The Ultimate Open-Source 0.9B OCR Model — Local Agents and Knowledge Bases Saved

PaddleOCR-VL: A Lightweight Multimodal Document Parsing Model That Can Run Anywhere
It feels like this could run right on a phone — with full privacy.

Baidu has quietly released and open-sourced a new multimodal document parsing model: PaddleOCR-VL.
Why It Stands Out
The first thing that caught my attention:
Parameter size — only 0.9B.
This small size means very low computing requirements — potentially small enough for smooth execution even on a smartphone.
For anyone building AI solutions for local environments or resource-constrained devices, this is great news.
---
The OCR Problems It Could Solve
From my past AI projects, many OCR tools struggle with:
- Reading order errors in multi-column layouts (newspapers, journals, magazines) — resulting in nonsensical merged text.
- Table parsing issues — clean tables often become scattered text, losing all structure.
- Formula recognition failures — math formulas turn into meaningless garbled text.
This is why every new OCR tool makes me both excited and skeptical.
---
First Tests With PaddleOCR-VL
I tried it immediately:
Surprisingly, the 0.9B model delivered strong, accurate output.
Examples:
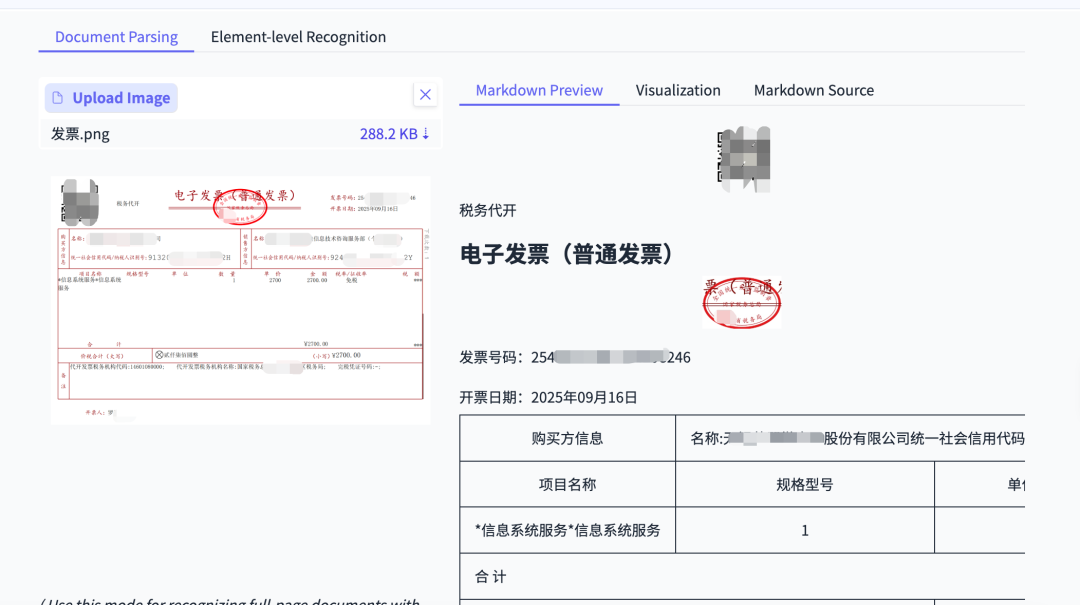
- Invoice recognition (September invoice → clean, complete table)
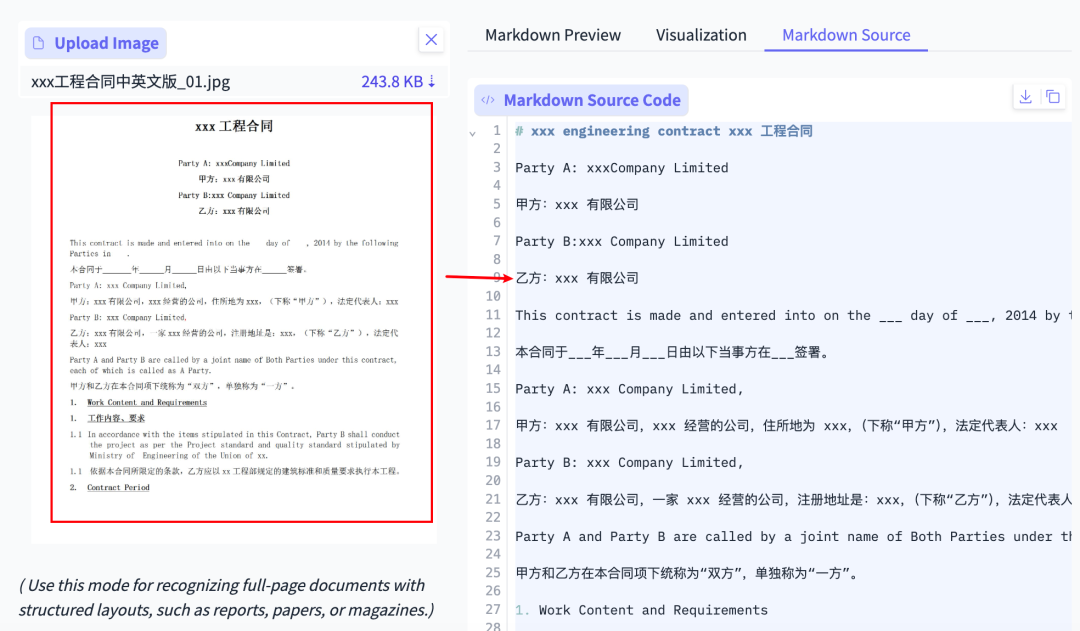
- Bilingual contract recognition

- Chart analysis (bar & line charts → Markdown data)
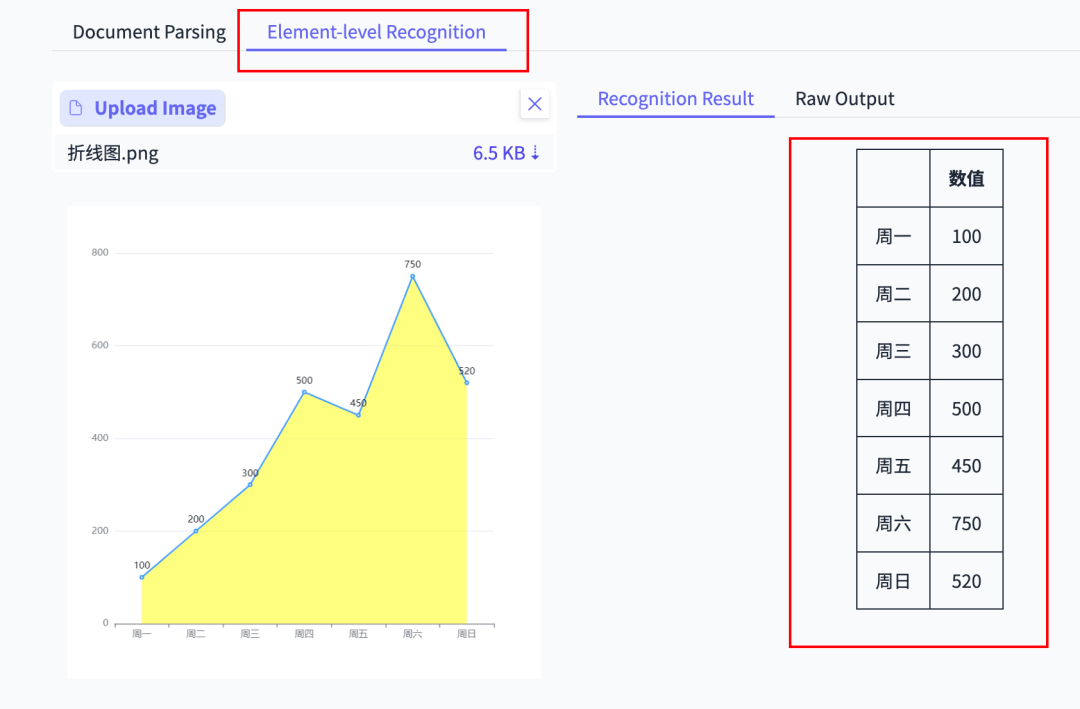
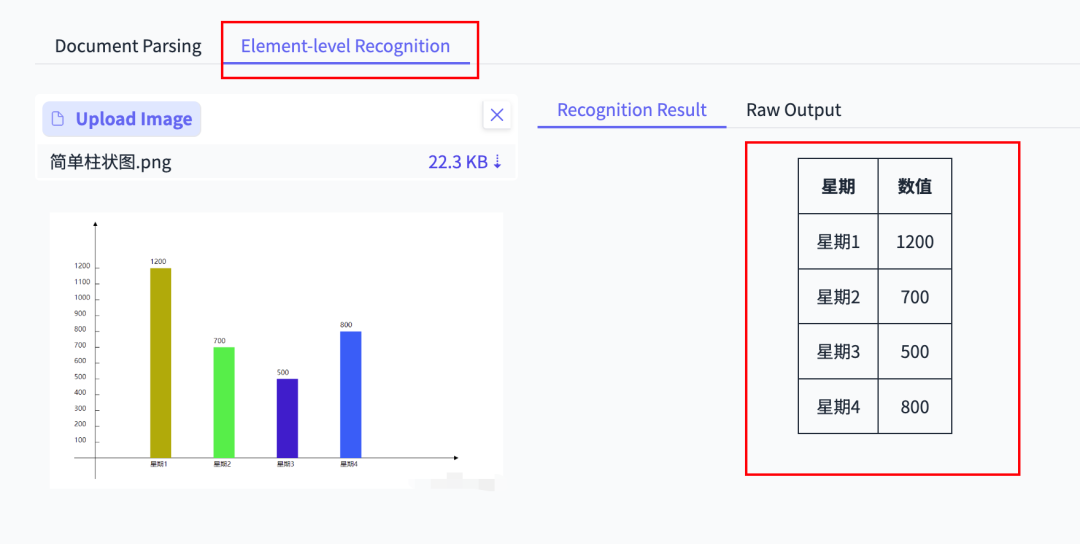
---
What Exactly Is PaddleOCR-VL?
- Developed by Baidu’s PaddleOCR team under PaddlePaddle AI framework.
- PaddleOCR is China's most popular OCR project — over 57.2K GitHub stars, 9M+ downloads, used in 5.9K+ open-source projects.
- GitHub: PaddleOCR
PaddleOCR-VL combines advanced OCR experience with large-model multimodal capabilities.
- Based on ERNIE-4.5-0.3B language model.
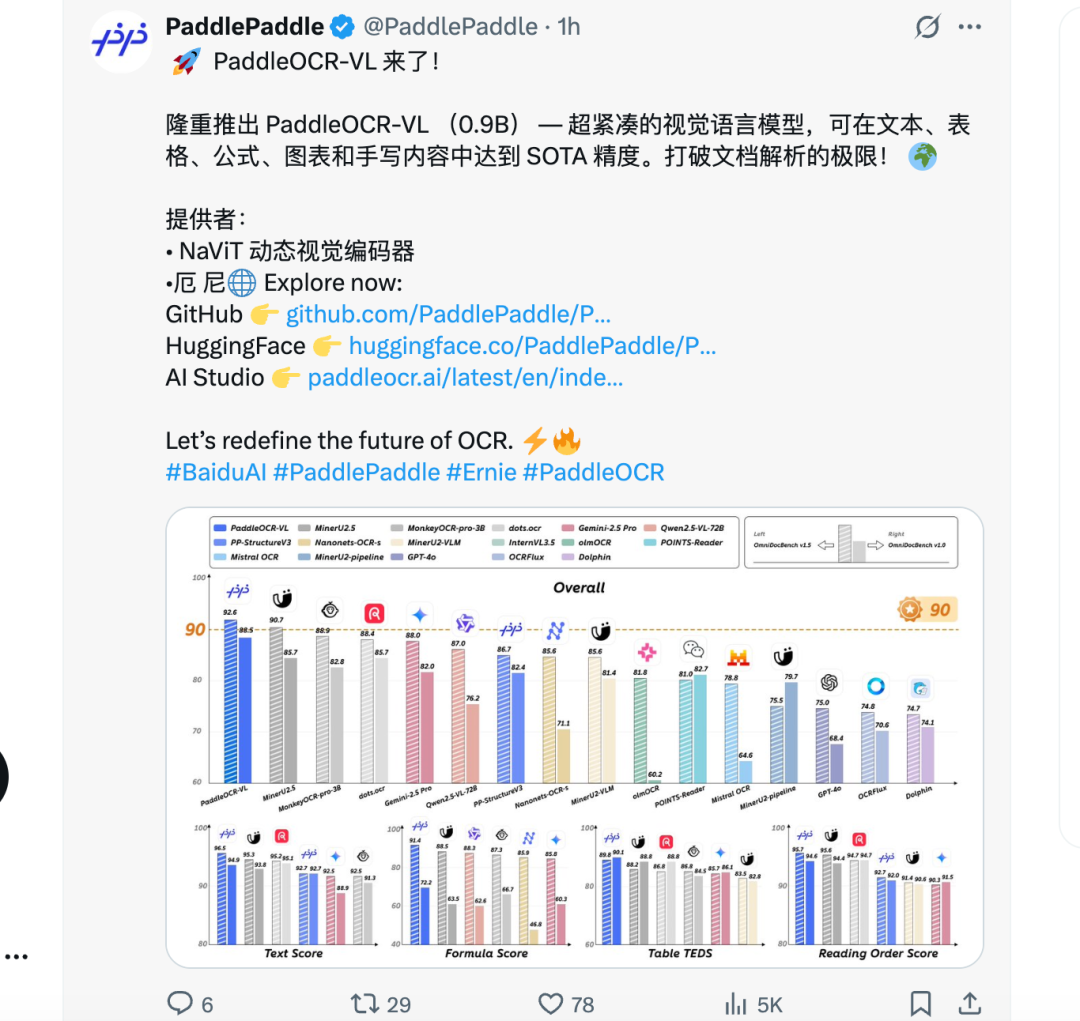
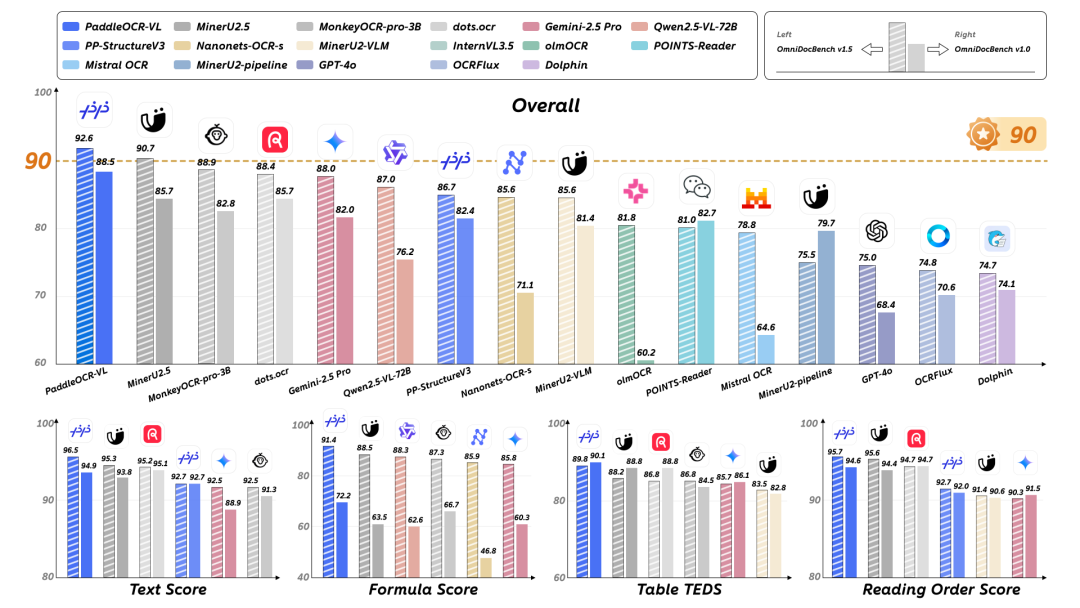
- On OmniDocBench V1.5, it ranked #1 globally — beating GPT‑4o and Gemini‑2.5 Pro.

---
Why It Matters for Creators & Developers
A compact, powerful OCR+multimodal model enables:
- Mobile / Edge AI deployments
- Offline privacy-focused AI agents
- Integration into publishing workflows
For example, platforms like AiToEarn官网 let you:
- Generate AI content
- Publish simultaneously across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Monetize efficiently
Imagine PaddleOCR-VL feeding recognized tables, charts, or contracts directly into an AiToEarn-powered distribution workflow.
---
Global Benchmark Leadership
OmniDocBench V1.5 — developed by OpenDataLab, Tsinghua University, Alibaba DAMO Academy, Shanghai AI Lab —
is one of the most comprehensive document visual-language evaluation standards.
Top models use it for official benchmarking.
PaddleOCR-VL now tops the HuggingFace Trending chart globally.

---
Quick Links to Resources
- HuggingFace Model: PaddleOCR-VL
- Technical Blog: ERNIE Blog
- Technical Paper: arxiv.org PDF
- HuggingFace Demo: Online Demo
- Official Demo: AI Studio


---
Test Highlights
Medical Report Recognition

Accurately extracted structured tables from complex hospital lab reports — with consistent outputs across runs.
---
Historical Book OCR
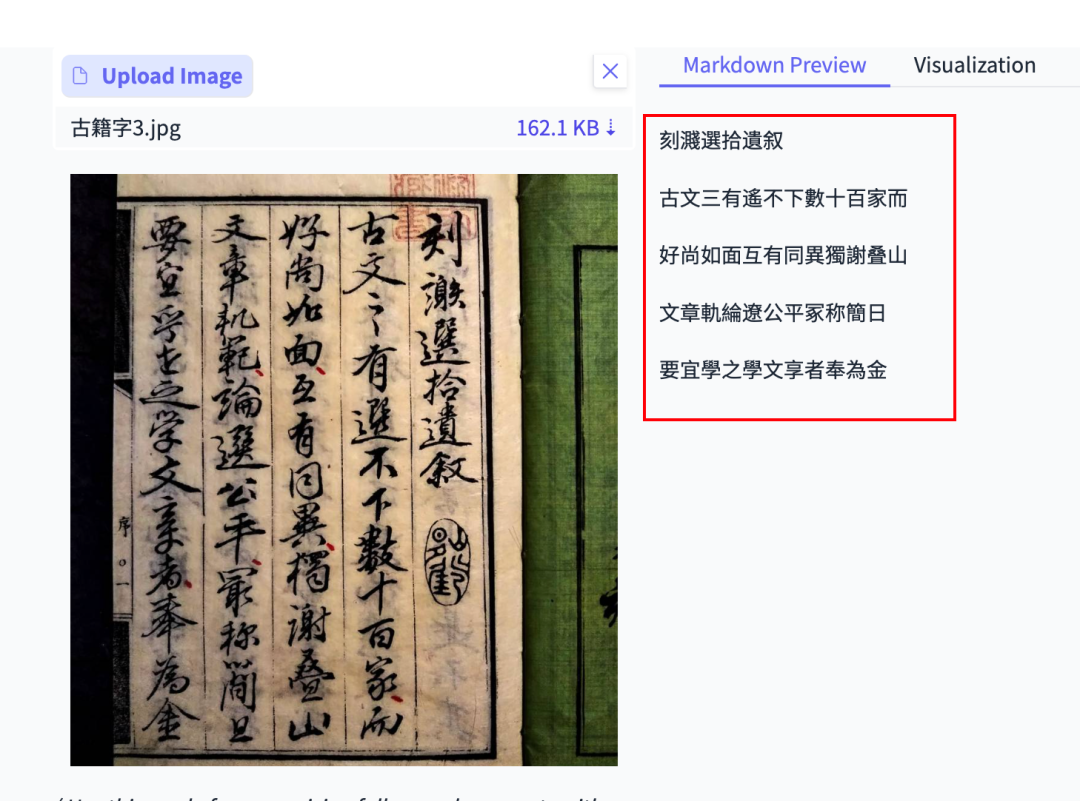
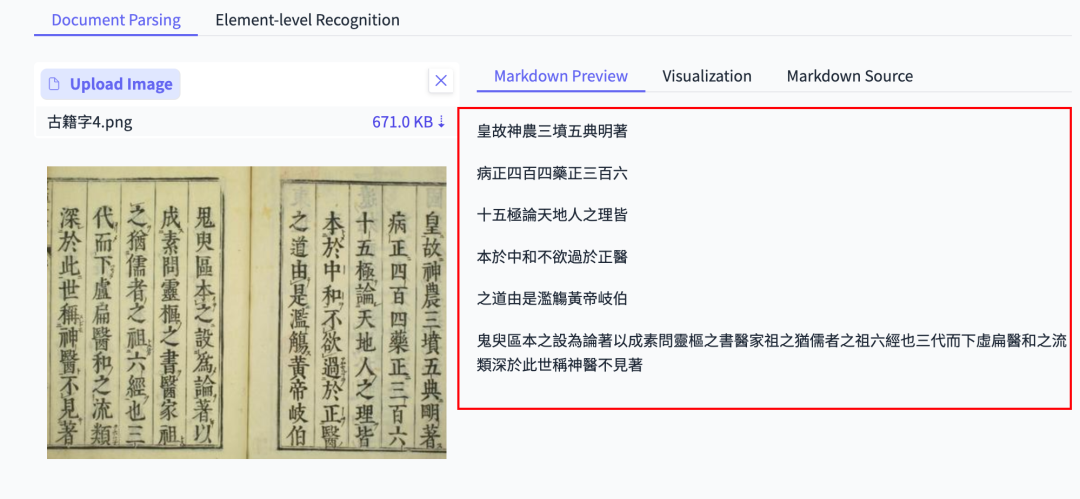
Perfect reading order for vertical right-to-left text.
---
Complex Formula Recognition
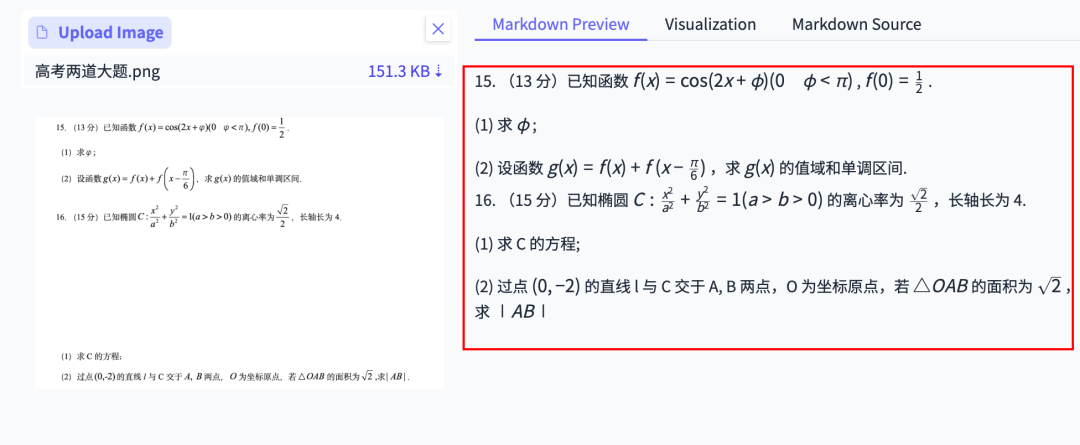
Recognized and converted formulas to LaTeX, including diagrams as base64 images in Markdown — ideal for problem-solving integration.
---
Multilingual Menu Parsing


Strong multilingual detection capabilities.
---
Chart & Table Extraction
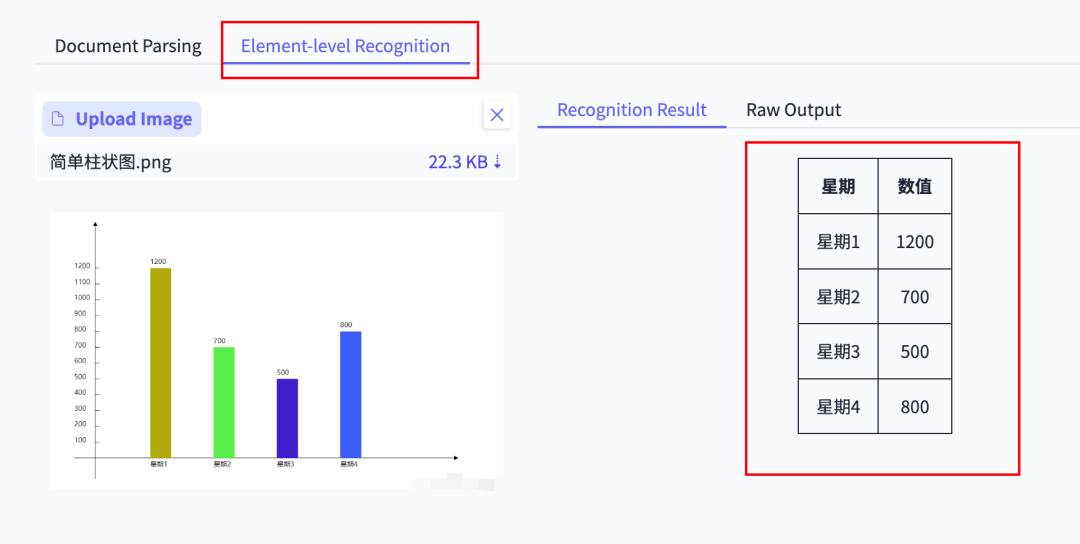
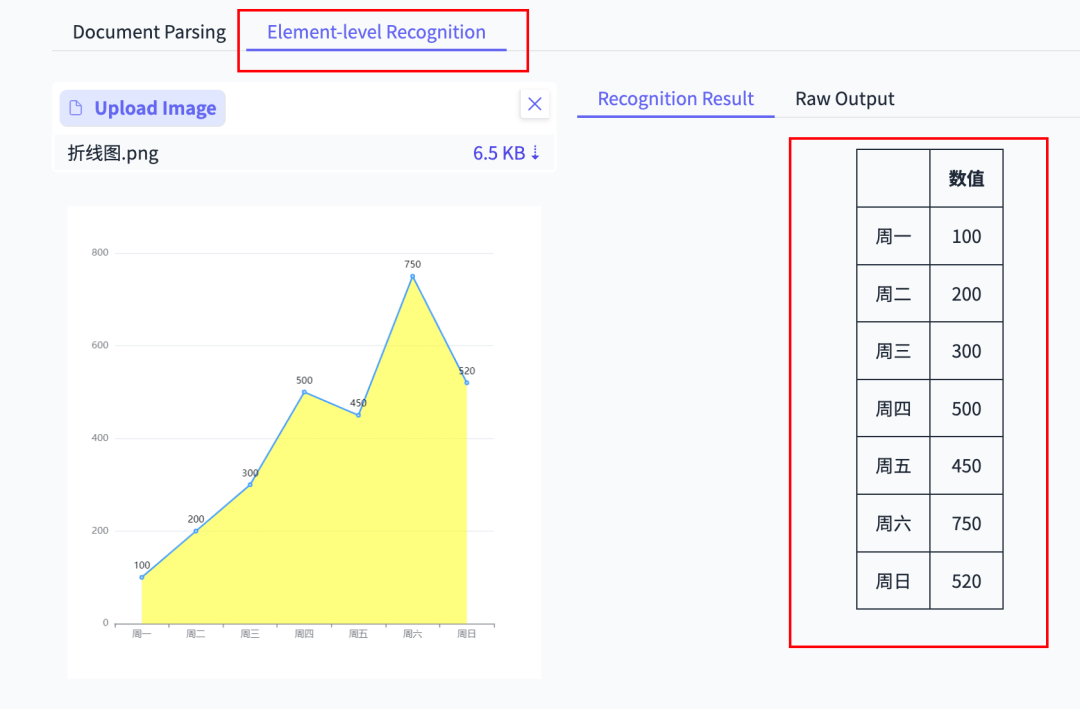
Produces full Markdown tables from screenshot data — rare ability among OCR tools.
---
Offline Deployment Potential
With 0.9B parameters, PaddleOCR-VL can run fully locally, meeting strict data security requirements and enabling:
- Legal teams: extract clauses from confidential contracts on internal servers.
- Remote fieldwork: process dashboard images locally on tablets without internet.
---
Technical Architecture

Two-stage divide-and-conquer design:
- Layout Detection — PP-DocLayoutV2 scans and detects text, tables, formulas, keeps reading order.
- Content Recognition — Batch process small framed regions in PaddleOCR-VL-0.9B.
- Merge outputs → structured Markdown and JSON.
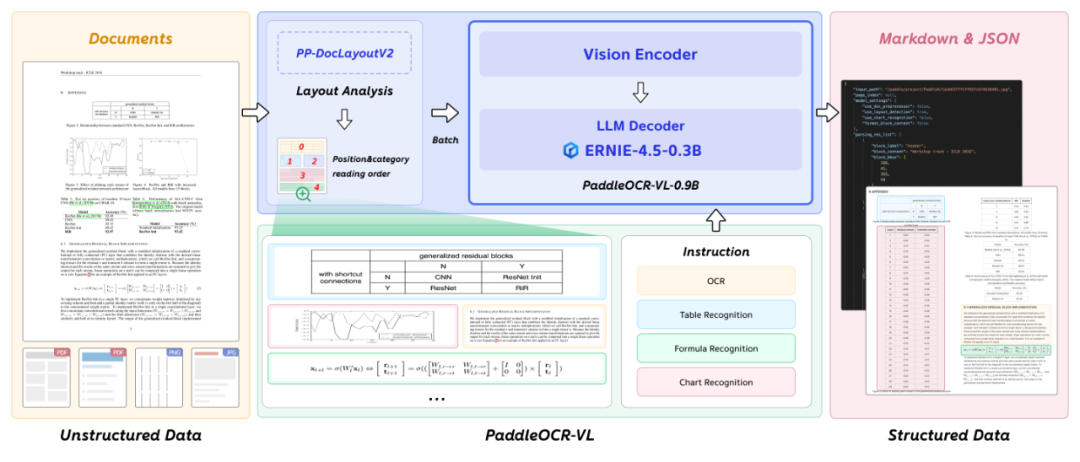
This separation improves accuracy, stability, and speed over all-in-one large models.
---
Final Thoughts
PaddleOCR-VL is practical, high-accuracy, stable, and lightweight — exactly what local knowledge bases and AI agents need.
It can output structured, machine-readable formats from images or PDFs — making it perfect for end-to-end workflows, especially when paired with publishing automation tools like AiToEarn官网.
---
Next Step: If this article reaches 8,000+ reads — I’ll post a guide for local deployment, integration with FastGPT and n8n, to strengthen your private Agents.
Conclusion: Open-sourcing PaddleOCR-VL unlocks complex document processing for individuals and enterprises — at low cost, high accuracy, and full offline capability.
⭐ Like / Bookmark / Share if useful.
Stay tuned for the local deployment tutorial.
---



