platform AI publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analytics and AI model ranking: AI模型排名
- Streamlined content generation, analysis, monetization
This demonstrates how innovations like Training-Free GRPO can bridge cutting-edge AI research with practical creative workflows.
---
Experimental Evaluation
Benchmarks:
- Mathematical Reasoning (AIME24, AIME25)
- Web Search (WebWalkerQA)
Focus: Expensive, challenging-to-fine-tune LLMs like DeepSeek-V3.1-Terminus.
---
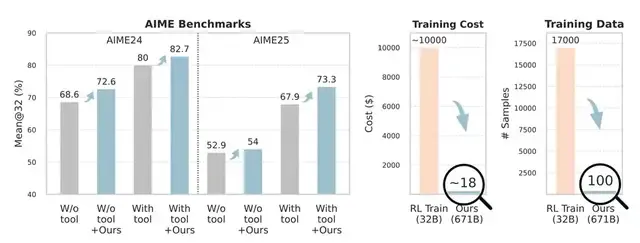
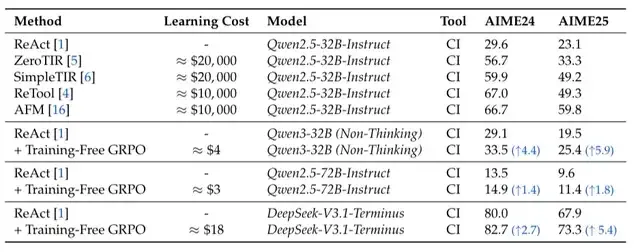
Mathematical Reasoning Results
Baseline: DeepSeek-V3.1-Terminus + ReAct
- AIME24: 80.0%
- AIME25: 67.9%
With Training-Free GRPO:
- AIME24: 82.7% (+2.7%)
- AIME25: 73.3% (+5.4%)
Key point: Achieved with 100 cross-domain samples, no gradient updates, costing only ~$18 — vs. >$10,000 for traditional RL fine-tuning on 32B models.
---
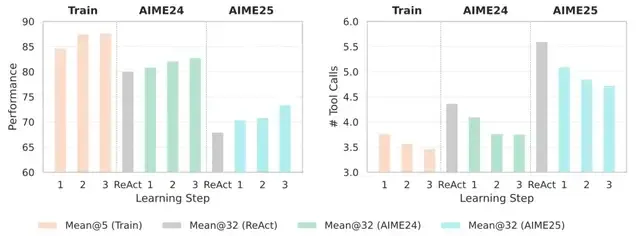
Observations:
- Performance improves with each learning step — even with just 100 problems.
- Reduced tool usage — agents learn shortcuts, avoid redundancy.
---
Web Search Results
Dataset: WebWalkerQA
Pass@1 improvement: 63.2% → 67.8%

---
Ablation Tests (51 sampled instances):
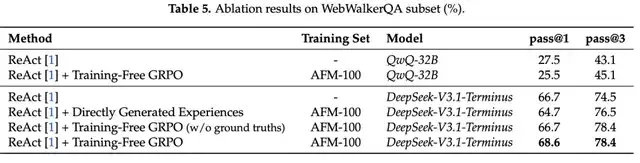
- Adding raw experience context without optimization lowered performance
- Training-Free GRPO (without ground truth) matched baseline Pass@1 but improved Pass@3
- Full method: Best performance (Pass@1: 68.6%, Pass@3: 78.4%)
---
Limitations
Baseline model capability is critical:
On QwQ-32B, Training-Free GRPO scored 25.5% Pass@1 — worse than both DeepSeek-V3.1-Terminus and its own baseline.
This shows the method requires strong reasoning + tool-use capabilities to excel.
---
References
- Paper: https://arxiv.org/abs/2510.08191
- Reference Post: https://x.com/rohanpaul_ai/status/1978048482003890625
- GitHub: https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO
---
> Conclusion:
> Training-Free GRPO significantly improves tool-augmented LLM performance at a fraction of the cost of fine-tuning.
> Its context-driven approach opens new opportunities for research, enterprise, and creator monetization via scalable, non-parametric optimization.
---
Would you like me to also create a flowchart diagram in Mermaid illustrating the Training-Free GRPO process? That could help readers visualize the method quickly.


