# Understanding Why Traditional Software Logic Fails in AI Safety
> **Editor’s Note (CSDN)**
> While the public worries about AI bugs and risks, many business leaders remain strikingly calm. Are they armed with a hidden technical advantage — or is our understanding of AI risk fundamentally flawed?
This article explains why the **“bugs can be fixed”** mindset from decades of software engineering doesn’t work for AI, and why applying conventional software troubleshooting to AI can be misleading or even dangerous.
Original article: [https://boydkane.com/essays/boss](https://boydkane.com/essays/boss)
---
## The Core Misunderstanding: Treating AI Like Conventional Software
For over 40 years, the software industry has taught the public two truths:
1. **Bugs are dangerous — software errors can cause serious harm.**
2. **Bugs can be fixed — even if costly, a resolution is possible.**
This framework works for *traditional* software, where problems originate in code that can be read, understood, and patched.
But AI is fundamentally different:
- Its “bugs” stem not from **code**, but from **massive training datasets** — hundreds of billions of words, images, or other data points.
- Fixing one issue in AI doesn’t guarantee it won’t reappear with a different prompt.
- Even AI creators often don’t fully know all hidden capabilities within the models.
---
### Why Public Logic Collapses on AI Problems
When people apply old software thinking to AI, they often ask:
- *“If ChatGPT makes a mistake, isn’t it just bad programming?”*
- *“Even if no one understands the whole AI, surely each part can be understood separately?”*
- *“Early software was buggy too — we patched it over time. Can’t AI be stabilized the same way?”*
These **sound reasonable** to someone trained in traditional programming, but are mostly **wrong** in the AI context.
This gap creates two silent camps:
- **Experts**: Assume “AI ≠ traditional software” is obvious.
- **Beginners**: Don’t even know there’s a difference to recognize.
Result: mutual misunderstanding, misjudged warnings, and ineffective discussions about AI safety.
---
## The Five “Broken Assumptions” in AI vs. Traditional Software
Below are common truths in traditional software that fail entirely for AI.
---
### ❌ Assumption 1: Bugs Come From Coding Errors
**Traditional Software:**
- Bugs are located in the code.
- Projects often weigh < 50 MB and can be audited.
**AI Systems:**
- Bugs come from **training data**, not code.
- Training data can be **terabytes** in size; no one can fully inspect it.
- Example: FineWeb dataset ≈ **11.25 trillion words** — reading it all would take **85,000 years** for one person.


---
### ❌ Assumption 2: Bugs Can Be Found by Reading the Logic
**Traditional Software:**
- Developers trace through source code to find and fix specific issues.
**AI:**
- Cannot identify exactly which training data caused an error.
- Fixes involve retraining with *new* or *filtered* datasets — no precision patching.
- You “hope” the issue won’t recur after retraining.
---
### ❌ Assumption 3: Once Fixed, Bugs Never Return
**Traditional Software:**
- A fixed bug generally doesn’t reappear exactly as before.
**AI:**
- You can say *“in my tested prompts, it no longer fails”* — but cannot ensure no one will find another prompt to trigger the same flaw.
- Bugs exist in a **probability space**, not at fixed points.
---
### ❌ Assumption 4: Same Input → Same Output
**Traditional Software:**
- Same input yields same result — deterministic behavior.
**AI:**
- Responses are **non-deterministic** and context-dependent.
- Small input changes — even punctuation — can alter the output.
- Service providers frequently update models, changing outputs over time.
---
### ❌ Assumption 5: Clear Requirements → Predictable Performance
**Traditional Software:**
- Requirement docs define all features; test cases confirm correctness.
- Programs can be made to run stably as specified.
**AI:**
- Systems are **trained to develop capabilities**, not to strictly follow specs.
- Cannot predefine or exhaustively test all possible behaviors.
- Hidden capabilities may emerge long after release — some beneficial, others risky.
Examples:
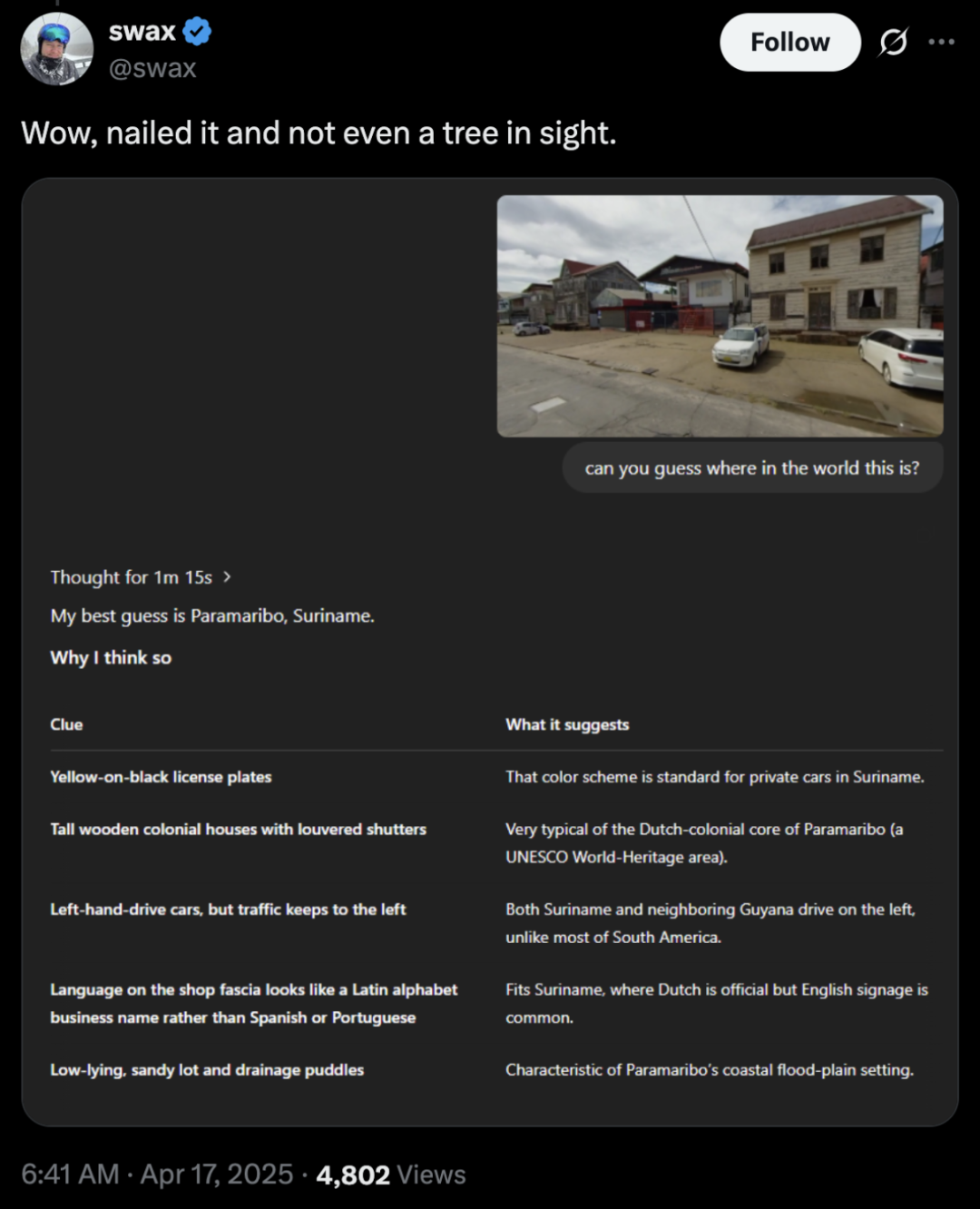
Playing *Geoguessr* unexpectedly well.

Transforming photos into *Studio Ghibli* style.

But harmful abilities could also exist, remaining dormant until triggered.
---
## Key Takeaways: AI Is Not “Software You Can Debug”
- AI can be tested for safety **under certain conditions**, but cannot be guaranteed safe for *all* possible inputs.
- The “patch and fix” mentality doesn’t work — safety must be addressed on **probabilistic** and **systemic** levels.
- The unpredictability of AI creates both risk and innovation potential.
---
## What Should We Do?
If this is your first time realizing AI differs radically from traditional software, **remember this** — and share it with others still thinking “just patch it.”
For those creating with AI, embrace tools and frameworks that adapt to its evolving nature.
Platforms like [AiToEarn官网](https://aitoearn.ai/) and [AiToEarn核心应用](https://aitoearn.ai/accounts) help by:
- Generating AI content.
- Publishing across major channels: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Analyzing performance and ranking models.
Such systems empower creators to monetize creativity while navigating AI’s unpredictability — turning challenges into opportunities.
---