The Road to Rebuilding LangChain Chatbots and Lessons Learned
Background
Every successful platform needs reliable support. We found our engineers were spending hours chasing answers to technical questions—creating a critical bottleneck for users.
We decided to solve this using our own stack: LangChain, LangGraph, and LangSmith. We initially built chat.langchain.com as a prototype with two primary purposes:
- Product Q&A — Provide instant, authoritative answers to product questions for both users and internal staff.
- Customer Prototype — Demonstrate how customers can build sophisticated, reliable agents using LangChain tools.
However, our support engineers weren’t actively using the chatbot. Solving that adoption problem taught us how to build reliable, production-grade agents our customers could adapt.
---
The Challenge
Engineers didn’t avoid Chat LangChain because it was broken—they needed deeper guidance than documentation alone.
Typical workflow when investigating issues:
- Search documentation — (docs.langchain.com) to understand intent.
- Check the knowledge base — (support.langchain.com) to see real-world resolutions.
- Inspect code — Use Claude Code to search and verify the implementation.
> Flow: Docs → Knowledge Base → Codebase.
> Docs provide the official narrative, the KB contains real-world fixes, and code is the ground truth.
We realized the chatbot needed to embed this exact three-step troubleshooting flow.
---
Automating the Workflow
We built an internal Deep Agent with:
- Documentation search agent
- Knowledge base search agent
- Codebase search agent
Each subagent:
- Asks follow-up questions
- Filters irrelevant results
- Passes refined insights to a main orchestrator agent
The orchestrator synthesizes inputs into actionable, verified answers—with citations and exact code lines.
---
Realizing Public Chat LangChain Needed an Upgrade
The public chatbot still used a chunk → embedding → vector search pattern:
- Required constant reindexing when docs changed
- Fragmented context
- Citations often incomplete
Our internal Deep Agent was higher quality, more precise and needed to be public.
---
Designing the New Agent Architecture
Category 1: Documentation & KB Questions
Tool: createAgent — minimal overhead, executes tools fast.
Why:
- No planning/orchestration phase.
- Answers most questions in 3–6 tool calls within seconds.
Models Offered:
- Claude Haiku 4.5 — fastest, high accuracy in tool execution
- GPT‑4o Mini / GPT‑4o‑nano — alternatives
Optimization:
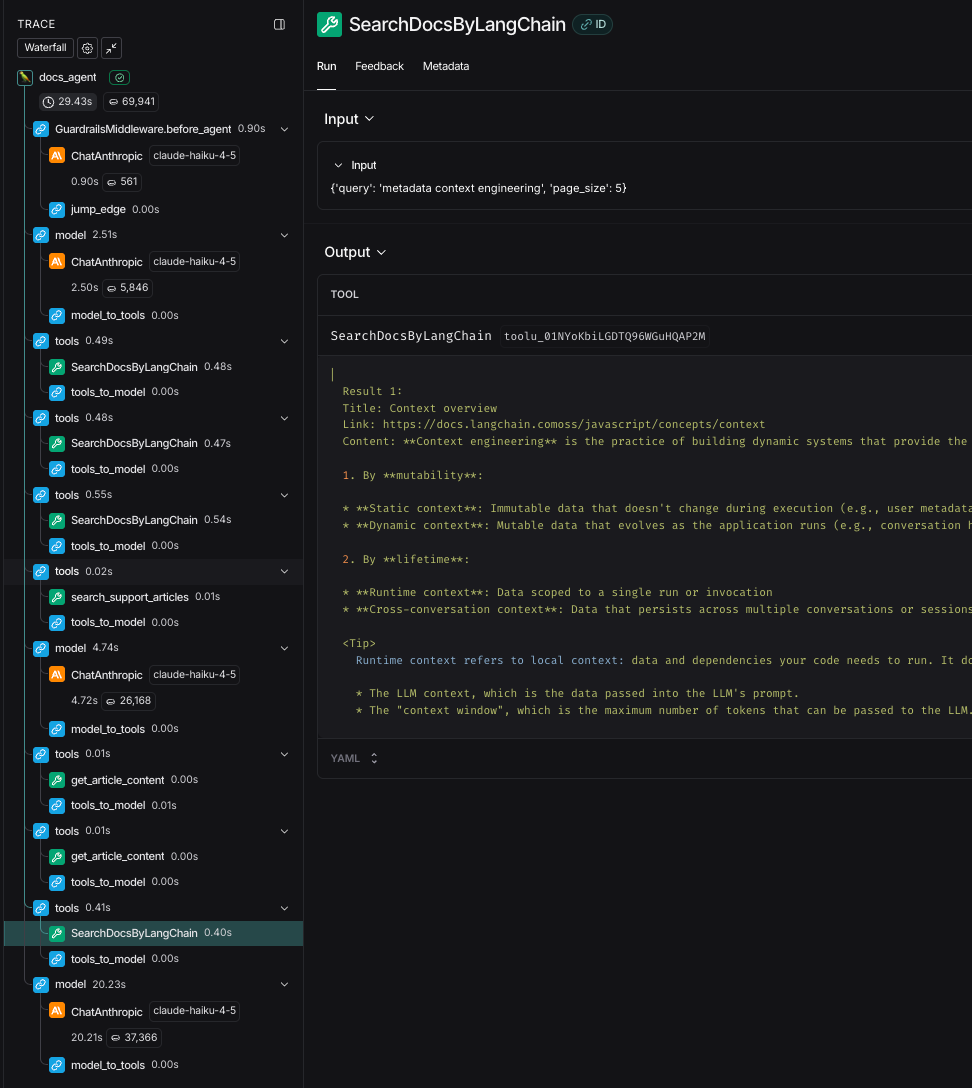
- Used LangSmith to trace conversations
- Reduced unnecessary tool calls
- Improved follow-up prompting
---
Category 2: Codebase Questions
Tool: Deep Agent with domain-specific subgraphs
Subagents:
- Docs search
- KB search
- Code search
Benefits:
- Prevents overload in main agent
- Allows deep digging per domain
Tradeoff:
Slower (1–3 min) for complex queries, but far more thorough.
Initially rolled out to select users.
---
Why We Removed Vector Embeddings for Docs
Embedding-based RAG is great for unstructured content (PDFs), but for our structured docs it caused:
- Broken context from chunking
- Constant reindexing overhead
- Vague citations
Solution: Direct API access to existing structure.
- Full pages from Mintlify API
- Title-first search in KB, then full article read
- Code search via uploaded repos to LangGraph Cloud + `ripgrep`
---
Smart Prompting for Human-Like Search
Instead of similarity scores, the agent searches like a human:
- Broad keyword search
- Evaluate results critically
- Refine search terms until the right context is found
Iterative process encourages “active research” rather than passive retrieval.
---
Tool Design Highlights
Docs Search (Mintlify)
Returns full pages with headers, subsections, examples.
@tool
def SearchDocsByLangChain(query: str, page_size: int = 5, language: Optional[str] = None) -> str:
"""Search LangChain documentation via Mintlify API"""
params = {"query": query, "page_size": page_size}
if language:
params["language"] = language
response = requests.get(MINTLIFY_API_URL, params=params)
return _format_search_results(response.json())---
KB Search (Pylon)
Two-step:
- Scan titles
- Read selected articles in full
@tool
def search_support_articles(collections: str = "all", limit: int = 50) -> str:
"""Get article titles to scan"""
...
@tool
def get_article_content(article_ids: List[str]) -> str:
"""Read the most relevant articles"""
...---
Code Search
Three tools:
- Search patterns (`ripgrep`)
- List directories (file structure)
- Read files (exact lines)
@tool
def search_public_code(pattern: str, path: Optional[str] = None) -> str:
...---
Managing Context Overload with Subgraphs
Before: Single agent saw all raw results → too much noise.
Now: Each subagent returns only golden data to orchestrator.
Benefits:
- Precision
- Reduced irrelevant details
- Cleaner synthesis
---
Production-Ready Infrastructure
Added middleware:
middleware = [
guardrails_middleware,
model_retry_middleware,
model_fallback_middleware,
anthropic_cache_middleware
]Handles:
- Off-topic filtering
- API retries
- Model fallback
- Response caching
---
Delivering to Users
Thread Handling:
const userThreads = await client.threads.search({
metadata: { user_id: userId },
limit: THREAD_FETCH_LIMIT,
})Streaming Responses:
const streamResponse = client.runs.stream(threadId, "docs_agent", {...})Modes:
- messages — progressive tokens
- updates — live tool calls
- values — final state
---
Results
- Sub-15-second answers with Create Agent for docs/KB
- Immediate reflection of doc updates
- Precise citations with verifiable links
- Engineers use Deep Agent for complex tickets → hours saved
---
Key Takeaways
- Automate proven user workflows
- Vector embeddings not ideal for structured content
- Direct structured access yields better citations/context
- Mirror human reasoning patterns in tool/agent design
- Use Deep Agents + subgraphs to manage multi-domain context
- Infrastructure (middleware) matters for production reliability
---
What’s Next
- Public codebase search — Direct repo verification + line citations
---
Try It
Visit chat.langchain.com and test models:
- Claude Haiku 4.5 (fastest)
- GPT‑4o Mini
- GPT‑4o‑nano
---
Join the Conversation
---
Bottom line: Whether debugging code, answering product questions, or scaling content workflows, combining well-designed agent architectures with human-like reasoning and direct access to structure yields faster, more accurate, and verifiable responses—ready for both internal users and public audiences.