Thinking Machine's New Study Goes Viral: Combining RL + Fine-Tuning for More Cost-Effective Small Model Training
Thinking Machine’s Breakthrough: On-Policy Distillation for Efficient LLM Training
Thinking Machine’s latest research is generating intense discussion in the AI community.
After being personally reposted by Mira Murati — founder and former OpenAI CTO — many prominent figures praised its research value:
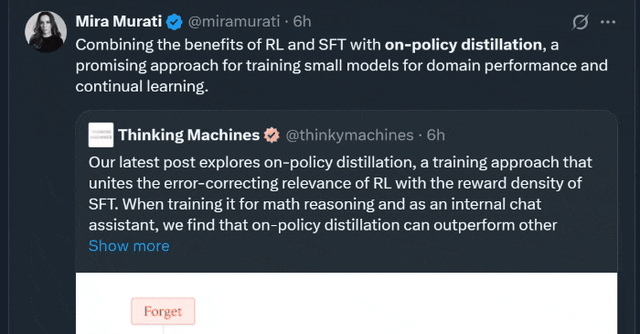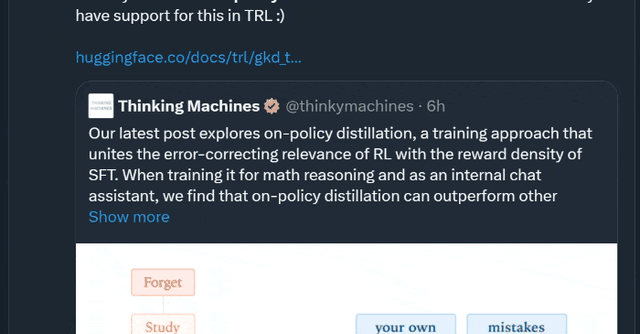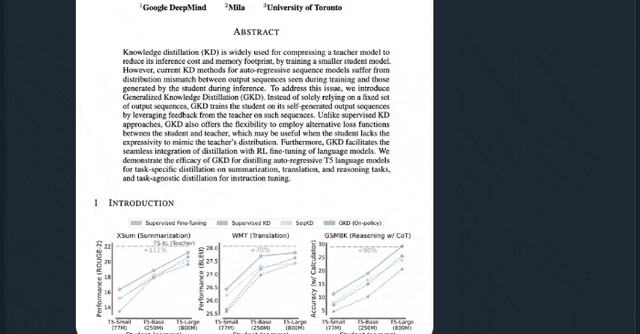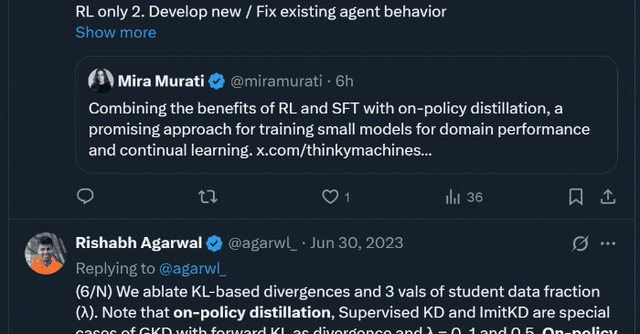
According to Murati’s summary, the team has introduced a new post-training method for Large Language Models (LLMs), designed to make smaller models excel in specialized domains:
On-Policy Distillation.

---
Concept Overview
Traditional Approaches
Two well-known paradigms in AI training:
- Learning by doing (on-policy methods such as reinforcement learning)
- Models explore independently, learning from mistakes — flexible, but resource-intensive.
- Private tutoring (off-policy methods such as supervised fine-tuning)
- Models are fed correct answers — efficient, but prone to rigid thinking.
The “Genius Coach” Analogy
On-Policy Distillation combines both worlds:
Like a genius coach, the model practices by attempting problems, but immediately receives hints and corrections from an expert when it struggles.
---
Key Advantages
- High efficiency:
- In math training, achieves the same performance with 7–10× fewer training steps.
- 50–100× overall efficiency boost vs. traditional methods.
- Enables small teams and independent developers to produce competitive, domain-specific models.
No wonder observers like Weng Li called it:
> "Elegant, truly elegant!"
---
Beyond Efficiency: Structure of Model Development
The paper notes that building strong domain expertise typically involves:
- Pre-training — General language, reasoning, and knowledge.
- Mid-training — Domain-specific data (e.g., code, medical texts).
- Post-training — Refining desired behaviors (instructions, maths, conversation).
This work focuses on the post-training stage.
---
Merging Strengths of Existing Paradigms
Two mainstream post-training styles exist:
- Online / on-policy training — autonomous exploration.
- Offline / off-policy training — guided learning.
On-Policy Distillation integrates the two:
Autonomous exploration + continuous expert guidance.

---
Step-by-Step Method
- Initialize the teacher model
- Choose a strong general or domain-expert model.
- Teacher only computes probabilities (no backprop updates).
- Student generates trajectory
- Attempts problem-solving independently.
- Logs token-level probabilities.
- Teacher scores each step
- Processes the exact student output in context.
- Computes token-level probabilities.
- Calculates divergence per token.
- Use divergence as reward
- The Negative Reverse KL Divergence serves as the reward signal.
---
Understanding Reverse KL Divergence
When student matches teacher perfectly → divergence = 0.
When they differ greatly → large divergence → strong penalty.
Training goal: Minimize KL divergence (maximize alignment with teacher).
Advantages:
- Anti-cheating — Rewards genuine mastery over exploiting loopholes.
- Stable, focused learning — Keeps model aligned to optimal solutions, avoiding drift.
---
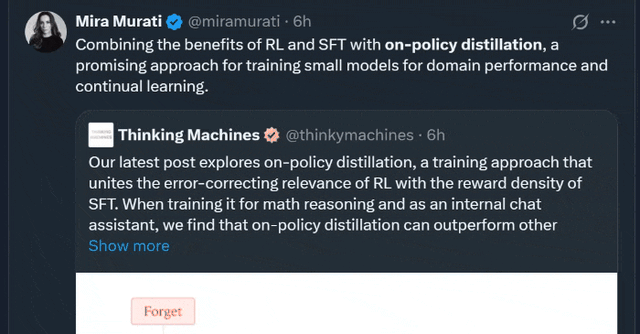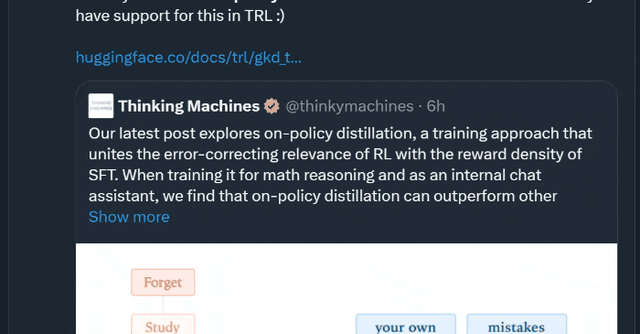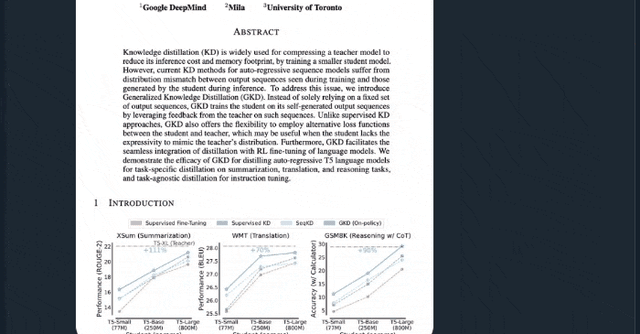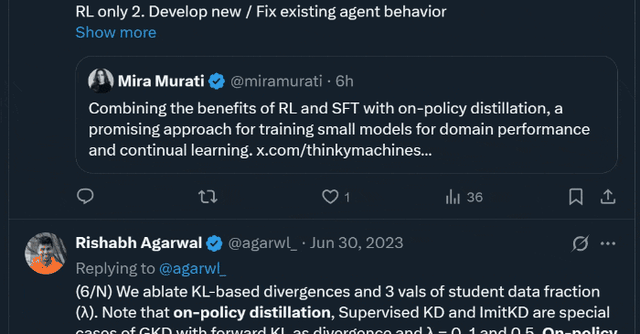
Experimental Validation
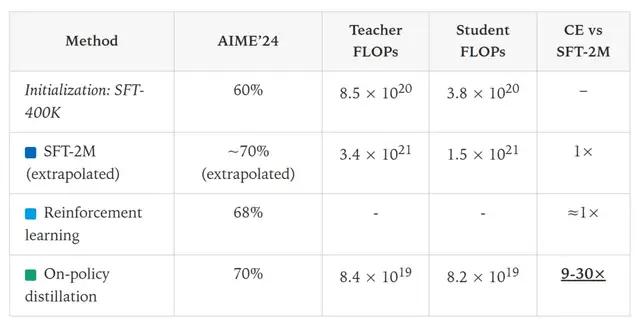
Experiment 1 — Transferring Math Skills
- Teacher: Qwen3-32B
- Student: Qwen3-8B-Base
- Baseline: Score 60 on AIME’24 benchmark after SFT
- Goal: Raise score to 70
Results:
| Method | Cost | Relative Efficiency |
|--------|------|---------------------|
| Continue SFT | ~2M extra samples | Baseline |
| RL (per Qwen3 docs) | 17,920 GPU hours | Similar to SFT |
| On-Policy Distillation | ~150 steps | 9–30× cheaper |
With parallelized teacher probability calculations → ~18× faster wall-clock time.
---
Experiment 2 — Solving Catastrophic Forgetting
Scenario: Injecting domain-specific data (e.g., company documents) often erases general capabilities.
- SFT Results:
- Domain: ↑ from 18% → 43%
- General: ↓ from 85% → 45%
- On-Policy Distillation Repair:
- General: Restored to 83%
- Domain: Maintained/improved to 41%
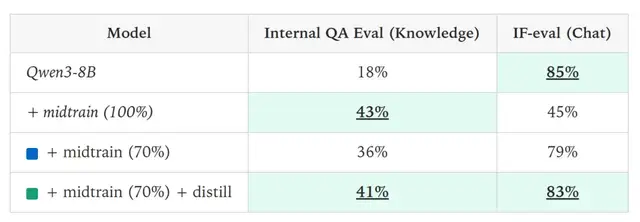
Impact: Allows lifelong learning — preserving old skills while acquiring new ones.
---
Broader Context and Applications

In August, Kevin Lu joined Thinking Machine from OpenAI, where he worked on reinforcement learning, small models, and synthetic data — all directly relevant to this research.
Read the paper:
---
Why It Matters
- Computational efficiency: Achieves improvements with drastically less compute.
- Capability retention: Maintains and recovers skills while learning new tasks.
- Accessibility: Enables small labs, startups, and individuals to train competitive models.
Synergy with Emerging AI Ecosystems
Open-source platforms like AiToEarn enable creators to:
- Generate, publish, and monetize AI content across platforms (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X).
- Integrate training feedback loops, analytics, and distribution.
Pairing such platforms with On-Policy Distillation could yield:
- Faster adaptation to niche domains.
- Retention of general capabilities.
- Greater reach for AI-powered content.
---
> Bottom line: On-Policy Distillation represents a breakthrough in efficient, effective post-training. It has the potential to reshape how AI models are specialized, scaled, and sustained — even with limited compute budgets.


